
ABOUT
CUBRID 10.2 Release
Faster, Better, Stronger
A fresh version of CUBRID is out and it adds even more features to CUBRID 10.1. It includes new JSON Data Type and native JSON functions, it boosts performance of data and index loading, it protects against I/O partial writes using Double Write Buffer and it went through major code refactoring/modernization.
SQL Extensions
JSON Data Type
CUBRID 10.2 brings native JSON Data Type and JSON Path Expressions, and many more functions and operators to work with JSON data.
- Create JSON Values: JSON_ARRAY, JSON_OBJECT, JSON_QUOTE
- Search JSON Values: JSON_CONTAINS, JSON_CONTAINS_PATH, JSON_EXTRACT, column->path, column->path, JSON_KEYS, JSON_SEARCH
- Modify JSON Values: JSON_ARRAY_APPEND, JSON_ARRAY_INSERT, JSON_INSERT, JSON_MERGE, JSON_MERGE_PATCH, JSON_MERGE_PRESERVE, JSON_REMOVE, JSON_REPLACE, JSON_SET, JSON_UNQUOTE
- JSON Table Function: JSON_TABLE
- JSON Utility Function: JSON_DEPTH, JSON_LENGTH, JSON_PRETTY, JSON_TYPE, JSON_VALID
- JSON Aggregation Function: JSON_ARRAYAGG, JSON_OBJECTAGG
CTE extension
Common Table Expression feature was first added in CUBRID 10.1 and now it is extended for non-SELECT statements:
- Insert, Replace, Update, Delete
- Create Table ... AS SELECT ...
ON Update clause
With the ON Update clause, a column can automatically save the timestamp of the last change on each row.
Performance/Scalability
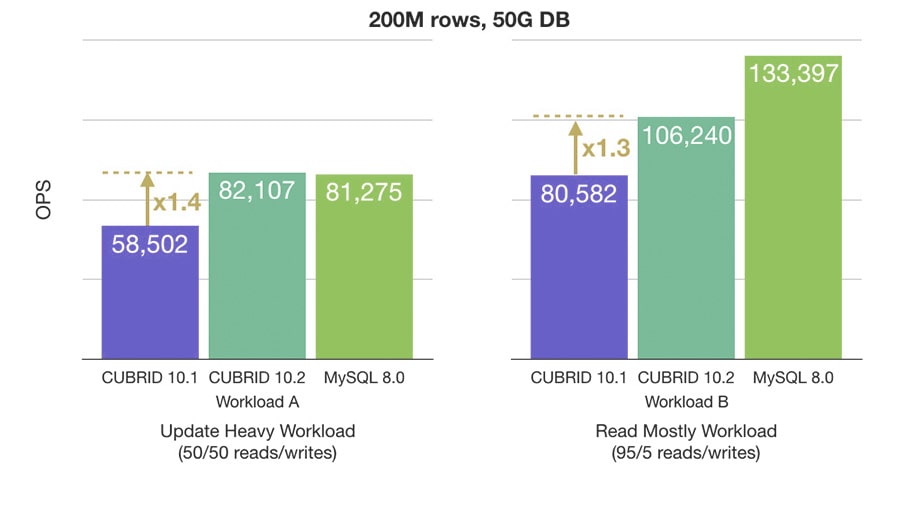
The execution of Auto Commited queries was optimized by reducing the total number of operation and message exchanges between clients and servers. This and other optimizations have improved the throughput of the YCSB Benchmark.
