CUBRID 프로세스 제어¶
cubrid 유틸리티를 통해서 CUBRID 프로세스들을 제어할 수 있다.
CUBRID 서비스 제어¶
CUBRID 설정 파일에 등록된 서비스를 제어하기 위한 cubrid 유틸리티 구문은 다음과 같다. command 에 올 수 있는 명령어는 서비스 구동을 위한 start, 종료를 위한 stop, 재시작을 위한 restart, 상태 확인을 위한 status 중 하나이며, 추가로 입력해야 할 옵션이나 인수는 없다.
cubrid service <command>
<command>: {start|stop|restart|status}
데이터베이스 서버 제어¶
데이터베이스 서버 프로세스를 제어하기 위한 cubrid 유틸리티 구문은 다음과 같다. <command>에 올 수 있는 명령어는 서버 프로세스 구동을 위한 start, 종료를 위한 stop, 재시작을 위한 restart, 상태 확인을 위한 status가 있으며, status를 제외한 명령어에는 데이터베이스 이름이 인수로 지정되어야 한다.
cubrid server <command> [database_name]
<command>: {start|stop|restart|status}
브로커 제어¶
CUBRID 브로커 프로세스를 제어하기 위한 cubrid 유틸리티 구문은 다음과 같다. <command>로 올 수 있는 명령어는 브로커 프로세스 구동을 위한 start, 종료를 위한 stop, 재시작을 위한 restart, 상태 확인을 위한 status 가 있으며, 특정 브로커 구동을 위한 on, 종료를 위한 off 가 있다.
cubrid broker <command>
<command>: {start|stop|restart|status [broker_name]
|info
|on broker_name |off broker_name
|reset broker_name |acl {status|reload} broker_name }
CUBRID 매니저 서버 제어¶
CUBRID 매니저를 사용하기 위해서는 데이터베이스 서버가 실행된 곳에 매니저 서버가 실행되어야 한다. CUBRID 매니저 프로세스를 제어하기 위한 cubrid 유틸리티 구문은 다음과 같다. <command>로 올 수 있는 명령어는 매니저 서버 프로세스 구동을 위한 start, 종료를 위한 stop, 상태 확인을 위한 status 가 있다.
cubrid manager <command>
<command>: {start|stop|status}
CUBRID HA 제어¶
CUBRID HA 기능을 사용하기 위한 cubrid heartbeat 유틸리티 구문은 다음과 같다. <command>로 올 수 있는 명령어는 HA 관련 프로세스 구동을 위한 start, 종료를 위한 stop, HA 구성정보를 다시 읽어서 새로운 구성에 맞게 실행하기 위한 reload, CUBRID HA 그룹에서 노드를 제외하기 위한 deact, 그룹에서 빠진 노드를 다시 포함시키기 위한 act, copylogdb 또는 applylogdb 프로세스를 일시 정지하기 위한 deregister, HA 상태 정보를 확인하기 위한 status가 있다. 자세한 내용은 cubrid heartbeat 유틸리티 를 참고한다.
cubrid heartbeat <command>
<command>: {start|stop|reload|deact|deregister|act|status}
CUBRID SHARD 제어¶
CUBRID SHARD 기능을 사용하기 위한 cubrid shard 유틸리티 구문은 다음과 같다. <command>로 올 수 있는 명령어는 SHARD 관련 프로세스 구동을 위한 start, 종료를 위한 stop, SHARD 설정 정보를 확인하기 위한 info, 특정 키가 어느 샤드 DB에 속하는지 알고 싶을 때 사용하는 getid, SHARD의 상태를 모니터링하기 위한 status 가 있다. 자세한 내용은 구동 및 모니터링을 참고한다.
cubrid shard <command>
<command>: {start|stop|info|getid|status}
CUBRID 서비스¶
서비스 등록¶
사용자는 임의로 데이터베이스 서버, CUBRID 브로커, CUBRID 매니저, CUBRID HA 또는 CUBRID SHARD를 데이터베이스 환경 설정 파일(cubrid.conf)에 CUBRID 서비스로 등록할 수 있다. 이를 위해 cubrid.conf의 service 파라미터 값으로 각각 server, broker, manager, heartbeat, shard를 입력하면 되며, 이들을 쉼표(,)로 구분하여 여러 개를 같이 등록할 수 있다.
사용자가 별도로 서비스를 등록하지 않으면, 기본적으로 마스터 프로세스(cub_master)만 등록된다. CUBRID 서비스에 등록되어 있으면 cubrid service 유틸리티를 사용해서 한 번에 관련된 프로세스들을 모두 구동, 정지하거나 상태를 알아볼 수 있어 편리하다.
CUBRID HA를 설정하는 방법은 cubrid service에 HA 등록을 참고하고, CUBRID SHARD를 설정하는 방법은 cubrid service에 SHARD 등록을 참고한다.
다음은 데이터베이스 환경 설정 파일에서 데이터베이스 서버와 브로커를 서비스로 등록하고, CUBRID 서비스 구동과 함께 demodb와 testdb라는 데이터베이스를 자동으로 시작하도록 설정한 예이다.
# cubrid.conf
…
[service]
# The list of processes to be started automatically by 'cubrid service start' command
# Any combinations are available with server, broker, manager and heartbeat.
service=server,broker
# The list of database servers in all by 'cubrid service start' command.
# This property is effective only when the above 'service' property contains 'server' keyword.
server=demodb,testdb
서비스 구동¶
Linux 환경에서는 CUBRID 설치 후 CUBRID 서비스 구동을 위해 아래와 같이 입력한다. 데이터베이스 환경 설정 파일에서 서비스를 등록하지 않으면 기본적으로 마스터 프로세스(cub_master)만 구동된다.
Windows 환경에서는 시스템 권한을 가진 사용자로 로그인한 경우에만 아래의 명령이 정상 수행된다. 관리자 또는 일반 사용자는 CUBRID 매니저 설치 후 작업 표시줄에 생성되는 CUBRID 서비스 트레이 아이콘을 클릭하여 CUBRID Server를 구동 또는 정지할 수 있다.
% cubrid service start
@ cubrid master start
++ cubrid master start: success
이미 마스터 프로세스가 구동 중이라면 다음과 같은 메시지가 표시된다.
% cubrid service start
@ cubrid master start
++ cubrid master is running.
마스터 프로세스의 구동에 실패한 경우라면 다음과 같은 메시지가 표시된다. 다음은 데이터베이스 환경 설정 파일(cubrid.conf)에 설정된 cubrid_port_id 파라미터 값이 충돌하여 구동에 실패한 예이다. 이런 경우에는 해당 포트를 변경하여 충돌 문제를 해결할 수 있다. 해당 포트를 점유하고 있는 프로세스가 없는데도 구동에 실패한다면 /tmp/CUBRID1523 파일을 삭제한 후 재시작한다.
% cubrid service start
@ cubrid master start
cub_master: '/tmp/CUBRID1523' file for UNIX domain socket exist.... Operation not permitted
++ cubrid master start: fail
CUBRID 서비스 에 설명된 대로 서비스를 등록한 후, 서비스를 구동하기 위해 다음과 같이 입력한다. 마스터 프로세스, 데이터베이스 서버 프로세스, 브로커 및 등록된 demodb, testdb 가 한 번에 구동됨을 확인할 수 있다.
% cubrid service start
@ cubrid master start
++ cubrid master start: success
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4
++ cubrid server start: success
@ cubrid server start: testdb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4
++ cubrid server start: success
@ cubrid broker start
++ cubrid broker start: success
서비스 종료¶
CUBRID 서비스를 종료하려면 다음과 같이 입력한다. 사용자에 의해 등록된 서비스가 없는 경우, 마스터 프로세스만 종료된다.
% cubrid service stop
@ cubrid master stop
++ cubrid master stop: success
등록된 CUBRID 서비스를 종료하려면 다음과 같이 입력한다. demodb, testdb는 물론, 서버 프로세스, 브로커 프로세스, 마스터 프로세스가 모두 종료됨을 확인할 수 있다.
% cubrid service stop
@ cubrid server stop: demodb
Server demodb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
@ cubrid server stop: testdb
Server testdb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
@ cubrid broker stop
++ cubrid broker stop: success
@ cubrid master stop
++ cubrid master stop: success
서비스 재구동¶
CUBRID 서비스를 재구동하려면 다음과 같이 입력한다. 사용자에 의해 등록된 서비스가 없는 경우, 마스터 프로세스만 종료 후 재구동된다.
% cubrid service restart
@ cubrid master stop
++ cubrid master stop: success
@ cubrid master start
++ cubrid master start: success
등록된 CUBRID 서비스를 다음과 같이 입력한다. demodb, testdb 는 물론, 서버 프로세스, 브로커 프로세스, 마스터 프로세스가 모두 종료된 후 재구동되는 것을 확인할 수 있다.
% cubrid service restart
@ cubrid server stop: demodb
Server demodb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
@ cubrid server stop: testdb
Server testdb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
@ cubrid broker stop
++ cubrid broker stop: success
@ cubrid master stop
++ cubrid master stop: success
@ cubrid master start
++ cubrid master start: success
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4……
++ cubrid server start: success
@ cubrid server start: testdb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4……
++ cubrid server start: success
@ cubrid broker start
++ cubrid broker start: success
서비스 상태 관리¶
등록된 마스터 프로세스, 데이터베이스 서버의 상태를 확인하기 위하여 다음과 같이 입력한다.
% cubrid service status
@ cubrid master status
++ cubrid master is running.
