HA Default system consists of a single master and slave nodes to provide highly available services.

ABOUT
Enterprise Open Source DBMS
CUBRID is an open source DBMS optimized for OLTP. It offers great read and write performance than other database systems. It assures high performance, stability, scalability and high availability which are required for mission-critical applications. In addition, CUBRID provides ease of installation and native GUI-based administration tools for developers' convenience.
We are committed to continuously improve the CUBRID features, the quality and the performance of the engine, drivers, and tools. We have focused on pursuing the best quality for more than 20 years. And we will highly appreciate your contribution on CUBRID project for building a better end-user experience.
Open Source
This means you may freely use it, improve it and distribute it. We expect you to share your knowledge and contribute for further improvement. You can make your own fork or contribute to existing GitHub projects. You may use and improve the existing test cases as well. Feel free to add your own tools and drivers or request new ones for your requirements: the community may already have an answer for you or maybe the development team will include it into the roadmap.
Flexible License
CUBRID uses different licenses for its server engine and its tools/interfaces. The engine has the Apache license 2.0, which allows distribution, modification, and acquisition of the source code. CUBRID APIs and GUI tools have the Berkeley Software Distribution (BSD) license in which there is no obligation of opening derivative works. Adopting two separate license systems provides complete freedom to Independent software vendors (ISV) to develop and distribute CUBRID-based applications.
Enterprise Features
CUBRID provides enterprise-grade features such as High Availability (HA), Hot/Online Backup, and Offline and Incremental Backups, which are all customizable to fit the best of your need. With CUBRID, you get a complete database solution that supports distributed transactions and various replication methods - online, synchronous/asynchronous, one-way, transaction-level, schema independent, and chained or grouped replications.