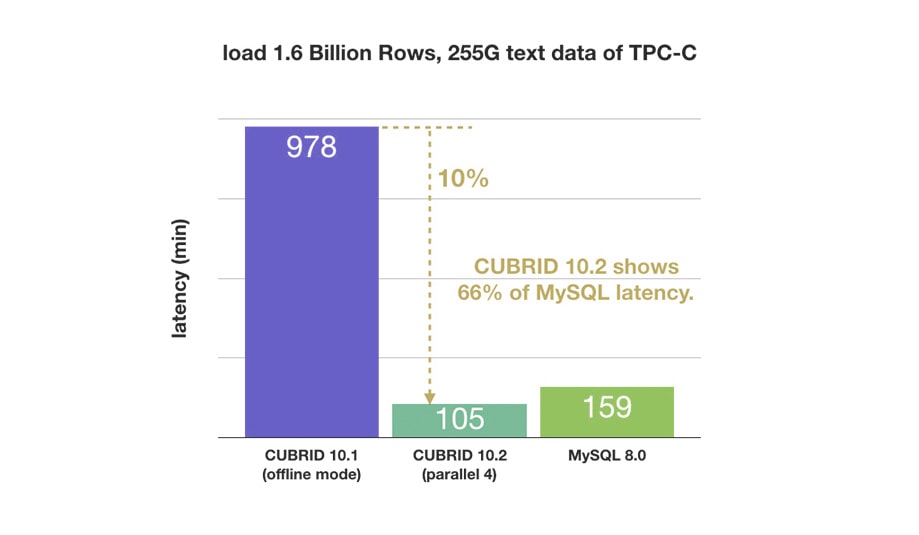
Online Bulk Data Loading
The loaddb utility gains online mode support and it is tuned for maximum performance. Most workload is moved from client to server and is run in parallel.
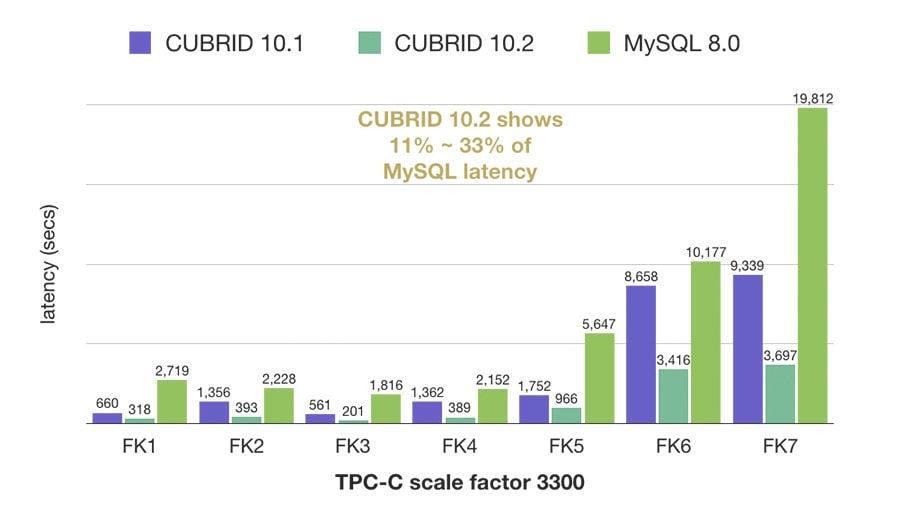
Foreign Key Loading
CUBRID 10.2 closes the performance gap between loading regular secondary indexes and foreign key indexes. The constraint check was redesigned for optimized execution.
Usability
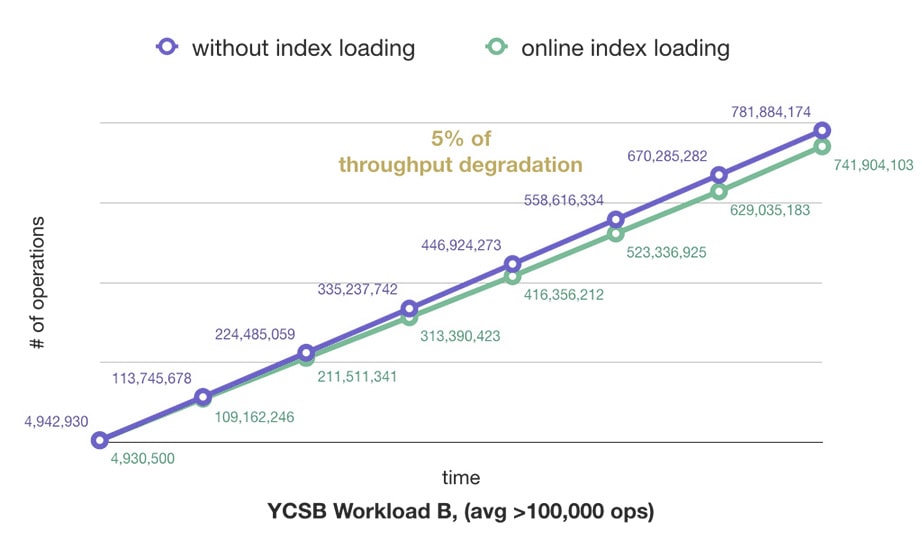
Online Index Loading
Normally, in relational databases, creating an index blocks all read and write operations on the table for the entire duration. The index creation has three phases: preparation, build and final phase. Preparation and final phases read and modify the system tables and table schema. Build phase reads table data and loads the index and takes most of the index creation time and resources. Now, read and write is allowed during index build phases. Moreover, parallel option is provided to quicken the index loading.