@ cubrid server status
Server testdb (rel 8.4, pid 31059)
Server demodb (rel 8.4, pid 30950)
@ cubrid broker status
% query_editor
----------------------------------------
ID PID QPS LQS PSIZE STATUS
----------------------------------------
1 15465 0 0 48032 IDLE
2 15466 0 0 48036 IDLE
3 15467 0 0 48036 IDLE
4 15468 0 0 48036 IDLE
5 15469 0 0 48032 IDLE
% broker1 OFF
@ cubrid manager server status
++ cubrid manager server is not running.
만약, 마스터 프로세스가 중지된 상태라면, 다음과 같은 메시지가 출력된다.
% cubrid service status
@ cubrid master status
++ cubrid master is not running.
데이터베이스 서버¶
데이터베이스 서버 구동¶
demodb 서버를 구동하기 위하여 다음과 같이 입력한다.
% cubrid server start demodb
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4
++ cubrid server start: success
마스터 프로세스가 중지된 상태에서 demodb 서버를 시작하면 다음과 같이 자동으로 마스터 프로세스를 구동한 후 지정된 데이터베이스 서버를 구동한다.
% cubrid server start demodb
@ cubrid master start
++ cubrid master start: success
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4
++ cubrid server start: success
이미 demodb 서버가 구동 중인 상태라면 다음과 같은 메시지가 출력된다.
% cubrid server start demodb
@ cubrid server start: demodb
++ cubrid server 'demodb' is running.
cubrid server start 명령은 HA 모드의 설정과는 상관없이 특정 데이터베이스의 cub_server 프로세스만 구동한다. HA 환경에서 데이터베이스를 구동하려면 cubrid heartbeat start 를 사용해야 한다.
데이터베이스 서버 종료¶
demodb 서버 구동을 종료하기 위하여 다음과 같이 입력한다.
% cubrid server stop demodb
@ cubrid server stop: demodb
Server demodb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
이미 demodb 서버가 종료된 상태라면, 다음과 같은 메시지가 출력된다.
% cubrid server stop demodb
@ cubrid server stop: demodb
++ cubrid server 'demodb' is not running.
cubrid server stop 명령은 HA 모드의 설정과는 상관없이 특정 데이터베이스의 cub_server 프로세스만 종료하며, 데이터베이스 서버가 재시작되거나 failover가 일어나지 않으므로 주의해야 한다. HA 환경에서 데이터베이스를 중지하려면 cubrid heartbeat stop 를 사용해야 한다.
데이터베이스 서버 재구동¶
demodb 서버를 재구동하기 위하여 다음과 같이 입력한다. 이미 구동 중인 demodb 서버를 중지시킨 후 재구동하는 것을 알 수 있다.
% cubrid server restart demodb
@ cubrid server stop: demodb
Server demodb notified of shutdown.
This may take several minutes. Please wait.
++ cubrid server stop: success
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 8.4
++ cubrid server start: success
데이터베이스 상태 확인¶
데이터베이스 서버의 상태를 확인하기 위하여 다음과 같이 입력한다. 구동 중인 모든 데이터베이스 서버의 이름이 표시된다.
% cubrid server status
@ cubrid server status
Server testdb (rel 8.4, pid 24465)
Server demodb (rel 8.4, pid 24342)
마스터 프로세스가 중지된 상태라면, 다음과 같은 메시지가 출력된다.
% cubrid server status
@ cubrid server status
++ cubrid master is not running.
데이터베이스 서버 접속 제한¶
데이터베이스 서버에 접속하는 브로커 및 CSQL 인터프리터를 제한하려면 cubrid.conf 의 access_ip_control 파라미터 값을 yes로 설정하고, access_ip_control_file 파라미터 값에 접속을 허용하는 IP 목록을 작성한 파일 경로를 입력한다. 파일 경로는 절대 경로로 입력하며, 상대 경로로 입력하면 Linux에서는 $CUBRID/conf 이하, Windows에서는 %CUBRID%\conf 이하의 위치에서 파일을 찾는다.
cubrid.conf 파일에는 다음과 같이 설정한다.
# cubrid.conf
access_ip_control=yes
access_ip_control_file="/home1/cubrid1/CUBRID/db.access"
access_ip_control_file 파일의 작성 형식은 다음과 같다.
[@<db_name>]
<ip_addr>
…
- <db_name>: 접근을 허용할 데이터베이스 이름.
- <ip_addr>: 접근을 허용할 IP 주소. 뒷자리를 *로 입력하면 뒷자리의 모든 IP를 허용한다. 하나의 데이터베이스 이름 다음 줄에 여러 줄의 <ip_addr>을 추가할 수 있다.
여러 개의 데이터베이스에 대해 설정하기 위해 [@<db_name>]과 <ip_addr>을 추가로 지정할 수 있다.
access_ip_control 이 yes인 상태에서 access_ip_control_file 이 설정되지 않으면, 서버는 모든 IP를 차단하고 localhost만 접속을 허용한다. 서버 구동 시 잘못된 형식으로 인해 access_ip_control_file 분석에 실패하면 서버는 구동되지 않는다.
다음은 access_ip_control_file 의 한 예이다.
[@dbname1]
10.10.10.10
10.156.*
[@dbname2]
*
[@dbname3]
192.168.1.15
위의 예에서 dbname1 데이터베이스는 10.10.10.10이거나 10.156으로 시작하는 IP의 접속을 허용한다. dbname2 데이터베이스는 모든 IP의 접속을 허용한다. dbname3 데이터베이스는 192.168.1.15인 IP의 접속을 허용한다.
이미 구동되어 있는 데이터베이스에 대해서는 다음 명령어를 통해 설정 파일을 다시 적용하거나, 현재 적용된 상태를 확인할 수 있다.
access_ip_control_file 의 내용을 변경하고 이를 서버에 적용하려면 다음 명령어를 사용한다.
cubrid server acl reload <database_name>
현재 구동 중인 서버의 IP 설정 내용을 출력하려면 다음 명령어를 사용한다.
cubrid server acl status <database_name>
데이터베이스 서버 로그¶
에러 로그¶
허용되지 않는 IP에서 접근하면 서버 에러 로그 파일에 다음과 같은 서버 에러 로그가 남는다.
Time: 10/29/10 17:32:42.360 - ERROR *** ERROR CODE = -1022, Tran = 0, CLIENT = (unknown):(unknown)(-1), EID = 2
Address(10.24.18.66) is not authorized.
데이터베이스 서버의 에러 로그는 $CUBRID/log/server 디렉터리에 생성되며, 파일 이름은 <db_name>_<yyyymmdd>_<hhmi>.err 형식으로 저장된다. 확장자는 .err이다.
demodb_20130618_1655.err
Note
브로커에서의 접속 제한을 위해서는 브로커 서버 접속 제한 을 참고한다.
이벤트 로그¶
질의 성능에 영향을 주는 이벤트가 발생하면 해당 이벤트를 이벤트 로그에 기록한다.
이벤트 로그에 저장되는 이벤트는 SLOW_QUERY, MANY_IOREADS, LOCK_TIMEOUT, DEADLOCK, 그리고 TEMP_VOLUME_EXPAND가 있다. 해당 로그 파일은 $CUBRID/log/server 디렉터리에 생성되며, 파일 이름은 <db_name>_<yyyymmdd>_<hhmi>.event 형식으로 저장된다. 확장자는 .event이다.
demodb_20130618_1655.event
SLOW_QUERY
슬로우 쿼리(slow query)가 발생했을 때 기록한다. cubrid.conf의 sql_trace_slow 파라미터 값이 설정되면 동작한다. 다음은 출력 예이다.
06/12/13 16:41:05.558 - SLOW_QUERY
client: PUBLIC@testhost|csql(13173)
sql: update [y] [y] set [y].[a]= ?:1 where [y].[a]= ?:0 using index [y].[pk_y_a](+)
bind: 5
bind: 200
time: 1015
buffer: fetch=48, ioread=2, iowrite=0
wait: cs=1, lock=1010, latch=0
- client: <DB 사용자>@<응용 클라이언트 호스트 명>|<프로그램 이름>(<프로세스 ID>)
- sql: 슬로우 쿼리
- bind: 바인딩되는 값. sql 항목에 나타난 ?:<num>에서 <num>의 순서대로 출력된다. ?:0의 값이 5이고, ?:1의 값이 200이다.
- time: 수행 시간 (ms)
- buffer: buffer 수행 통계 * fetch: 페치 페이지 개수 * ioread: I/O 읽기 페이지 개수 * iowrite: I/O 쓰기 페이지 개수
- wait: 대기 시간 * cs: 크리티컬 섹션에서 대기한 시간(ms) * lock: 잠금을 획득하려고 대기한 시간(ms) * latch: 래치를 획득하려고 대기한 시간(ms)
위의 예에서 질의 수행 시간이 1015ms가 소요되었는데 lock wait 시간이 1010ms 소요되어, 질의 수행 시간의 대부분이 잠금 대기 시간이었음을 알 수 있다.
MANY_IOREADS
I/O 읽기를 많이 발생시킨 질의를 기록한다. cubrid.conf의 sql_trace_ioread_pages 파라미터 설정 값 이상 I/O 읽기가 발생하면 로그를 기록한다. 다음은 출력 예이다.
