Written by Jiwon Kim on 07/07/2021
👍Increase the level of database security by utilizing various security features of CUBRID.
CUBRID 11 has enhanced security by providing the Transparent Data Encryption (henceforth, TDE) feature. So, what is TDE?
TDE means transparently encrypting data from the user’s point of view. This allows users to encrypt data stored on disk with little to no application change.
When a hacker hacks into an organization, the number one thing they want to steal is the important data in the database. Alternatively, there may be a situation where an employee with malicious intention inside the company logs into the database and moves all data to a storage media such as a USB.
The easiest way to protect data in these situations is to encrypt the database. TDE, a technology that encrypts the database file itself among encryption technologies, would be a decent choice for you to protect your data. An encrypted database cannot be accessed without a key, so if you don't have the key file with you, the stolen file will be a useless dummy file.
The TDE feature uses symmetric key algorithms.
👉Symmetric key technique: A technique that encrypts and decrypts data with the same key.
There are two types of symmetric key encryption algorithms provided by CUBRID: AES and ARIA.
- AES: Encryption algorithm established by the National Institute of Standards and Technology (NIST)
- ARIA: Standard encryption algorithm adopted by Korea Internet & Security Agency (KISA)
Keys used for encryption are managed in two levels consisting of master keys and data keys for efficiency. Master keys managed by the user are stored in a separate file, and CUBRID provides a utility to manage it.
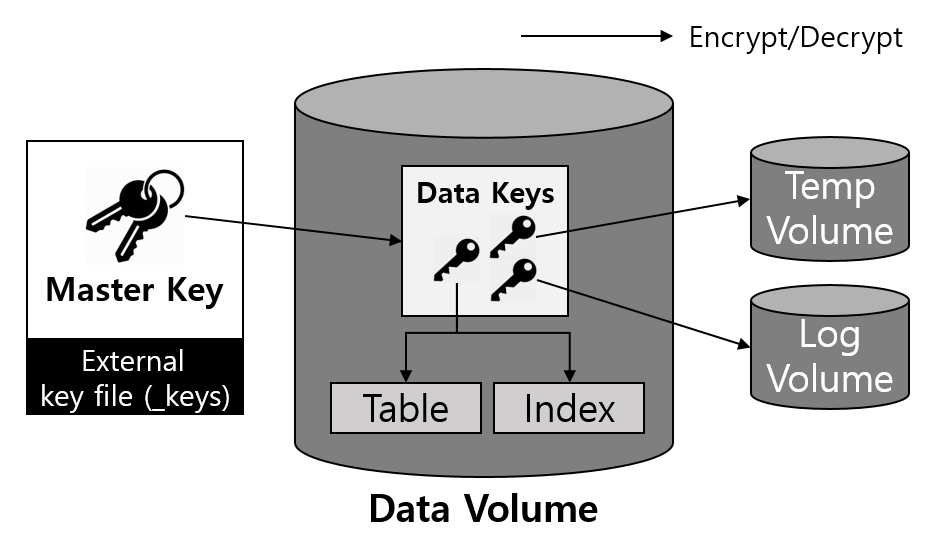
- Master key: A key used when encrypting and decrypting data keys, and it is managed by DBA user.
- Data Key: A key used when encrypting user data such as table and log, and it is managed by CUBRID Engine.
Managing keys in two levels makes it possible to perform the key change operation efficiently. If there is only a key that encrypts the user data, it takes a long time to work when you change the key. All the data that has been encrypted has to be read, decrypted, and re-encrypted. Also, the overall performance of the database may be degraded during this process.
What does CUBRID's TDE encrypt/decrypt?

Encryption Target:
1. Permanent/temporary data volume
- The encrypted table data and all index data created on the table are encrypted
- Temporary data created during queries related to encrypted tables are also encrypted.
2. Transaction log
- Encrypt all log data related to the encrypted tables.
- Encryption is applied to both the active log and the archive log.
3. Backup volume
- If there are encrypted data in data volumes and log volumes, they are also stored as encrypted in backup volumes.
4. DWB (Double Write Buffer)
- Persistent data is temporarily written to the Double Write Buffer (DWB) before being written to the data volume. It may be encrypted even at this time because the data for the encrypted table can be included.
Precautions when using TDE
$ cubrid createdb testdb ko_KR.utf8
Creating database with 512.0M size using locale ko_KR.utf8. The total amount of disk space needed is 1.5G.
CUBRID 11.0
$ ll
total 1050348
drwxrwxr-x. 2 cubrid11 cubrid11 6 april 30 16:01 lob
-rw-------. 1 cubrid11 cubrid11 536870912 april 30 16:01 testdb
-rw-------. 1 cubrid11 cubrid11 65 april 30 16:01 testdb_keys
-rw-------. 1 cubrid11 cubrid11 536870912 april 30 16:01 testdb_lgar_t
-rw-------. 1 cubrid11 cubrid11 536870912 april 30 16:01 testdb_lgat
-rw-------. 1 cubrid11 cubrid11 214 april 30 16:01 testdb_lginf
-rw-------. 1 cubrid11 cubrid11 278 april 30 16:01 testdb_vinf
- tde_keys_file_path
- Set the path to the key file.
