
Written by Jaeeun, Kim on 08/11/2021
Introduction
Database, just as its name implies, it needs spaces to store data. CUBRID, the open source DBMS that operates for the operating system allocates as much space as needed from the operating system and uses it efficiently as needed.
In this article, we will talk about how CUBRID internally manages the storage to store data in the persistent storage device. Through this article, we hope developers can access the open source database CUBRID more easily.
- The content of this article is based on version 10.2.0-7094ba. (However, it seems to be no difference in the latest develop branch, 11.0.0-c83e33. )
CUBRID Storage Management
The CUBRID server has multiple modules that operate and manage data complexly and sophisticatedly. Among them, there are Disk Manager and File Manager as modules that manage storage. In order to clarify their roles, it is necessary to know the unit the storage space which is managed in CUBRID first.
Page and Sector
Page
Page is the most basic unit of storage space of CUBRID. A page is a series of consecutive bytes, and the default size is 16KB. When a user creates a volume, it can be set to 8K, 4K, etc. A page is also the basic unit of IO.
Sector
Sector is a bundle of pages and consists of 64 consecutive pages. When managing storage, it is expensive to perform operations in the units of pages ONLY, so a sector that is larger than page is applied.
File and Volume
File
A file is a group of sectors reserved for a specific purpose. A page or sector was simply a physical unit for dividing storage space, whereas a file is a logical unit with a specific purpose. For example, when a user creates a table through the "CREATE TABLE .." statement, a space is required to store the table. At this time, a type of file, heap file, is created. Analogically, if there is a need to store data, such as creating an index or saving query results, a file suitable for that purpose is created. The file referred to here is distinct from the OS file created through the open() system call in the OS. Unless it is stated specifically in tis article, the word file we mention in this article will be defined as this type of CUBRID file.
Volume
A volume is an OS file assigned by the operating system to store data in CUBRID. It refers to the database volume created through utilities such as "cubrid createdb ..".
Page, Sector, File, and Volume
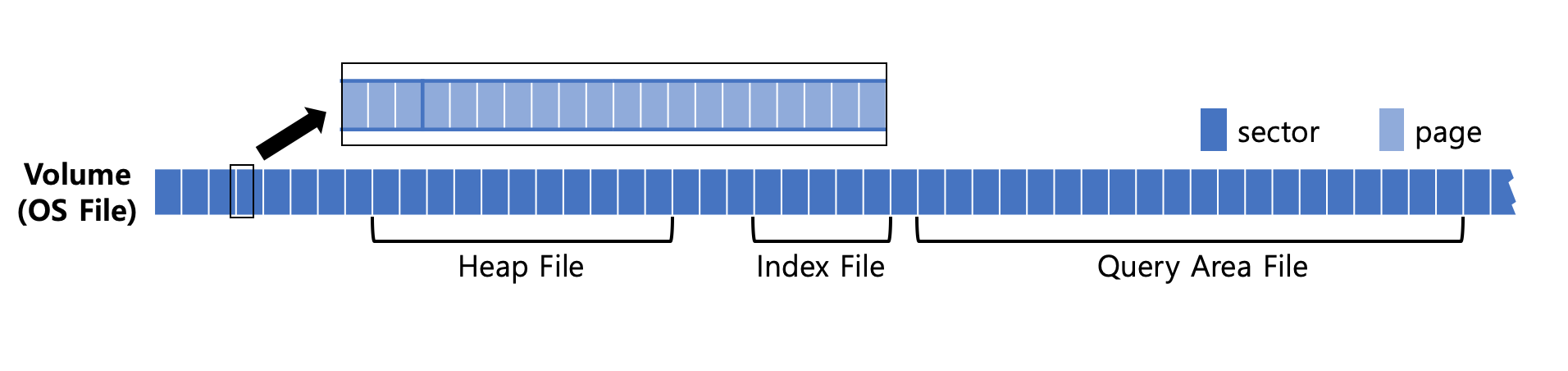
When a user creates a database volume, the CUBRID server divides the volume into sectors and pages as mentioned above and groups them into logical units called files and uses them to store data. If you look at the diagram above, you can see that the volume created as an OS file is divided into several sectors, and depending on the purpose, each sector is bundled and used as a heap file, an index file, etc.