06/12/13 17:07:29.457 - MANY_IOREADS
client: PUBLIC@testhost|csql(12852)
sql: update [x] [x] set [x].[a]= ?:1 where ([x].[a]> ?:0 ) using index [x].[idx](+)
bind: 8
bind: 100
time: 528
ioreads: 15648
- client: <DB 사용자>@<응용 클라이언트 호스트 명>|<프로세스 이름>(<프로세스 ID>)
- sql: 많은 I/O 읽기를 유발한 SQL
- bind: 바인딩되는 값. sql 항목에 나타난 ?:<num>에서 <num>의 순서대로 출력된다. ?:0의 값이 8이고, ?:1의 값이 100이다.
- time: 수행 시간 (ms)
- ioreads: I/O 읽기 페이지 개수
LOCK_TIMEOUT
잠금 타임아웃(lock timeout)이 발생하면 waiter와 blocker의 질의문을 기록한다. 다음은 출력 예이다.
06/13/13 20:56:18.650 - LOCK_TIMEOUT
waiter:
client: public@testhost|csql(21529)
lock: NX_LOCK (oid=-532|540|16386, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=400 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
blocker:
client: public@testhost|csql(21541)
lock: NX_LOCK (oid=-532|540|16386, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=100 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
- waiter: 잠금(lock)을 획득하려고 대기하는 클라이언트
- lock: 잠금 종류, 테이블 및 인덱스 이름
- sql: 잠금을 획득하려고 대기하는 SQL
- bind: 바인딩된 값
- blocker: 잠금(lock)을 소유하고 있는 클라이언트
- lock: 잠금 종류, 테이블 및 인덱스 이름
- sql: 잠금을 획득 중인 SQL
- bind: 바인딩된 값
위에서 잠금 타임아웃을 유발한 blocker와 잠금을 대기한 waiter를 알 수 있다.
DEADLOCK
교착 상태(deadlock)가 발생했을 때, cycle에 속해있는 트랜잭션의 잠금(lock) 정보들을 기록한다. 다음은 출력 예이다.
06/13/13 20:56:17.638 - DEADLOCK
client: public@testhost|csql(21541)
hold:
lock: NX_LOCK (oid=-532|540|16385, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=100 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
lock: NX_LOCK (oid=-532|540|16386, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=100 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
lock: X_LOCK (oid=0|540|1, table=y)
sql: update [y] [y] set [a]=100 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
wait:
lock: NX_LOCK (oid=-532|540|16390, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=300 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 5
client: public@testhost|csql(21529)
hold:
lock: NX_LOCK (oid=-532|540|16389, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=200 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 5
lock: NX_LOCK (oid=-532|540|16390, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=200 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 5
lock: X_LOCK (oid=0|540|5, table=y)
sql: update [y] [y] set [a]=200 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 5
wait:
lock: NX_LOCK (oid=-532|540|16386, table=y, index=pk_y_a)
sql: update [y] [y] set [a]=400 where ([y].[a]= ?:0 ) using index [y].[pk_y_a](+)
bind: 1
- client: <DB 사용자>@<응용 클라이언트 호스트 명>|<프로세스 이름>(<프로세스 ID>)
- hold: 잠금을 소유하고 있는 객체
- lock: 잠금 종류, 테이블 및 인덱스 이름
- sql: 잠금을 소유하고 있는 SQL
- bind: 바인딩된 값
- wait: 잠금을 대기하고 있는 객체
- lock: 잠금 종류, 테이블 및 인덱스 이름
- sql: 잠금을 대기하고 있는 SQL
- bind: 바인딩된 값
- hold: 잠금을 소유하고 있는 객체
위에서 교착 상태를 유발한 응용 클라이언트들과 SQL을 확인할 수 있다.
잠금(lock)에 대한 자세한 설명은 잠금(Lock) 상태 확인과 잠금 프로토콜을 참고한다.
TEMP_VOLUME_EXPAND
일시적 임시 볼륨(temporary temp volume)이 확장되면 해당 시각을 기록한다. 이를 통해 일시적 임시 볼륨 확장을 유발한 트랜잭션을 확인할 수 있다.
06/15/13 18:55:43.458 - TEMP_VOLUME_EXPAND
client: public@testhost|csql(17540)
sql: select [x].[a], [x].[b] from [x] [x] where (([x].[a]< ?:0 )) group by [x].[b] order by 1
bind: 1000
time: 44
pages: 24399
- client: <DB 사용자>@<응용 클라이언트 호스트 명>|<프로그램 이름>(<프로세스 ID>)
- sql: 일시적 임시 볼륨이 필요한 SQL. INSERT ... SELECT를 제외한 모든 INSERT 문, DDL 문 등은 DB 서버에 SQL이 전달되지 않기 때문에 EMPTY로 표시된다. SELECT, UPDATE, DELETE 문은 SQL이 표시된다.
- bind: 바인딩된 값
- time: 일시적 임시 볼륨을 생성하는데 소요된 시간(ms).
- pages: 일시적 임시 볼륨 생성에 필요한 페이지 개수
데이터베이스 서버 에러¶
데이터베이스 서버 프로세스는 에러 발생 시 서버 에러 코드를 사용한다. 서버 에러는 서버 프로세스를 사용하는 모든 작업에서 발생할 수 있다. 예를 들어 질의를 처리하는 프로그램 또는 cubrid 유틸리티 사용 중에도 발생할 수 있다.
데이터베이스 서버 에러 코드의 확인
- CUBRID/include/dbi.h 파일의 #define ER_ 로 시작하는 정의문은 모두 서버 에러 코드를 나타낸다.
- CUBRID/msg/en_US (한글은 ko_KR.eucKR 혹은 ko_KR.utf8) /cubrid.msg 파일의 "$set 5 MSGCAT_SET_ERROR" 이하 메시지 그룹은 모두 서버 에러 메시지를 나타낸다.
프로그램을 작성할 때는 에러 코드 번호를 직접 사용하는 것보다는 에러 코드 이름을 사용할 것을 권장한다. 예를 들어, 고유 키 위반 시 에러 코드 번호는 -670 혹은 -886이지만 이 번호보다는 ER_BTREE_UNIQUE_FAILED 혹은 ER_UNIQUE_VIOLATION_WITHKEY 을 사용하는 것이 프로그램 가독성을 높이기 때문이다.
$ vi $CUBRID/include/dbi.h
#define NO_ERROR 0
#define ER_FAILED -1
#define ER_GENERIC_ERROR -1
#define ER_OUT_OF_VIRTUAL_MEMORY -2
#define ER_INVALID_ENV -3
#define ER_INTERRUPTED -4
...
#define ER_LK_OBJECT_TIMEOUT_SIMPLE_MSG -73
#define ER_LK_OBJECT_TIMEOUT_CLASS_MSG -74
#define ER_LK_OBJECT_TIMEOUT_CLASSOF_MSG -75
#define ER_LK_PAGE_TIMEOUT -76
...
#define ER_PT_SYNTAX -493
...
#define ER_BTREE_UNIQUE_FAILED -670
...
#define ER_UNIQUE_VIOLATION_WITHKEY -886
...
#define ER_LK_OBJECT_DL_TIMEOUT_SIMPLE_MSG -966
#define ER_LK_OBJECT_DL_TIMEOUT_CLASS_MSG -967
#define ER_LK_OBJECT_DL_TIMEOUT_CLASSOF_MSG -968
...
#define ER_LK_DEADLOCK_CYCLE_DETECTED -1021
#define ER_LK_DEADLOCK_SPECIFIC_INFO -1083
...
몇 가지 서버 에러 코드 이름 및 에러 코드 번호, 에러 메시지를 살펴보면 다음과 같다.
| 에러 코드 이름 | 에러 번호 | 에러 메시지 |
|---|---|---|
| ER_LK_OBJECT_TIMEOUT_SIMPLE_MSG | -73 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on object ?|?|?. You are waiting for user(s) ? to finish. |
| ER_LK_OBJECT_TIMEOUT_CLASS_MSG | -74 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on class ?. You are waiting for user(s) ? to finish. |
| ER_LK_OBJECT_TIMEOUT_CLASSOF_MSG | -75 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on instance ?|?|? of class ?. You are waiting for user(s) ? to finish. |
| ER_LK_PAGE_TIMEOUT | -76 | Your transaction (index ?, ?@?|?) timed out waiting on ? on page ?|?. You are waiting for user(s) ? to release the page lock. |
| ER_PT_SYNTAX | -493 | Syntax: ? |
| ER_BTREE_UNIQUE_FAILED | -670 | Operation would have caused one or more unique constraint violations. |
| ER_UNIQUE_VIOLATION_WITHKEY | -886 | "?" caused unique constraint violation. |
| ER_LK_OBJECT_DL_TIMEOUT_SIMPLE_MSG | -966 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on object ?|?|? because of deadlock. You are waiting for user(s) ? to finish. |
| ER_LK_OBJECT_DL_TIMEOUT_CLASS_MSG | -967 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on class ? because of deadlock. You are waiting for user(s) ? to finish. |
| ER_LK_OBJECT_DL_TIMEOUT_CLASSOF_MSG | -968 | Your transaction (index ?, ?@?|?) timed out waiting on ? lock on instance ?|?|? of class ? because of deadlock. You are waiting for user(s) ? to |
| ER_LK_DEADLOCK_CYCLE_DETECTED | -1021 | A deadlock cycle is detected. ?. |
| ER_LK_DEADLOCK_SPECIFIC_INFO | -1083 | Specific information about deadlock. |
브로커¶
브로커 구동¶
브로커를 구동하기 위하여 다음과 같이 입력한다.
$ cubrid broker start
@ cubrid broker start
++ cubrid broker start: success
이미 브로커가 구동 중이라면 다음과 같은 메시지가 출력된다.
cubrid broker start
@ cubrid broker start
++ cubrid broker is running.