- The name of the key file is fixed as [database_name]_keys , and it specifies the directory where the key file exists.
- If this value is not set, locate the key file in the same location as the database volume.
- When changing the key file path, this setting value is not dynamically changed, so the service must be restarted. At this time, if you move only the key file and do not modify the path of the key file, an error stating that the TDE module could not be loaded occurs when accessing the encryption table (DDL, DML).
- tde_default_algorithm
- Specify the default encryption algorithm. (If the algorithm is not specified when creating the TDE encryption table, AES is used by default)
- This default encryption algorithm is used to encrypt logs or temporary data in addition to tables.
3. Situation when the key file is deleted:
If the database is running, there is no problem with the service even if the master key file is deleted because the contents of the master key are loaded into memory, and service is provided. However, this can be problematic as it re-reads the settings when restarted.
csql> SELECT * FROM tbl_tde;
In the command from line 1, ERROR: TDE Module is not loaded.
* HA Environment
In a HA environment, TDE is applied independently to each node (master/slave/replica). This means that for each node, the key file and TDE-related system parameters can be managed independently.
However, since encrypted data is replicated between master/slave, if the TDE module of the slave node is not loaded, the replication will stop when attempting to manipulate an encrypted table from the master node. In this case, not only the changes to a TDE-encrypted table but also any subsequent changes cannot be replicated. Therefore, the settings or key files should remain the same.
* TDE on backup
1.Backup Key File
$ **cubrid backupdb --separate-keys -D . testdb@localhost**
Backup Volume Label: Level: 0, Unit: 0, Database testdb, Backup Time: Wed May 5 23:18:38 2021
$ ll
-rw-------. 1 cubrid11 cubrid11 65 May 5 23:18 testdb_bk0_keys
-rw-------. 1 cubrid11 cubrid11 1614820352 May 5 23:18 testdb_bk0v000
The backup volume contains the key file by default, which can be backed up by separating the keys with the --separate-keys option. The separated backup key file is created in the same directory path as the backup volume and has the name <database_name>_bk<backup_level>_keys. However, in the case of separating the key file, it must be managed carefully to prevent losing the key file for database restore.
2. A key file is required for backup and recovery, and the key file is found in the following order.
The priority of the key file to use for restoring:
1. The backup key file that the backup volume contains.
2. The backup key file created with the \-\-separate-keys option during backup (e.g. testdb_bk0_keys). This key file must exist in the same path as the backup volume.
3. The server key file in the path specified by the tde-keys-file-path system parameter.
4. The server key file in the same path as the data volume (e.g., testdb_keys).
You can specify the key file to be used for recovery through the --keys-file-path option, and an error will occur if the key file does not exist in the path.
Key file classification:
- Server key file: A key file that is generally used when running the server. It can be set with the tde_keys_file_path system parameter or in the default path same as the data volume.
- Backup key file: A key file created during backup included in the backup volume or separated by \-\-separate-keys option.
3. Even if the correct key file is not found, the recovery can be successful if there is no encrypted data on the backup volume. However, since the key file does not exist, subsequent TDE functions cannot be used.
4. Basically, if you lose your backup key file, you cannot perform backup recovery. However, if the key has not been changed, recovery is possible by specifying the backup key file of the old volume with the --keys-file-path option. Also, if the backup key of the old volume exists in the default path, it can be used to restore the backup.
5. When performing restoration using multiple level backup volumes by incremental backup, the backup key file of the level specified by the \-\-level option is used. If the \-\-level option is not specified, the highest level backup key file is used. If only the key file to be used exists, restore can succeed.
* When TDE is unavailable
In the following cases, the TDE feature cannot be used, and an error occurs because the TDE module cannot be loaded correctly.
⛔ ERROR: TDE Module is not loaded.
- When the valid key file cannot be found
- When the key set on the database cannot be found in the key file
Even if the TDE module is not loaded, the server can start normally, and users can access unencrypted tables.
However, the case log data that has been encrypted is different. If the log data is encrypted when the TDE module is not loaded and the log is accessed by recovery, HA, VACUUM, etc., the system cannot be properly executed, and the entire server has no option but to stop running the server.
* TDE Restrictions
In addition to the restrictions described above, there are the following:
1. The replication log is not encrypted in HA.
2. CUBRID does not support the ALTER TABLE statement to change the TDE table option, which means you cannot set TDE to existing tables. If you want to do that, you need to move the data to the new table created with the TDE table option.
3. SQL log is not encrypted.
What other security features does CUBRID support?
SSL
- To prevent sniffing, the act of someone intercepting data in transit over the Internet, CUBRID provides packet encryption.
- For the data to be transmitted, the packet is encrypted and transmitted, and the SSL/TLS protocol is used to encrypt this packet.
- More details can be found in the previous blog: Packet encryption.
ACL
- A function called access control is used to restrict the list of unauthorized IPs and DB users from accessing the corresponding broker or database server. You can protect the database from problems caused by incorrect external access.