Note
- Here, the volume refers only to the data volume where data is stored, not the log volume.
- Volume, page, and sector are physical units, whereas a file is a logical unit, and if one file continues to grow, it may exist across multiple volumes.
Disk Manager and File Manager
Disk manager and file manager are modules that manage the storage space units. The role of them are stated as follows.
Disk Manager
Manages the entire volume space. When creating a file, it reserves sectors, and if there are insufficient sectors, it plays a role of securing more sectors from the OS.
File Manager
Manage the storage of CUBRID files. When a file requires additional space, it allocates pages among reserved sectors, and when there are no more pages to allocate, it reserves additional sectors from the disk manager.
The following is a schematic diagram of their relationship:
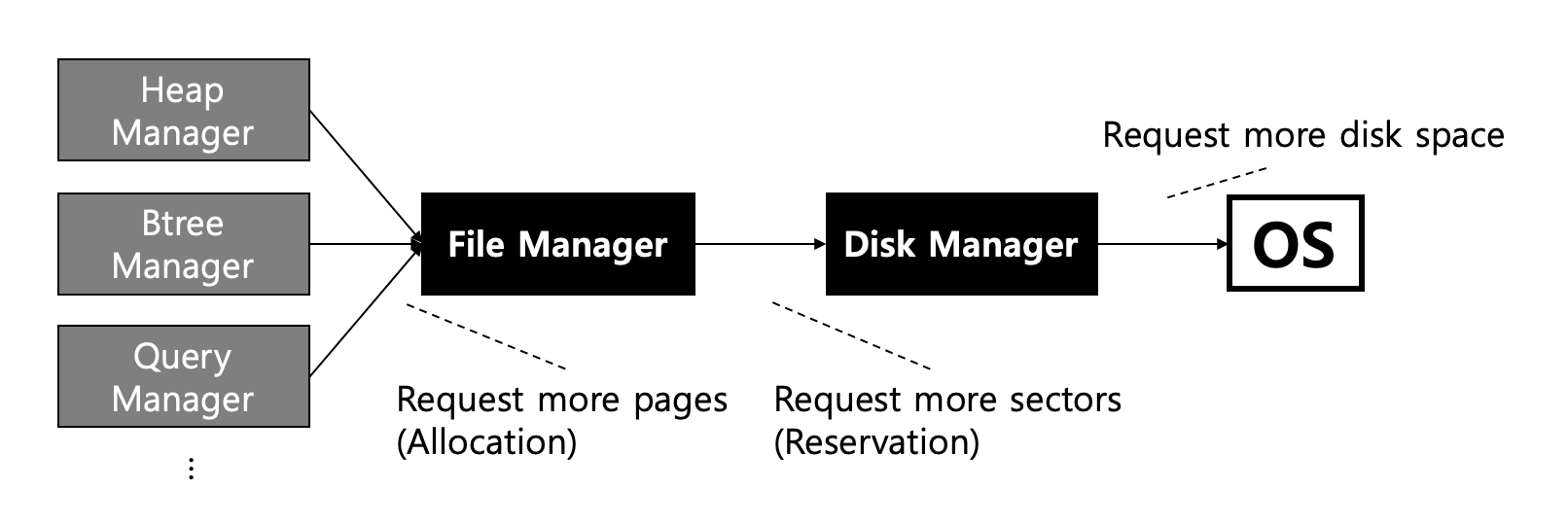
If other modules, such as heap manager and b-tree manager, need space to store data, other modules create files for their purposes and allocate the storage space as needed.
When the file manager secures space for a file, it always secures it in units of sectors and then allocates them internally in units of pages. When a file can no longer allocate pages because all reserved sectors have been used up, the disk manager reserves the sector. When all the storage space in the volume is used up, the disk manager requests additional space from the OS.
Let's take a closer look at how each request is handled below.
What happens if you run out of space in a file?
What happens if all the allocated space is used in a file? For example, an insert operation is executed in the heap file where the records of the table are stored, but there is no more space.