브로커 종료¶
브로커를 종료하기 위하여 다음과 같이 입력한다.
$ cubrid broker stop
@ cubrid broker stop
++ cubrid broker stop: success
이미 브로커가 종료되었다면 다음과 같은 메시지가 출력된다.
$ cubrid broker stop
@ cubrid broker stop
++ cubrid broker is not running.
브로커 상태 확인¶
cubrid broker status 는 여러 옵션을 제공하여, 각 브로커의 처리 완료된 작업 수, 처리 대기중인 작업 수를 포함한 브로커 상태 정보를 확인할 수 있도록 한다.
cubrid broker status [options] [expr]
- expr: 브로커 이름의 일부 또는 "SERVICE=ON|OFF"
[expr]이 명시되면 이름이 [expr]을 포함하는 브로커에 대한 상태 모니터링을 수행하고, 생략되면 CUBRID 브로커 환경 설정 파일( cubrid_broker.conf )에 등록된 전체 브로커에 대해 상태 모니터링을 수행한다.
[expr]에 "SERVICE=ON"이 명시되면 구동 중인 브로커의 상태만 출력하며, "SERVICE=OFF"가 명시되면 멈춰있는 브로커의 이름만 출력한다.
cubrid broker status 에서 사용하는 [options]는 다음과 같다.
-
-b¶ 브로커 응용 서버(CAS)에 관한 정보는 포함하지 않고, 브로커에 관한 상태 정보만 출력한다.
-
-f¶ 브로커가 접속한 DB 및 호스트 정보를 출력한다.
-b 옵션과 함께 쓰이는 경우, CAS 정보를 추가로 출력한다. 하지만 -b 옵션에서 나타나는 SELECT, INSERT, UPDATE, DELETE, OTHERS 항목은 제외된다.
-
-lSECOND¶ -l 옵션은 -f 옵션과만 함께 쓰이며, 클라이언트 Waiting/Busy 상태인 CAS의 개수를 출력할 때 누적 주기(단위: 초)를 지정하기 위해 사용한다. -l SECOND 옵션을 생략하면 기본값은 1초이다.
-
-q¶ 작업 큐에 대기 중인 작업을 출력한다.
-
-t¶ 화면 출력시 tty mode 로 출력한다. 출력 내용을 리다이렉션하여 파일로 쓸 수 있다.
-
-sSECOND¶ 브로커에 관한 상태 정보를 지정된 시간마다 주기적으로 출력한다. q를 입력하면 명령 프롬프트로 복귀한다.
전체 브로커 상태 정보를 확인하기 위하여 옵션 및 인수를 입력하지 않으면 다음과 같이 출력된다.
$ cubrid broker status
@ cubrid broker status
% query_editor
----------------------------------------
ID PID QPS LQS PSIZE STATUS
----------------------------------------
1 28434 0 0 50144 IDLE
2 28435 0 0 50144 IDLE
3 28436 0 0 50144 IDLE
4 28437 0 0 50140 IDLE
5 28438 0 0 50144 IDLE
% broker1 OFF
- % query_editor: 브로커의 이름
- ID: 브로커 내에서 순차적으로 부여한 CAS의 일련 번호
- PID: 브로커 내 CAS 프로세스의 ID
- QPS: 초당 처리된 질의의 수
- LQS: 초당 처리되는 장기 실행 질의의 수
- PSIZE: CAS 프로세스 크기
- STATUS: CAS의 현재 상태로서, BUSY/IDLE/CLIENT_WAIT/CLOSE_WAIT가 있다.
- % broker1 OFF: broker1의 SERVICE 파라미터가 OFF이다. 따라서, broker1은 구동되지 않는다.
브로커에 관해 5초 간격으로 상세한 상태 정보를 확인하려면 다음과 같이 입력한다. 화면이 5초 간격마다 새로운 상태 정보로 갱신되며, 상태 정보 화면을 벗어나려면 <Q>를 누른다.
$ cubrid broker status -b -s 5
@ cubrid broker status
NAME PID PORT AS JQ TPS QPS SELECT INSERT UPDATE DELETE OTHERS LONG-T LONG-Q ERR-Q UNIQUE-ERR-Q #CONNECT
================================================================================================================================================================================================
* query_editor 13200 30000 5 0 0 0 0 0 0 0 0 0/60.0 0/60.0 0 0 0
* broker1 13269 33000 5 0 70 60 10 20 10 10 10 0/60.0 0/60.0 30 10 213
- NAME: 브로커 이름
- PID: 브로커의 프로세스 ID
- PORT: 브로커의 포트 번호
- AS: CAS 개수
- JQ: 작업 큐에서 대기 중인 작업 개수
- TPS: 초당 처리된 트랜잭션의 수(옵션이 "-b -s <sec>"일 때만 해당 구간 계산)
- QPS: 초당 처리된 질의의 수(옵션이 "-b -s <sec>"일 때만 해당 구간 계산)
- SELECT: 브로커 시작 이후 SELECT 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 SELECT 개수로 매번 갱신됨.
- INSERT: 브로커 시작 이후 INSERT 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 INSERT 개수로 매번 갱신됨.
- UPDATE: 브로커 시작 이후 UPDATE 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 UPDATE 개수로 매번 갱신됨.
- DELETE: 브로커 시작 이후 DELETE 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 DELETE 개수로 매번 갱신됨.
- OTHERS: 브로커 시작 이후 SELECT, INSERT, UPDATE, DELETE를 제외한 CREATE, DROP 등의 질의 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 질의 개수로 매번 갱신됨.
- LONG-T: LONG_TRANSACTION_TIME 시간을 초과한 트랜잭션 개수 / LONG_TRANSACTION_TIME 파라미터의 값. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 트랜잭션 개수로 매번 갱신됨.
- LONG-Q: LONG_QUERY_TIME 시간을 초과한 질의의 개수 / LONG_QUERY_TIME 파라미터의 값. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 질의 개수로 매번 갱신됨.
- ERR-Q: 에러가 발생한 질의의 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 에러 개수로 매번 갱신됨.
- UNIQUE-ERR-Q: 고유 키 에러가 발생한 질의의 개수. 옵션이 "-b -s <sec>"인 경우 -s 옵션으로 지정한 초 동안의 고유 키 에러 개수로 매번 갱신됨.
- #CONNECT: 브로커 시작 후 응용 클라이언트가 CAS에 접속한 회수.
-q 옵션을 이용하여 broker1을 포함하는 이름을 가진 브로커의 상태 정보를 확인하고, 해당 브로커의 작업 큐에 대기 중인 작업 상태를 확인하기 위하여 다음과 같이 입력한다. 인수로 broker1을 입력하지 않으면 모든 브로커에 대하여 작업 큐에 대기 중인 작업 리스트가 출력된다.
% cubrid broker status -q broker1
@ cubrid broker status
% broker1
----------------------------------------
ID PID QPS LQS PSIZE STATUS
----------------------------------------
1 28444 0 0 50144 IDLE
2 28445 0 0 50140 IDLE
3 28446 0 0 50144 IDLE
4 28447 0 0 50144 IDLE
5 28448 0 0 50144 IDLE
-s 옵션을 이용하여 broker1을 포함하는 이름을 가진 브로커의 상태를 주기적으로 모니터링하기 위해 다음과 같이 입력한다. 인수로 broker1을 입력하지 않으면 모든 브로커에 대하여 상태 모니터링이 주기적으로 수행된다. 또한, q를 입력하면 모니터링 화면에서 명령 프롬프트로 복귀한다.
% cubrid broker status -s 5 broker1
% broker1
----------------------------------------
ID PID QPS LQS PSIZE STATUS
----------------------------------------
1 28444 0 0 50144 IDLE
2 28445 0 0 50140 IDLE
3 28446 0 0 50144 IDLE
4 28447 0 0 50144 IDLE
5 28448 0 0 50144 IDLE
-t 옵션을 이용하여 TPS와 QPS 정보를 파일로 출력한다. 파일로 출력하는 것을 중단하려면 <Ctrl+C>를 눌러서 프로그램을 정지시킨다.
% cubrid broker status -b -t -s 1 > log_file
-f 옵션을 이용하여 브로커가 연결한 서버/데이터베이스 정보와 응용 클라이언트의 최근 접속 시각, CAS에 접속하는 클라이언트의 IP 주소와 드라이버의 버전 등을 확인하기 위해 다음과 같이 입력한다.
$ cubrid broker status -f broker1
@ cubrid broker status
% broker1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ID PID QPS LQS PSIZE STATUS LAST ACCESS TIME DB HOST LAST CONNECT TIME CLIENT IP CLIENT VERSION SQL_LOG_MODE TRANSACTION STIME # CONNECT # RESTART
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 26946 0 0 51168 IDLE 2011/11/16 16:23:42 demodb localhost 2011/11/16 16:23:40 10.0.1.101 8.4.4.0165 NONE 2011/11/16 16:23:42 0 0
2 26947 0 0 51172 IDLE 2011/11/16 16:23:34 - - - 0.0.0.0 - - 0 0
3 26948 0 0 51172 IDLE 2011/11/16 16:23:34 - - - 0.0.0.0 - - 0 0
4 26949 0 0 51172 IDLE 2011/11/16 16:23:34 - - - 0.0.0.0 - - 0 0
5 26950 0 0 51172 IDLE 2011/11/16 16:23:34 - - - 0.0.0.0 - - 0 0
각 칼럼에 대한 설명은 다음과 같다.