Audit Log
- For auditing the developer's or user's DDL log, CUBRID provides the DDL Audit Log.
- DDLs issued through CAS, csql, and loaddb could be recorded in log files in addition to the copy of the files executed if required.
- When the system parameter ddl_audit_log is set to yes, the DDL audit log is created in the $CUBRID/log/ddl_audit directory.
- DDL execution start time, client IP address, user name, etc. are recorded in the file.
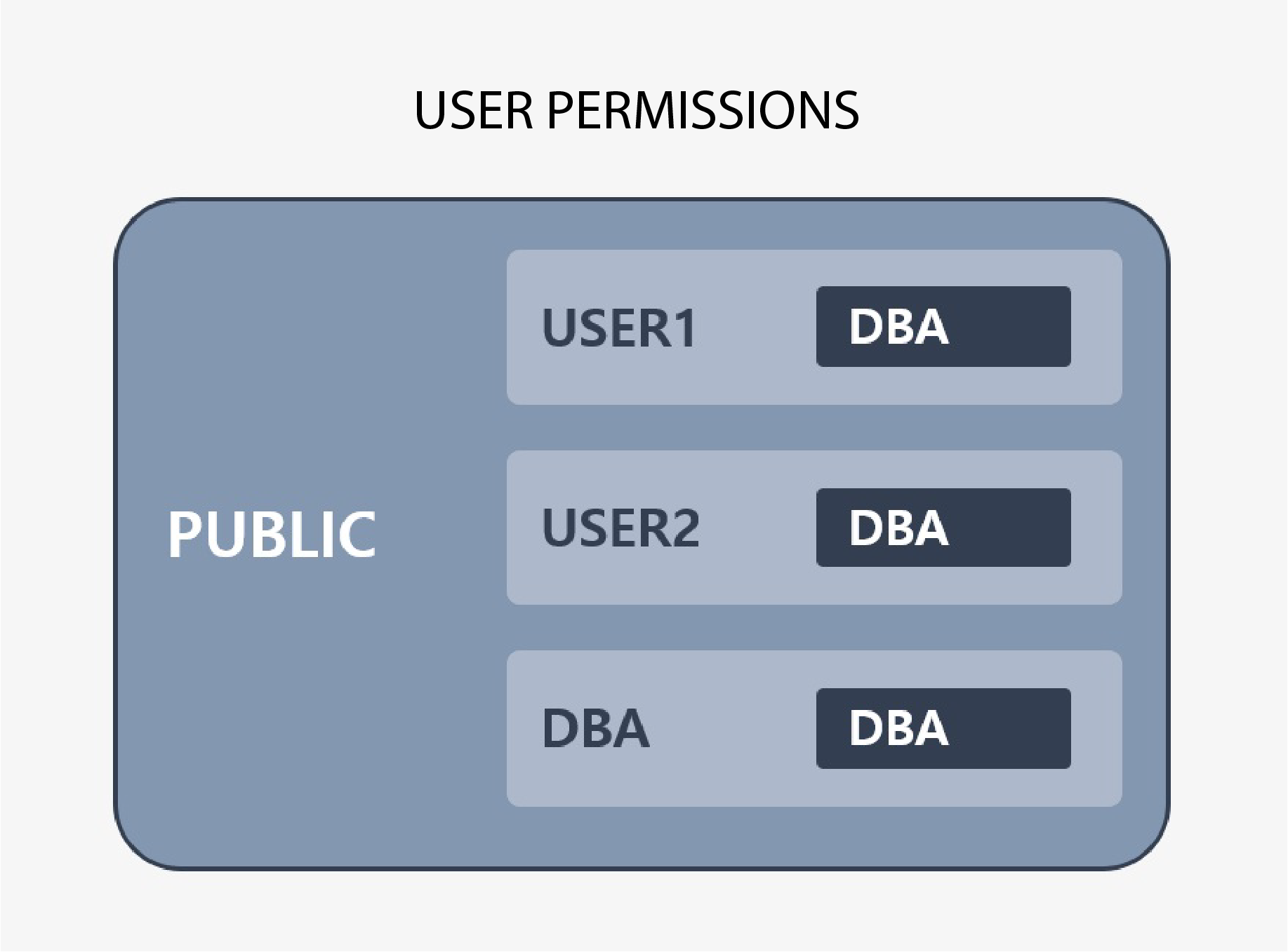
GRANT/REVOKE /owner
- The smallest unit of authorization in CUBRID is a table. You can allow or restrict other users (groups) access to the tables you create by using the GRANT/REVOKE statements appropriately.
- All users have the privileges granted to the PUBLIC user. That is, every user in the database becomes a member of PUBLIC.
- A database administrator (DBA) or member of the DBA group can use the ALTER ... OWNER statement to change the owner of a table, view, trigger, Java stored function/procedure.
For detailed documentation about CUBRID Security, refer to:
 QUERY CACHE Hint
QUERY CACHE Hint
 Understanding JDBC Internals & Timeout Configuration
Understanding JDBC Internals & Timeout Configuration