Major Features
High Availability
CUBRID HA enables OLTP services to be highly available and to balance traffics efficiently. CUBRID HA can be configured with a master node to process Read/Write loads, a slave node to replace the master on failure, and a replica node to distribute Read loads. The following table shows three types of CUBRID HA system.-
HA Default (M:S:R = 1:1:0)
-
HA Extended (M:S:R = 1:N:0)
HA Extended system consists of a single master and N slave nodes for both high availability and load balancing. This type enables server duplication between two data warehouses.
-
HA Load Distributed (M:S:R = 1:1:N)
HA Load Distributed system consists of HA Default nodes as well as multiple replica nodes for distributing read loads. A master in this system uses fewer resources than the one in HA Extended system.
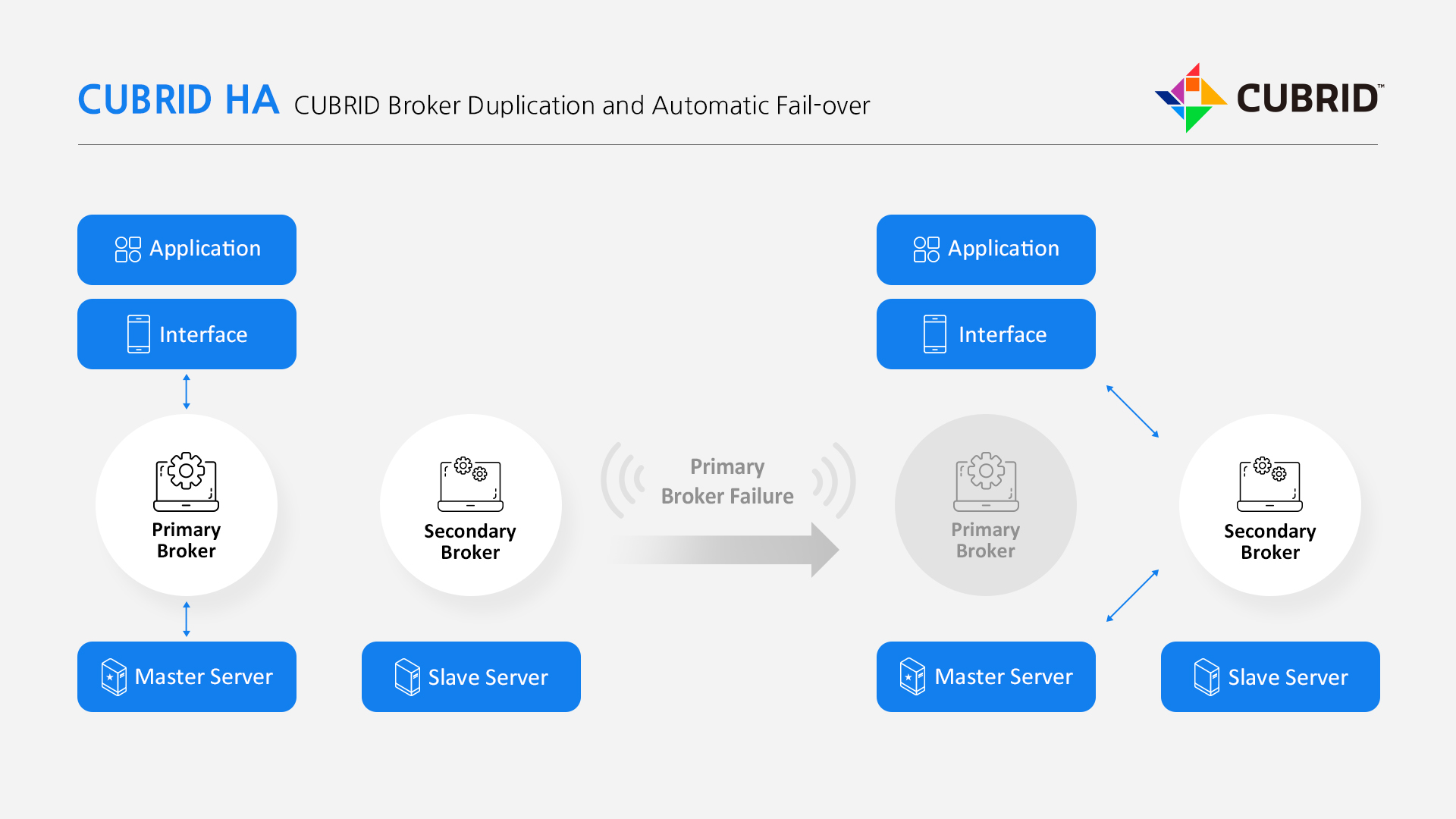
[CUBRID Broker Duplication and Automatic Fail-over]
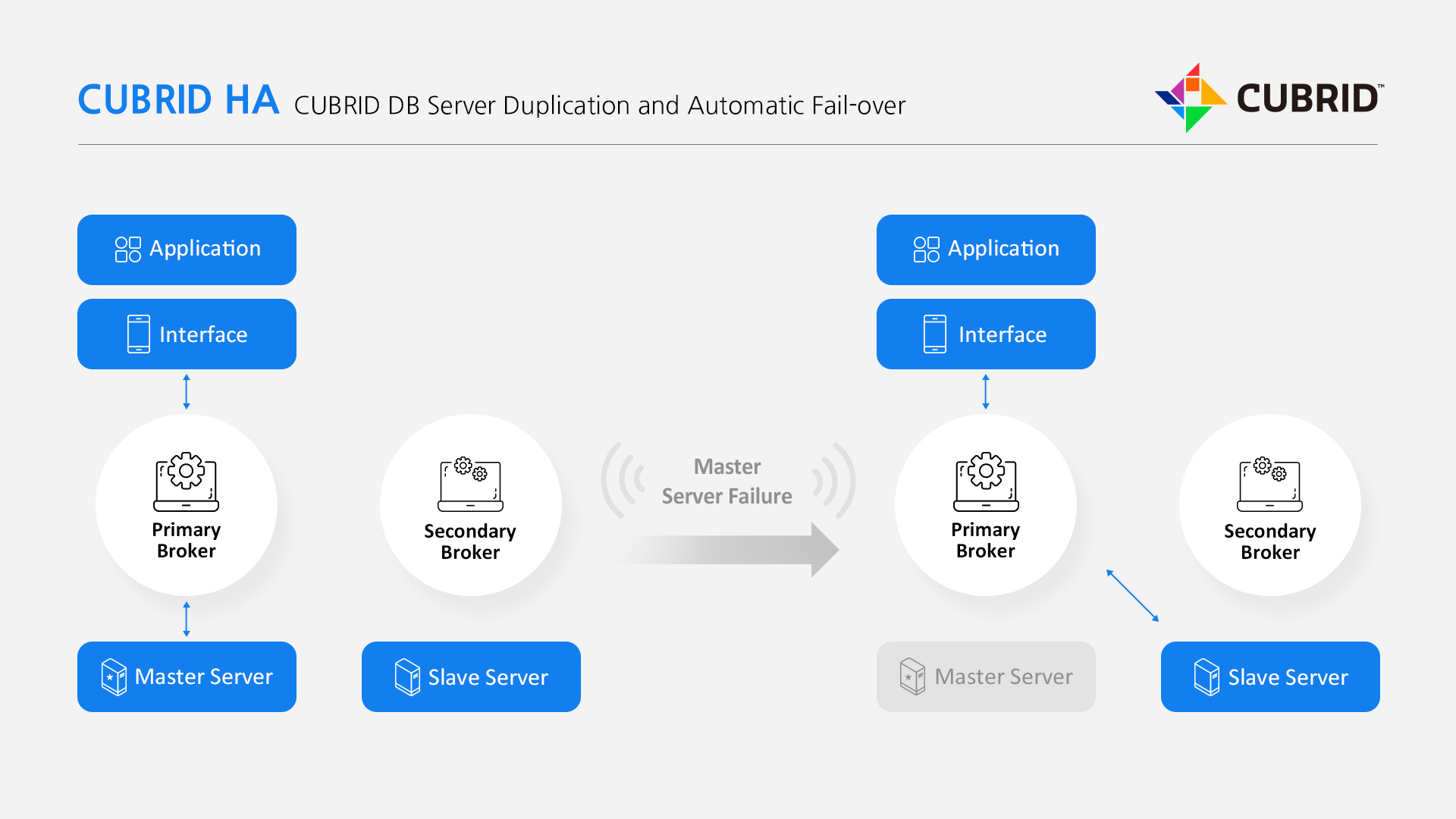
[CUBRID DB Server Duplication and Automatic Fail-over]

License Policy
Unlike other open source DBMS vendors, CUBRID has no commercial license but only an open source license in order to provide cost savings to companies. Because of this unique license policy, customers are not required to open the source code of applications or purchase a commercial license.
CUBRID has a separate license for the server engine and interface. The server engine adopts the Apache license 2.0, which allows distribution, modification, and acquisition of source code. The interface and tools have the BSD license in which there is no obligation of opening derivative works. The reason of adopting two separate license systems is that we do not want to give any limitations to Independent Software Vendors (ISV) for developing and distributing various CUBRID based applications.

Join the CUBRID Project on