- LAST ACCESS TIME: CAS가 구동한 시각 또는 응용 클라이언트의 CAS에 최근 접속한 시각
- DB: CAS의 최근 접속 데이터베이스 이름
- HOST: CAS의 최근 접속 호스트 이름
- LAST CONNECT TIME: CAS의 DB 서버 최근 접속 시각
- CLIENT IP: 현재 CAS에 접속 중인 응용 클라이언트의 IP 주소. 현재 접속 중인 응용 클라이언트가 없으면 0.0.0.0으로 출력
- CLIENT VERSION: 현재 CAS에 접속 중인 응용 클라이언트의 드라이버 버전
- SQL_LOG_MODE: CAS의 SQL 로그 기록 모드. 브로커에 설정된 모드와 동일한 경우 "-"으로 출력
- TRANSACTION STIME: 트랜잭션 시작 시간
- # CONNECT: 브로커 시작 후 응용 클라이언트가 CAS에 접속한 회수
- # RESTART: 브로커 시작 후 CAS의 재구동 회수
-b 옵션과 -f 옵션을 이용하여 AS(T W B Ns-W Ns-B), CANCELED 정보를 출력한다.
// 브로커 상태 정보 실행 시 -f 옵션 추가. -l 옵션으로 N초 동안의 Ns-W, Ns-B를 출력하도록 초를 설정
% cubrid broker status -b -f -l 2
@ cubrid broker status
NAME PID PSIZE PORT AS(T W B 2s-W 2s-B) JQ TPS QPS LONG-T LONG-Q ERR-Q UNIQUE-ERR-Q CANCELED ACCESS_MODE SQL_LOG #CONNECT
========================================================================================================================================
query_editor 16784 56700 30000 5 0 0 0 0 0 16 29 0/60.0 0/60.0 1 1 0 RW ALL 4
각 칼럼에 대한 설명은 다음과 같다.
- AS(T): 실행 중인 CAS의 전체 개수
- AS(W): 현재 클라이언트 대기(Waiting) 상태인 CAS의 개수
- AS(B): 현재 클라이언트 수행(Busy) 상태인 CAS의 개수
- AS(Ns-W): N초 동안 클라이언트 대기(Waiting) 상태였던 CAS의 개수
- AS(Ns-B): N초 동안 클라이언트 수행(Busy) 상태였던 CAS의 개수
- CANCELED: 브로커 시작 이후 사용자 인터럽트로 인해 취소된 질의의 개수 (-l N 옵션과 함께 사용하면 N초 동안 누적된 개수)
브로커 서버 접속 제한¶
브로커에 접속하는 응용 클라이언트를 제한하려면 cubrid_broker.conf 의 ACCESS_ CONTROL 파라미터 값을 ON으로 설정하고, ACCESS_CONTROL_FILE 파라미터 값에 접속을 허용하는 사용자와 데이터베이스 및 IP 목록을 작성한 파일 이름을 입력한다. ACCESS_CONTROL 브로커 파라미터의 기본값은 OFF 이다. ACCESS_CONTROL, ACCESS_CONTROL_FILE 파라미터는 공통 적용 파라미터가 위치하는 [broker] 아래에 작성해야 한다.
ACCESS_CONTROL_FILE 의 형식은 다음과 같다.
[%<broker_name>]
<db_name>:<db_user>:<ip_list_file>
…
- <broker_name>: 브로커 이름. cubrid_broker.conf 에서 지정한 브로커 이름 중 하나이다.
- <db_name>: 데이터베이스 이름. *로 지정하면 모든 데이터베이스를 허용한다.
- <db_user>: 데이터베이스 사용자 ID. *로 지정하면 모든 데이터베이스 사용자 ID를 허용한다.
- <ip_list_file>: 접속 가능한 IP 목록을 저장한 파일의 이름. ip_list_file1, ip_list_file2, …와 같이 파일 여러 개를 쉼표(,)로 구분하여 지정할 수 있다.
브로커별로 [%<broker_name>]과 <db_name>:<db_user>:<ip_list_file>을 추가 지정할 수 있으며, 같은 <db_name>, 같은 <db_user>에 대해 별도의 라인으로 추가 지정할 수 있다. IP 목록은 하나의 브로커 내에서 <db_name>:<db_user> 별로 최대 256 라인까지 작성될 수 있다.
ip_list_file의 작성 형식은 다음과 같다.
<ip_addr>
…
- <ip_addr>: 접근을 허용할 IP 명. 뒷자리를 *로 입력하면 뒷자리의 모든 IP를 허용한다.
ACCESS_CONTROL 값이 ON인 상태에서 ACCESS_CONTROL_FILE 이 지정되지 않으면 브로커는 localhost에서의 접속 요청만을 허용한다.
브로커 구동 시 ACCESS_CONTROL_FILE 및 ip_list_file 분석에 실패하는 경우 브로커는 구동되지 않는다.
# cubrid_broker.conf
[broker]
MASTER_SHM_ID =30001
ADMIN_LOG_FILE =log/broker/cubrid_broker.log
ACCESS_CONTROL =ON
ACCESS_CONTROL_FILE =/home1/cubrid/access_file.txt
[%QUERY_EDITOR]
SERVICE =ON
BROKER_PORT =30000
......
다음은 ACCESS_CONTROL_FILE 의 한 예이다. 파일 내에서 사용하는 *은 모든 것을 나타내며, 데이터베이스 이름, 데이터베이스 사용자 ID, 접속을 허용하는 IP 리스트 파일 내의 IP에 대해 지정할 때 사용할 수 있다.
[%QUERY_EDITOR]
dbname1:dbuser1:READIP.txt
dbname1:dbuser2:WRITEIP1.txt,WRITEIP2.txt
*:dba:READIP.txt
*:dba:WRITEIP1.txt
*:dba:WRITEIP2.txt
[%BROKER2]
dbname:dbuser:iplist2.txt
[%BROKER3]
dbname:dbuser:iplist2.txt
[%BROKER4]
dbname:dbuser:iplist2.txt
위의 예에서 지정한 브로커는 QUERY_EDITOR, BROKER2, BROKER3, BROKER4이다.
QUERY_EDITOR 브로커는 다음과 같은 응용의 접속 요청만을 허용한다.
- dbname1 에 dbuser1 으로 로그인하는 사용자가 READIP.txt에 등록된 IP에서 접속
- dbname1 에 dbuser2 로 로그인하는 사용자가 WRITEIP1.txt나 WRITEIP2.txt에 등록된 IP에서 접속
- 모든 데이터베이스에 DBA 로 로그인하는 사용자가 READIP.txt나 WRITEIP1.txt 또는 WRITEIP2.txt에 등록된 IP에서 접속
다음은 ip_list_file에서 허용하는 IP를 설정하는 예이다.
192.168.1.25
192.168.*
10.*
*
위의 예에서 지정한 IP를 보면 다음과 같다.
- 첫 번째 줄의 설정은 192.168.1.25을 허용한다.
- 두 번째 줄의 설정은 192.168 로 시작하는 모든 IP를 허용한다.
- 세 번째 줄의 설정은 10으로 시작하는 모든 IP를 허용한다.
- 네 번째 줄의 설정은 모든 IP를 허용한다.
이미 구동되어 있는 브로커에 대해서는 다음 명령어를 통해 설정 파일을 다시 적용하거나 현재 적용 상태를 확인할 수 있다.
브로커에서 허용하는 데이터베이스, 데이터베이스 사용자 ID, IP를 설정한 후 변경된 내용을 서버에 적용하려면 다음 명령어를 사용한다.
cubrid broker acl reload [<BR_NAME>]
- <BR_NAME>: 브로커 이름. 이 값을 지정하면 특정 브로커만 변경 내용을 적용할 수 있으며, 생략하면 전체 브로커에 변경 내용을 적용한다.
현재 구동 중인 브로커에서 허용하는 데이터베이스, 데이터베이스 사용자 ID, IP의 설정을 화면에 출력하려면 다음 명령어를 사용한다.
cubrid broker acl status [<BR_NAME>]
- <BR_NAME>: 브로커 이름. 이 값을 지정하면 특정 브로커의 설정을 출력할 수 있으며, 생략하면 전체 브로커의 설정을 출력한다.
브로커 로그
허용되지 않는 IP에서 접근하면 다음과 같은 로그가 남는다.
- ACCESS_LOG
1 192.10.10.10 - - 1288340944.198 1288340944.198 2010/10/29 17:29:04 ~ 2010/10/29 17:29:04 14942 - -1 db1 dba : rejected
- SQL LOG
10/29 10:28:57.591 (0) CLIENT IP 192.10.10.10 10/29 10:28:57.592 (0) connect db db1 user dba url jdbc:cubrid:192.10.10.10:30000:db1::: - rejected
Note
데이터베이스 서버에서의 접속 제한을 위해서는 데이터베이스 서버 접속 제한 을 참고한다.
특정 브로커 관리¶
broker1 만 구동하기 위하여 다음과 같이 입력한다. 단, broker1 은 이미 공유 메모리에 설정된 브로커이다.
% cubrid broker on broker1
만약, broker1 이 공유 메모리에 설정되지 않은 상태라면 다음과 같은 메시지가 출력된다.
% cubrid broker on broker1
Cannot open shared memory
broker1 만 종료하기 위하여 다음과 같이 입력한다. 이 때, broker1 의 서비스 풀을 함께 제거할 수 있다.
