
BLOG
-
Read More
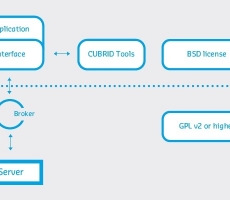
CUBRID License Model
Written by Charis Chau on 06/08/2020 Why Licenses Matter? Open source licenses allow software to be freely used, modified, and shared. Choosing a DBMS with suitable licenses could save the development cost of your application or the Total Cost of Ownership (TCO) for your company. Choosing a DBMS without a proper license, you might find yourself situate in a legal grey area! CUBRID Licenses Unlike other open source DBMS vendors, CUBRID is solely under open source license instead of having a dual license in both commercial license and open source license. Which means that for you, it is not mandatory to purchase a license or annual subscription; company/organizational users can achieve the saving from Total Cost of Ownership (TCO). Since CUBRID has been open source DBMS from 2008,... -
Read More
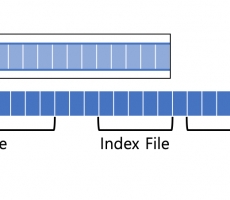
CUBRID Internal: Storage Management (Disk Manager, File Manager)
Written by Jaeeun, Kim on 08/11/2021 Introduction Database, just as its name implies, it needs spaces to store data. CUBRID, the open source DBMS that operates for the operating system allocates as much space as needed from the operating system and uses it efficiently as needed. In this article, we will talk about how CUBRID internally manages the storage to store data in the persistent storage device. Through this article, we hope developers can access the open source database CUBRID more easily. - The content of this article is based on version 10.2.0-7094ba. (However, it seems to be no difference in the latest develop branch, 11.0.0-c83e33. ) CUBRID Storage Management The CUBRID server has multiple modules that operate and manage data complexly and sophisticatedly. Among them, there are ... -
Read More
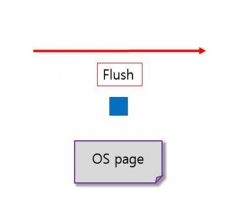
CUBRID INTERNAL: CUBRID Double Write Buffer
Written by MyungGyu Kim on 03/08/2022 INTRODUCTION Data in the database is allocated from disk to memory, some data is read and then modified, and some data is newly created and allocated to memory. Such data should eventually be stored on disk to ensure that it is permanently stored. In this article, we will introduce one of the methods of storing data on disk in CUBRID to help you understand the CUBRID database. The current version at the time of writing is CUBRID 11.2. DOUBLE WRITE BUFFER First of all, I would like to give a general description of the definition, purpose, and mechanism of Double Write Buffer. What is Double Write Buffer? By default, CUBRID stores data on disk through Double Write Buffer. Double Write Buffer is a buffer area composed of both memory and disk. By default, t... -
Read More

CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Subquery Unnest)
Written by SeHun Park on 08/07/2021 What is Subquery A subquery is a query that appears inside another query statement. Subquery enables us to extract the desired data with a single query. For example, if you need to extract information about employees who have salary that is higher than last year’s average salary, you can use the following subquery: It is possible to write a single query as above without writing another query statement to find out the average salary. Subquery like this has various special properties, and their properties vary depending on where they are written. scalar subquery: A subquery in a SELECT clause. Only one piece of data can be viewed. inline view: A subquery in the FROM clause. Multiple data inquiry is possible. subquery: A subquery in the WHERE clause. I... -
Read More
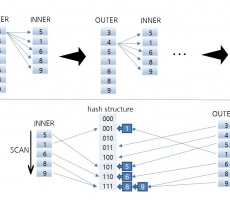
CUBRID INSIDE: HASH SCAN Method
Written by SeHun Park on 11/09/2021 - HASH SCAN Hash Scan is a scan method for hash join. Hash Scan is applied in view or hierarchical query. When a subquery such as view is joined as inner, index scan cannot be used. In this case, performance degradation occurs due to repeated inquiry of a lot of data. In this situation, Hash Scan is used. The picture above shows the difference between Nested Loop join and Hash Scan in the absence of an index. In the case of NL join, the entire data of INNER is scanned as many as the number of rows of OUTER. In contrast, Hash Scan scans INNER data once when building a hash data structure and scans OUTER once when searching. Therefore, you can search for the desired data relatively very quickly. Here, the internal structure of Hash Scan is written as the fl...
Join the CUBRID Project on