The answer of this situation is "Allocate additional pages." To understand the page allocation process, let's first look at the structure of the file.
A file secures storage from the disk manager in units of sectors, allocates, and uses it whenever necessary in units of page. To do this, File Manager tracks the allocation of sectors reserved for each file with a Partial Sector Table and a Full Sector Table.
- Partial Sector Table: Among reserved sectors, if even one page out of 64 pages of a sector is unallocated, it is registered in this table. Each sector has the following information: (VSID, FILE_ALLOC_BITMAP)
- Full Sector Table: Among reserved sectors, when all pages in a sector are allocated, it is registered in this table. Each sector has the following information: (VSID)
VSID is a sector ID, and FILE_ALLOC_BITMAP is a bitmap indicating whether 64 pages in each sector are allocated. These two tables are saved in the file header page, and as the file grows, additional system pages are allocated to store the table.
The page allocation process is simple. By maintaining the reserved sector information in these two tables (actually, maintaining the information in these two tables is rather complicated), if additional pages are required, the page assignment can be completed by selecting one entry from the partial table and turning on one bit of the bitmap. If there is no entry in the partial sector table, pages of all reserved sectors are allocated and used, so additional sectors must be reserved from the disk manager.
Note
- Page allocation is handled as a System Operation (Top operation). This means that when a page is allocated because additional space is needed during a transaction, the page allocation operation is committed first regardless of the transaction's commit or abort. This allows other transactions to use the allocated pages before the transaction ends (without cacading rollbacks or other processing), increasing concurrency.
- In addition to the two sector tables, a user page table exists in the file header. This is a table for the Numerable property of a file, and it is omitted because it is beyond the scope of this article.
- Since the size of a file can theoretically grow infinitely, the size of the sector table must be able to keep growing so that it can be tracked. For this purpose, CUBRID has a data structure called File Extendible Data to store a data set of variable size consisting of several pages.
What if there are no more pages to allocate in a file?
If pages of all reserved sectors are used in a file, additional sectors must be reserved. Before looking at how sector reservations are made, let's take a look at the structure of the volume. The following is a schematic diagram of the structure of the volume.

The system page includes the volume header, sector table of the volume, and the remaining user pages. The sector table, like the partial sector table of a file, holds a bitmap, whether sectors in the volume are reserved nor not.
By referring to the page allocation process, you can easily guess the sector reservation process. It checks the bitmap of the sector table and turns on the bit of the unreserved sector. Although this is basically how the process is, the sector reservation should be determined by referring to the sector tables of multiple volumes; and in the process, the disk cache (DISK_CACHE) is performed in two steps as follow for increased efficiency and concurrency.
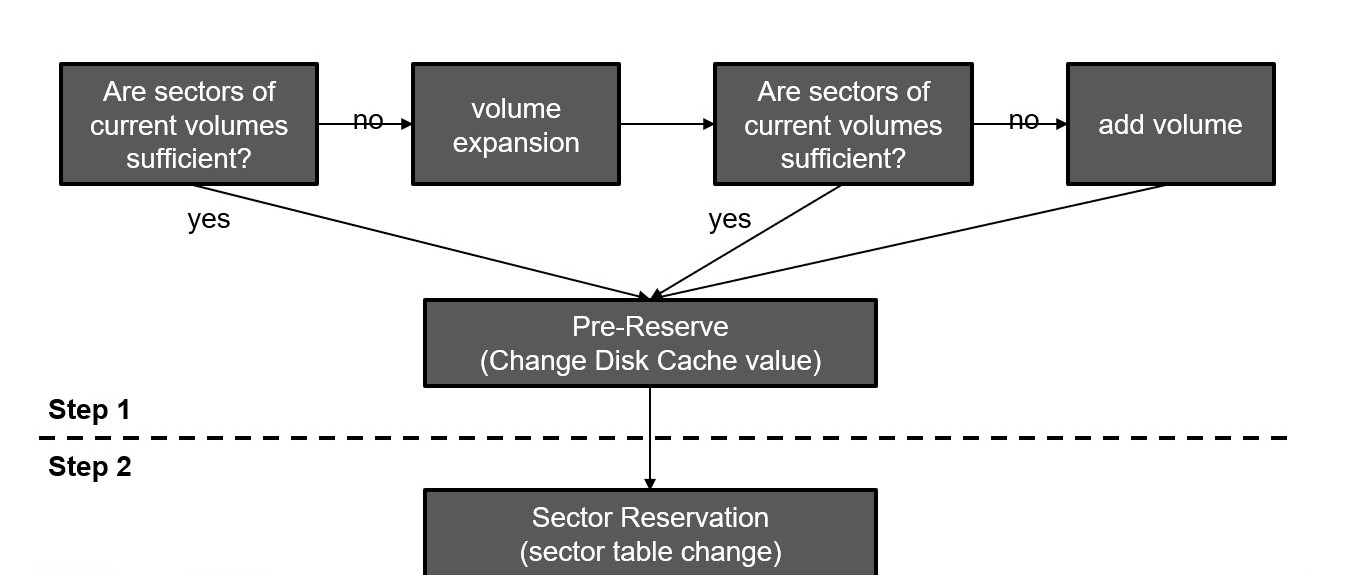
Step 1: Pre-Reserve (Change Disk Cache value)
Step 2: Turn on the reserved bit while traversing the sector tables of the actual volumes based on the decision of the pre-reservation.