% cubrid broker off broker1
브로커 리셋 기능은 HA에서 failover 등으로 브로커 응용 서버(CAS)가 원하지 않는 데이터베이스 서버에 연결되었을 때, 기존 연결을 끊고 새로 연결할 수 있도록 한다. 예를 들어 Read Only 브로커가 액티브 서버와 연결된 후에는 스탠바이 서버가 연결이 가능한 상태가 되더라도 자동으로 스탠바이 서버와 재연결하지 않으며, cubrid broker reset 명령을 통해서만 기존 연결을 끊고 새로 스탠바이 서버와 연결할 수 있다.
broker1 을 리셋하려면 다음과 같이 입력한다.
% cubrid broker reset broker1
브로커 파라미터의 동적 변경¶
브로커 구동과 관련된 파라미터는 브로커 환경 설정 파일( cubrid_broker.conf )에서 설정할 수 있다. 그 밖에, broker_changer 유틸리티를 이용하여 구동 중에만 한시적으로 일부 브로커 파라미터를 동적으로 변경할 수 있다. 브로커 파라미터 설정 및 동적으로 변경 가능한 브로커 파라미터 등 기타 자세한 내용은 브로커 설정 을 참조한다.
브로커 구동 중에 브로커 파라미터를 변경하기 위한 broker_changer 유틸리티의 구문은 다음과 같다. broker_name에는 구동 중인 브로커 이름을 입력하면 되고 parameter는 동적으로 변경할 수 있는 브로커 파라미터에 한정된다. 변경하고자 하는 파라미터에 따라 value가 지정되어야 한다. 브로커 응용 서버 식별자( cas_id )를 지정하여 특정 브로커 응용 서버(CAS)에만 변경을 적용할 수도 있다. cas_id는 cubrid broker status 명령어에서 출력되는 ID이다.
broker_changer broker_name [cas_id] parameters value
구동 중인 브로커에서 SQL 로그가 기록되도록 SQL_LOG 파라미터를 ON으로 설정하기 위하여 다음과 같이 입력한다. 이와 같은 파라미터의 동적 변경은 브로커 구동 중일 때만 한시적으로 효력이 있다.
% broker_changer query_editor sql_log on
OK
HA 환경에서 브로커의 ACCESS_MODE 를 Read Only로 변경하고 해당 브로커를 자동으로 reset하기 위하여 다음과 같이 입력한다.
% broker_changer broker_m access_mode ro
OK
Note
Windows Vista 이상 버전에서 cubrid 유틸리티를 사용하여 서비스를 제어하려면 명령 프롬프트 창을 관리자 권한으로 구동한 후 사용하는 것을 권장한다. 자세한 내용은 CUBRID 유틸리티 를 참고한다.
브로커 설정 정보 확인¶
cubrid broker info 는 현재 "실행 중"인 브로커 파라미터의 설정 정보(cubrid_broker.conf)를 출력한다. broker_changer 명령에 의해 브로커 파라미터의 설정 정보가 동적으로 변경될 수 있는데, cubrid broker info 명령으로 동작 중인 브로커의 설정 정보를 확인할 수 있다.
% cubrid broker info
참고로 현재 "실행 중"인 시스템 파라미터의 설정 정보(cubrid.conf)를 확인하려면 cubrid paramdump database_name 명령을 사용한다. SET SYSTEM PARAMETERS 구문에 의해 시스템 파라미터의 설정 정보가 동적으로 변경될 수 있는데, cubrid broker info 명령으로 동작 중인 시스템의 설정 정보를 확인할 수 있다.
브로커 로그¶
브로커 구동과 관련된 로그에는 접속 로그, 에러 로그, SQL 로그가 있다. 각각의 로그는 설치 디렉터리의 log 디렉터리에서 확인할 수 있으며, 저장 디렉터리의 변경은 브로커 환경 설정 파일( cubrid_broker.conf )의 LOG_DIR 파라미터와 ERROR_LOG_DIR 파라미터를 통해 설정할 수 있다.
접속 로그 확인¶
접속 로그 파일은 응용 클라이언트 접속에 관한 정보를 기록하며, <broker_name>.access의 이름으로 log/broker/ 디렉터리에 저장된다. 또한, 브로커 환경 설정 파일에서 LOG_BACKUP 파라미터가 ON으로 설정된 경우, 브로커의 구동이 정상적으로 종료되면 접속 로그 파일에 종료된 날짜와 시간 정보가 추가되어 로그 파일이 저장된다. 예를 들어, broker1이 2008년 6월 17일 오후 12시 27분에 정상 종료되었다면, broker1.access.20080617.1227 이라는 접속 로그 파일이 생성된다.
다음은 log 디렉터리에 생성된 접속 로그 파일의 예제와 설명이다.
1 192.168.1.203 - - 972523031.298 972523032.058 2008/06/17 12:27:46~2008/06/17 12:27:47 7118 - -1
2 192.168.1.203 - - 972523052.778 972523052.815 2008/06/17 12:27:47~2008/06/17 12:27:47 7119 ERR 1025
1 192.168.1.203 - - 972523052.778 972523052.815 2008/06/17 12:27:49~2008/06/17 12:27:49 7118 - -1
- 1 : 브로커의 응용서버에 부여된 ID
- 192.168.1.203 : 응용 클라이언트의 IP 주소
- 972523031.298 : 클라이언트의 요청 처리를 시작한 시각의 UNIX 타임스탬프 값
- 2008/06/17 12:27:46 : 클라이언트 요청을 처리 시작한 시각
- 972523032.058 : 클라이언트의 요청 처리를 완료한 시각의 UNIX 타임스탬프 값
- 2008/06/17 12:27:47 : 클라이언트의 요청을 처리 완료한 시각
- 7118 : 응용서버의 프로세스 ID
- -1 : 요청 처리 중 발생한 에러가 없음
- ERR 1025 : 요청 처리 중 발생한 에러가 있고, 에러 정보는 에러 로그 파일의 offset=1025에 존재함
에러 로그 확인¶
에러 로그 파일은 응용 클라이언트의 요청을 처리하는 도중에 발생한 에러에 관한 정보를 기록하며, <broker_name>_<app_server_num>.err의 이름으로 저장된다.
다음은 에러 로그의 예제와 설명이다.
Time: 02/04/09 13:45:17.687 - SYNTAX ERROR *** ERROR CODE = -493, Tran = 1, EID = 38
Syntax: Unknown class "unknown_tbl". select * from unknown_tbl
- Time: 02/04/09 13:45:17.687: 에러 발생 시각
- SYNTAX ERROR: 에러의 종류(SYNTAX ERROR, ERROR 등)
- *** ERROR CODE = -493: 에러 코드
- Tran = 1: 트랜잭션 ID. -1은 트랜잭션 ID를 할당 받지 못한 경우임.
- EID = 38: 에러 ID. SQL 문 처리 중 에러가 발생한 경우, 서버나 클라이언트 에러 로그와 관련이 있는 SQL 로그를 찾을 때 사용함.
- Syntax ...: 에러 메시지
SQL 로그 관리¶
SQL 로그 파일은 응용 클라이언트가 요청하는 SQL을 기록하며, <broker_name>_<app_server_num>.sql.log라는 이름으로 저장된다. SQL 로그는 SQL_LOG 파라미터 값이 ON인 경우에 설치 디렉터리의 log/broker/sql_log 디렉터리에 생성된다. 이 때, 생성되는 SQL 로그 파일의 크기는 SQL_LOG_MAX_SIZE 파라미터의 설정값을 초과할 수 없으므로 주의한다. CUBRID는 SQL 로그를 관리하기 위한 유틸리티로서 broker_log_top, cubrid_replay를 제공하며, 이 유틸리티는 SQL 로그가 존재하는 디렉터리에서 실행해야 한다.
다음은 SQL 로그 파일의 예제와 설명이다.
13-06-11 15:07:39.282 (0) STATE idle
13-06-11 15:07:44.832 (0) CLIENT IP 192.168.10.100
13-06-11 15:07:44.835 (0) CLIENT VERSION 8.4.4.0178
13-06-11 15:07:44.835 (0) session id for connection 0
13-06-11 15:07:44.836 (0) connect db demodb user dba url jdbc:cubrid:192.168.10.200:30000:demodb:dba:********: session id 12
13-06-11 15:07:44.836 (0) DEFAULT isolation_level 3, lock_timeout -1
13-06-11 15:07:44.840 (0) end_tran COMMIT
13-06-11 15:07:44.841 (0) end_tran 0 time 0.000
13-06-11 15:07:44.841 (0) *** elapsed time 0.004
13-06-11 15:07:44.844 (0) check_cas 0
13-06-11 15:07:44.848 (0) set_db_parameter lock_timeout 1000
13-06-11 15:09:36.299 (0) check_cas 0
13-06-11 15:09:36.303 (0) get_db_parameter isolation_level 3
13-06-11 15:09:36.375 (1) prepare 0 CREATE TABLE unique_tbl (a INT PRIMARY key);
13-06-11 15:09:36.376 (1) prepare srv_h_id 1
13-06-11 15:09:36.419 (1) set query timeout to 0 (no limit)
13-06-11 15:09:36.419 (1) execute srv_h_id 1 CREATE TABLE unique_tbl (a INT PRIMARY key);
13-06-11 15:09:38.247 (1) execute 0 tuple 0 time 1.827
13-06-11 15:09:38.247 (0) auto_commit
13-06-11 15:09:38.344 (0) auto_commit 0
13-06-11 15:09:38.344 (0) *** elapsed time 1.968
13-06-11 15:09:54.481 (0) get_db_parameter isolation_level 3
13-06-11 15:09:54.484 (0) close_req_handle srv_h_id 1
13-06-11 15:09:54.484 (2) prepare 0 INSERT INTO unique_tbl VALUES (1);
13-06-11 15:09:54.485 (2) prepare srv_h_id 1
13-06-11 15:09:54.488 (2) set query timeout to 0 (no limit)
13-06-11 15:09:54.488 (2) execute srv_h_id 1 INSERT INTO unique_tbl VALUES (1);
13-06-11 15:09:54.488 (2) execute 0 tuple 1 time 0.001
13-06-11 15:09:54.488 (0) auto_commit
13-06-11 15:09:54.505 (0) auto_commit 0
13-06-11 15:09:54.505 (0) *** elapsed time 0.021
...