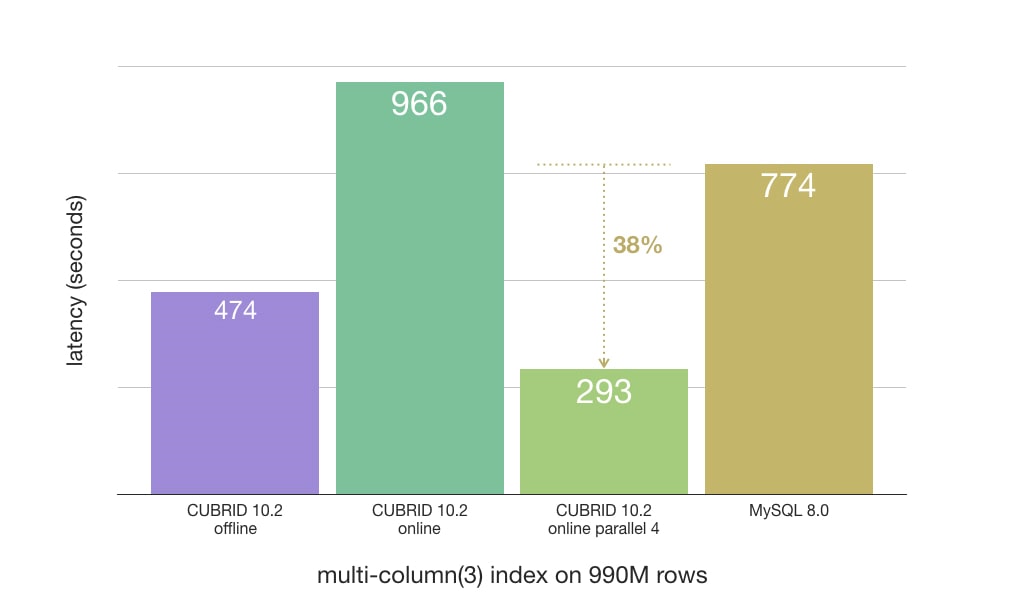
Online index loading was designed to have minimal impact on concurrent transactions.
Invisible Index
Test the effect of removing an index without making a disruptive change. If you doubt the usefulness of an index, set its status to invisible. The query optimizer will exclude it when generating the execution plan, but the index will continue to be maintained. If queries performance is not affected, drop the index and get better DML performance. Making the index visible or invisible is a fast, in-place operation.
Stability
Partial Write Issue
Most disk systems atomically write 4k-size blocks of data. Writing bigger blocks can be interrupted by a crash, corruption data or log page by partial write. CUBRID 10.2 check log page checksum and data page checksum to detect partial writes. Double Write Buffer is used to recover corrupted pages. Although each data page is written to disk twice, DWB is designed so that the I/O impact is minimal. The feature was rigorously tested and passed.
Modernized
CUBRID code is completely recompiled with C++. On project is build with devtoolset-8 (GCC 8.2) on Linux and with VS 2017 on Windows. New features implementation fully exploit the C++ extensions and STL library. Extensive refactoring is done to legacy code, and some of the existing modules have been rewritten (threading system, lock-free structures, vacuum, data type management and more).
Join the CUBRID Project on