As shown in the figure, if all sectors of the volume itself are exhausted in step 1, the volume is expanded according to the system parameter, and a new volume is added after expanding to the maximum size.
The disk cache has pre-calculated values necessary for reservation based on sector reservation information of all volumes. For example, since the number of available sectors of each volume is based on information in the sector tables, it is possible to determine whether reservation is possible in the current volume or whether the volume needs to be extended directly from the current volume.
What if the space is no longer needed?
What if the reserved sectors and allocated pages are no longer needed? Of course, we need to return the space so that other data can be stored. The return process basically turns off the bits in the sector table as opposed to turning them on during the reservation or allocation process and reorganizes the sector tables according to the rules.
The timing of returning the actual space depends on the policy of the module using pages and sectors. For example, in the case of a heap file, the page is not returned immediately even if all data is deleted. In order to return a page of the heap file, it is not when all records in the page are deleted, but it is when the heap manager determines that data is no longer needed according to the operation of MVCC and Vacuum. In addition, in the case of temporary files, the end of the query does not immediately return the space of the temporary files used during the query because the files are recycled for other purposes rather than being removed immediately according to the policy.
Space return is performed by postponing operation (Deferred Database Modification). That is, even if space is returned during a transaction, the return is not processed until the time of commit.
Temporary Purpose Data
The foregoing is the case of data for persistent purposes. Data for temporary purposes is handled slightly differently. These differences are briefly summarized here. Before that, let's first classify the data clearly and talk about the types of volumes. Data can be broadly classified into two categories:
- Persistent purpose data: Permanent purpose data is data that must be permanently preserved and must maintain an intact state even if a failure occurs while the database is running. For example, the heap file that stores table records and the b-tree file that stores indexes are files that store permanent data.
- Temporary purpose data:Temporary purpose data is data that is temporarily stored according to query execution, and all data becomes meaningless when the database is restarted. For example, there are temporary files written to disk due to insufficient memory while storing query results or temporary files created during External Sorting.
As you can see above, the biggest difference of permanent purpose data and temporary purpose data is whether the data should be kept even when the database is shut down, which, in another word, whether logging for recovery is necessary in CUBRID that follows ARIES. In the case of a permanent file, logging is always performed when data in the permanent file is changed, while in the case of a temporary file, logging is not performed. Additionally, temporary purpose data does not need to be maintained at restart time, which simplifies operations on multiple file operations.
Temporary purpose data and volumes
There are two types of data volume, permanent and temporary. The diagram below shows which data is stored in which volume according to the purpose of the data.