13-06-11 15:19:04.593 (0) get_db_parameter isolation_level 3
13-06-11 15:19:04.597 (0) close_req_handle srv_h_id 2
13-06-11 15:19:04.597 (7) prepare 0 SELECT * FROM unique_tbl WHERE ROWNUM BETWEEN 1 AND 5000;
13-06-11 15:19:04.598 (7) prepare srv_h_id 2 (PC)
13-06-11 15:19:04.602 (7) set query timeout to 0 (no limit)
13-06-11 15:19:04.602 (7) execute srv_h_id 2 SELECT * FROM unique_tbl WHERE ROWNUM BETWEEN 1 AND 5000;
13-06-11 15:19:04.602 (7) execute 0 tuple 1 time 0.001
13-06-11 15:19:04.607 (0) end_tran COMMIT
13-06-11 15:19:04.607 (0) end_tran 0 time 0.000
13-06-11 15:19:04.607 (0) *** elapsed time 0.009
- 13-06-11 15:07:39.282 : 응용 클라이언트의 요청 시각
- : SQL 문 그룹의 시퀀스 번호이며, prepared statement pooling을 사용하는 경우, 파일 내에서 SQL 문마다 고유(unique)하게 부여된다.
- CLIENT IP: 응용 클라이언트의 IP
- CLIENT VERSION: 응용 클라이언트 드라이버의 버전
- prepare 0 : prepared statement인지 여부
- prepare srv_h_id 1 : 해당 SQL 문을 srv_h_id 1로 prepare한다.
- (PC) : 플랜 캐시에 저장되어 있는 내용을 사용하는 경우에 출력된다.
- Execute 0 tuple 1 time 0.001 : 1개의 row가 실행되고, 소요 시간은 0.001초
- auto_commit/auto_rollback : 자동으로 커밋되거나, 롤백되는 것을 의미한다. 두 번째 auto_commit/auto_rollback은 에러 코드이며, 0은 에러가 없이 트랜잭션이 완료되었음을 뜻한다.
broker_log_top¶
broker_log_top 유틸리티는 특정 기간 동안 생성된 SQL 로그를 분석하여 실행 시간이 긴 순서대로 각 SQL 문과 실행 시간에 관한 정보를 파일에 출력하며, 분석된 결과는 각각 log.top.q 및 log.top.res에 저장된다.
broker_log_top 유틸리티는 실행 시간이 긴 질의를 분석할 때 유용하며, 구문은 다음과 같다.
broker_log_top [options] sql_log_file_list
- sql_log_file_list: 분석할 로그 파일 이름
broker_log_top 에서 사용하는 [options]는 다음과 같다.
-t¶트랜잭션 단위로 결과를 출력한다.
-FDATE¶분석 대상 SQL의 시작 날짜를 지정한다. 입력 형식은 YY[-MM[-DD[ hh[:mm[:ss[.msec]]]]]]이며 []로 감싼 부분은 생략할 수 있다. 생략하면 MM, DD는 01을 입력한 것과 같고, hh, mm, ss, msec은 0을 입력한 것과 같다.
-TDATE¶분석 대상 SQL의 끝 날짜를 지정한다. 입력 형식은 -F 옵션의 DATE 와 같다.
옵션을 모두 생략하면, 모든 로그에 대해 SQL 문 단위로 결과를 출력한다.
다음은 밀리초까지 검색 범위를 설정하는 예제이다.
broker_log_top -F "01/19 15:00:25.000" -T "01/19 15:15:25.180" log1.log다음 예에서 시간 형식이 생략된 부분은 기본값 0으로 정해진다. 즉, -F "01/19 00:00:00.000" -T "01/20 00:00:00.000"을 입력한 것과 같다.
broker_log_top -F "01/19" -T "01/20" log1.log다음 예는 11월 11일부터 11월 12일까지 생성된 SQL 로그에 대해 실행 시간이 긴 SQL문을 확인하기 위하여 broker_log_top 유틸리티를 실행한 화면이다. 기간을 지정할 때, 월과 일은 빗금(/)으로 구분한다. Windows에서는 "*.sql.log" 를 인식하지 않으므로 SQL 로그 파일들을 공백(space)으로 구분해서 나열해야 한다.
--Linux에서 broker_log_top 실행 % broker_log_top -F "11/11" -T "11/12" -t *.sql.log query_editor_1.sql.log query_editor_2.sql.log query_editor_3.sql.log query_editor_4.sql.log query_editor_5.sql.log --Windows에서 broker_log_top 실행 % broker_log_top -F "11/11" -T "11/12" -t query_editor_1.sql.log query_editor_2.sql.log query_editor_3.sql.log query_editor_4.sql.log query_editor_5.sql.log위 예제를 실행하면 SQL 로그 분석 결과가 저장되는 log.top.q 및 log.top.res 파일이 동일한 디렉터리에 생성된다. log.top.q 에서 각 SQL 문 및 SQL 로그 상의 라인 번호를 확인할 수 있고, log.top.res 에서 각 SQL 문에 대한 최소 실행 시간, 최대 실행 시간, 평균 실행 시간, 쿼리 실행 수를 확인할 수 있다.
--log.top.q 파일의 내용 [Q1]------------------------------------------- broker1_6.sql.log:137734 11/11 18:17:59.396 (27754) execute_all srv_h_id 34 select a.int_col, b.var_col from dml_v_view_6 a, dml_v_view_6 b, dml_v_view_6 c , dml_v_view_6 d, dml_v_view_6 e where a.int_col=b.int_col and b.int_col=c.int_col and c.int_col=d.int_col and d.int_col=e.int_col order by 1,2; 11/11 18:18:58.378 (27754) execute_all 0 tuple 497664 time 58.982 . . [Q4]------------------------------------------- broker1_100.sql.log:142068 11/11 18:12:38.387 (27268) execute_all srv_h_id 798 drop table list_test; 11/11 18:13:08.856 (27268) execute_all 0 tuple 0 time 30.469 --log.top.res 파일의 내용 max min avg cnt(err) ----------------------------------------------------- [Q1] 58.982 30.371 44.676 2 (0) [Q2] 49.556 24.023 32.688 6 (0) [Q3] 35.548 25.650 30.599 2 (0) [Q4] 30.469 0.001 0.103 1050 (0)
cubrid_replay¶
cubrid_replay 유틸리티는 브로커의 SQL 로그를 재생하여, 기존의 수행 시간과 재생할 때의 수행 시간 차이를 비교하여 차이가 큰 것부터(기존보다 느린 것부터) 순서대로 정렬한 결과를 출력한다.
이 유틸리티는 SQL 로그에 기록된 질의들을 재생하되, 데이터의 변경이 발생하는 질의는 실행하지 않는다. 별도의 옵션을 주지 않으면 SELECT 문만 수행되며, -r 옵션을 부여하면 UPDATE, DELETE 문을 SELECT 문으로 변환하여 수행한다.
이 유틸리티는 서로 다른 두 장비 간 성능을 비교할 때 사용할 수 있는데, 예를 들어 하드웨어 스펙이 동일한 마스터와 슬레이브 사이에서도 같은 질의에 대해 성능 차이가 존재할 수 있다.
cubrid_replay -I <broker_host> -P <broker_port> -d <db_name> [options] <sql_log_file> <output_file>
- broker_host: CUBRID 브로커의 IP 주소 또는 호스트 이름
- broker_port: CUBRID 브로커의 포트 번호
- db_name: 질의를 실행할 데이터베이스
- sql_log_file: CUBRID 브로커의 SQL 로그 파일($CUBRID/log/broker/sql_log/*.log, *.log.bak)
- output_file: 수행 결과를 저장할 파일 이름
cubrid_replay 에서 사용하는 [options]는 다음과 같다.
-
-uDB_USER¶ 데이터베이스 사용자 이름 지정(기본값: public)
-
-pDB_PASSWORD¶ 데이터베이스 암호 지정
-
-r¶ UPDATE, DELETE 질의를 SELECT 질의로 변환
-
-hSECOND¶ 질의 실행 간격을 지정(기본값: 0.01초)
-
-DSECOND¶ (재생된 질의 수행 시간 - 기존에 실행된 질의 수행 시간)이 이 설정 값보다 큰 경우만 해당 질의가 output_file에 출력됨(기본값: 0.01초)
-
-FDATETIME¶ 재생 대상 SQL의 시작 날짜 및 시간을 지정한다. 입력 형식은 YY[-MM[-DD[ hh[:mm[:ss[.msec]]]]]]이며 []로 감싼 부분은 생략할 수 있다. 생략하면 MM, DD는 01을 입력한 것과 같고, hh, mm, ss, msec은 0을 입력한 것과 같다.