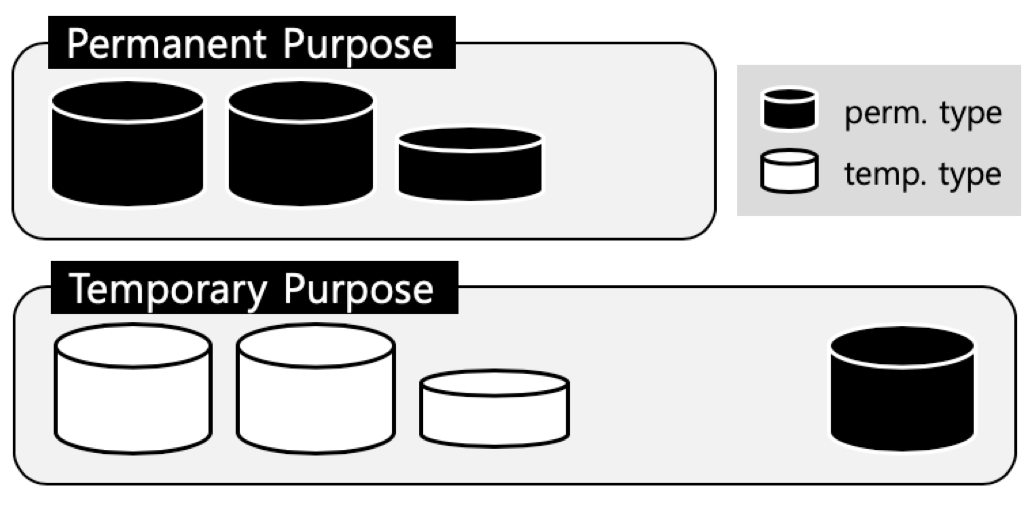
In the case of persistent data, it is stored only in the persistent type volume. On the other hand, data for temporary purposes can be stored in both temporary type and permanent type volumes. This is because the user can directly add a volume for temporary data to prevent the OS from creating and formatting a new volume whenever temporary data is saved (cubrid createdb -p temp). When creating a file of temporary purpose data, the user first looks for a persistent purpose volume created, and if there is none, a volume of the temporary type is created. Temporary type volumes are all removed when the database is restarted, and all internal files of temporary type permanent volumes are also destroyed when restarting.
Temporary purpose data and files
Files contain temporary purpose data (hereafter temporary files) are simpler to manage than files contains permanent purpose data. Temporary files are mainly used to temporarily store query results or intermediate results when a large amount of data is accessed during query execution. Since these are files to be removed anyway, the overhead for management can be reduced, and the operation itself must be fast because it is a file that is frequently created/removed in a shorter cycle than a permanent file. The difference is:
- No logging.
- Do not return pages.
- Reuse files without destroying them even if they are used up.
- Use only one type of sector table.
Since it is data that is not needed when restarted, it is basic not to log the data, and even if the data in the page is no longer used, the page is not returned separately.
The file is also not immediately destroyed, but a certain number of temporary files are cached according to the system parameters, and then the temporary files are reused if necessary. Since the temporary file is cleared only when the cache is full, it can be seen that the disk space used for temporary purpose data during the query is not returned immediately after the query is completed.
The sector table we looked at in the page allocation process of persistent files is to quickly find pages that are not allocated in situations where page allocation and return are repeated, and in the case of temporary files, only one table in the form of a partial sector table is used for temporary files. If all pages within a sector are allocated, they are not moved to the full sector table. It is simply used to track the reserved sectors, and which pages they have reserved within them.
Other than that, the operation of the disk manager and the file manager described above follows the basic procedure we mentioned above.
Reference
1. CUBRID Manual - https://www.cubrid.org/manual/en/10.2/
2. CUBRID Source Code - https://github.com/CUBRID/cubrid
3. Mohan, Chandrasekaran, et al. "ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging." ACM Transactions on Database Systems (TODS) 17.1 (1992): 94-162.
4. Liskov, Barbara, and Robert Scheifler. "Guardians and actions: Linguistic support for robust, distributed programs." ACM Transactions on Programming Languages and Systems (TOPLAS) 5.3 (1983): 381-404.
5. Silberschatz, Abraham, Henry F. Korth, and Shashank Sudarshan. Database system concepts. Vol. 5. New York: McGraw-Hill, 1997.