-
-TDATETIME¶ 재생 대상 SQL의 끝 날짜 및 시간을 지정한다. 입력 형식은 -F 옵션의 DATE 와 같다.
$ cubrid_replay -I testhost -P 33000 -d testdb -u dba -r testdb_1_11_1.sql.log.bak output.txt
위의 명령을 실행하면 실행 결과의 요약 정보가 화면에 출력된다.
------------------- Result Summary --------------------------
* Total queries : 153103
* Skipped queries (see skip.sql) : 5127
* Error queries (see replay.err) : 30
* Slow queries (time diff > 0.000 secs) : 89987
* Max execution time diff : 0.016
* Avg execution time diff : -0.001
cubrid_replay run time : 245.308417 sec
- Total queries: 날짜 및 시간이 지정된 범위 안의 전체 질의 개수. DDL, DML을 포함
- Skipped queries: -r 옵션이 사용되었을 때 UPDATE/DELETE 문을 SELECT 문으로 변환할 수 없는 질의 개수. 이 질의는 skip.sql 파일에 기록됨
- Slow queries: -D 옵션의 설정 값보다 수행 시간의 차이가 더 큰(재생된 실행 시간이 기존 실행 시간에 설정한 값을 더한 것보다 느린) 질의 개수. -D 옵션을 생략하면 0.01초를 기본으로 설정함.
- Max execution time diff: 수행 시간의 차이 중 가장 큰 값(단위: 초)
- Avg execution time diff: 수행 시간의 차이의 평균 값(단위: 초)
- cubrid_replay run time: 유틸리티의 수행 시간
"Skipped queries"는 내부 요인에 의해 UPDATE/DELETE 문에서 SELECT 문으로 질의 변환이 불가능한 경우로, skip.sql 파일에 기록된 질의문의 성능에 대해서는 별도로 확인해볼 필요가 있다.
또한, 변환된 질의문의 수행 시간은 데이터 변경 시간이 빠진 것임을 감안해야 한다.
output.txt 파일에는 SQL 로그의 수행 시간보다 재생된 SQL 수행 시간이 더 느린 SQL부터 정렬되어 기록된다. 즉, {(재생된 SQL 수행 시간) - {(SQL 로그의 수행 시간) + (-D 옵션 설정 시간)}}이 내림차순으로 정렬되어 기록된다. "-r" 옵션이 사용되었으므로 UPDATE/DELETE 문은 SELECT 문으로 재작성되어 실행된다.
EXEC TIME (REPLAY / SQL_LOG / DIFF): 0.003 / 0.001 / 0.002
SQL: UPDATE NDV_QUOTA_INFO SET last_mod_date = now() , used_quota = ( SELECT IFNULL(sum(file_size),0) FROM NDV_RECYCLED_FILE_INFO WHERE user_id = ? ) + ( SELECT IFNULL(sum(file_size),0) FROM NDV_FILE_INFO WHERE user_id = ? ) WHERE user_id = ? /+shard_val(6900403)/ /* SQL : NDVMUpdResetUsedQuota */
REWRITE SQL: select NDV_QUOTA_INFO, class NDV_QUOTA_INFO, cast( SYS_DATETIME as datetime), cast((select ifnull(sum(NDV_RECYCLED_FILE_INFO.file_size), 0) from NDV_RECYCLED_FILE_INFO NDV_RECYCLED_FILE_INFO where (NDV_RECYCLED_FILE_INFO.user_id= ?:0 ))+(select ifnull(sum(NDV_FILE_INFO.file_size), 0) from NDV_FILE_INFO NDV_FILE_INFO where (NDV_FILE_INFO.user_id= ?:1 )) as bigint) from NDV_QUOTA_INFO NDV_QUOTA_INFO where (NDV_QUOTA_INFO.user_id= ?:2 )
BIND 1: 'babaemo'
BIND 2: 'babaemo'
BIND 3: 'babaemo'
- EXEC TIME: (재생 시간 / SQL 로그에서의 수행 시간 / 두 수행 시간의 차이)
- SQL: 브로커의 SQL 로그에 존재하는 원본 SQL
- REWRITE SQL: -r 옵션이 지정되어 UPDATE 또는 DELETE 문에서 변환된 SELECT 문
Note
broker_log_runner는 9.3 버전부터 제거될 예정(deprecated)이므로, cubrid_replay를 대신 사용하도록 한다.
CAS 에러¶
CAS 에러는 브로커 응용 서버(CAS) 프로세스에서 발생하는 에러로, 드라이버를 이용하여 CAS에 접속하는 모든 응용 프로그램에서 발생할 수 있다.
다음은 CAS에서 발생하는 에러 코드를 정리한 표이다. 같은 에러 번호에 대해 CCI와 JDBC의 에러 메시지가 서로 다르게 나타날 수 있다. 에러 메시지가 하나만 있으면 같은 것이며, 두 개가 있는 경우 앞에 있는 것이 CCI 에러 메시지, 뒤에 있는 것이 JDBC 에러 메시지이다.
| 에러 코드명 | 에러 메시지 (CCI / JDBC) | 비고 |
|---|---|---|
| CAS_ER_INTERNAL | ||
| CAS_ER_NO_MORE_MEMORY | Memory allocation error | |
| CAS_ER_COMMUNICATION | Cannot receive data from client / Communication error | |
| CAS_ER_ARGS | Invalid argument | |
| CAS_ER_TRAN_TYPE | Invalid transaction type argument / Unknown transaction type | |
| CAS_ER_SRV_HANDLE | Server handle not found / Internal server error | |
| CAS_ER_NUM_BIND | Invalid parameter binding value argument / Parameter binding error | 바인딩할 데이터 수가 전송할 데이터 수와 일치하지 않음. |
| CAS_ER_UNKNOWN_U_TYPE | Invalid T_CCI_U_TYPE value / Parameter binding error | |
| CAS_ER_DB_VALUE | Cannot make DB_VALUE | |
| CAS_ER_TYPE_CONVERSION | Type conversion error | |
| CAS_ER_PARAM_NAME | Invalid T_CCI_DB_PARAM value / Invalid database parameter name | 시스템 파라미터 이름이 유효하지 않음 |
| CAS_ER_NO_MORE_DATA | Invalid cursor position / No more data | |
| CAS_ER_OBJECT | Invalid oid / Object is not valid | |
| CAS_ER_OPEN_FILE | Cannot open file / File open error | |
| CAS_ER_SCHEMA_TYPE | Invalid T_CCI_SCH_TYPE value / Invalid schema type | |
| CAS_ER_VERSION | Version mismatch | DB 서버 버전과 클라이언트(CAS) 버전이 호환되지 않음. |
| CAS_ER_FREE_SERVER | Cannot process the request. Try again later | 응용 프로그램의 연결요청을 처리할CAS를 할당할 수 없음. |
| CAS_ER_NOT_AUTHORIZED_CLIENT | Authorization error | 접근을 불허함. |
| CAS_ER_QUERY_CANCEL | Cannot cancel the query | |
| CAS_ER_NOT_COLLECTION | The attribute domain must be the set type | |
| CAS_ER_COLLECTION_DOMAIN | Heterogeneous set is not supported / The domain of a set must be the same data type | |
| CAS_ER_NO_MORE_RESULT_SET | No More Result | |
| CAS_ER_INVALID_CALL_STMT | Illegal CALL statement | |
| CAS_ER_STMT_POOLING | Invalid plan | |
| CAS_ER_DBSERVER_DISCONNECTED | Cannot communicate with DB Server | |
| CAS_ER_MAX_PREPARED_STMT_COUNT_EXCEEDED | Cannot prepare more than MAX_PREPARED_STMT_COUNT statements | |
| CAS_ER_NOT_IMPLEMENTED | None / Attempt to use a not supported service | |
| CAS_ER_MAX_CLIENT_EXCEEDED | Proxy refused client connection. max clients exceeded | |
| CAS_ER_IS | None / Authentication failure |
매니저 서버¶
CUBRID 매니저 서버 구동¶
CUBRID 매니저 서버를 구동하기 위하여 다음과 같이 입력한다.
% cubrid manager start
이미 CUBRID 매니저 서버가 구동 중에 있다면 다음과 같은 메시지가 출력된다.
% cubrid manager start
@ cubrid manager server start
++ cubrid manager server is running.
CUBRID 매니저 서버 종료¶
CUBRID 매니저 서버를 종료하기 위하여 다음과 같이 입력한다.
% cubrid manager stop
@ cubrid manager server stop
++ cubrid manager server stop: success
CUBRID 매니저 서버 로그¶
CUBRID 매니저 서버와 관련된 로그는 설치 디렉터리의 log/manager 디렉터리에 저장되며, 매니저 서버 프로세스에 따라 다음과 같이 네 종류의 로그 파일로 저장된다.
- cub_auto.access.log : 서버에 로그인, 로그 아웃을 정상적으로 수행한 클라이언트의 접속 로그
- cub_auto.error.log : 서버에 로그인, 로그 아웃을 실패한 클라이언트의 접속 로그
- cub_js.access.log : 매니저 서버에 의해 처리된 작업에 관한 로그
- cub_js.error.log : 매니저 서버에 의해 작업 처리 도중 발생한 에러에 관한 로그
CUBRID 매니저 서버 환경 설정¶
CUBRID 매니저 서버의 환경 설정 파일은 $CUBRID/conf 에 위치하며, 파일 이름은 cm.conf 이다. CUBRID 매니저 서버의 환경 설정 파일에서 주석은 "#"으로 처리되며, 매개 변수 이름과 값이 저장된다. 매개 변수 이름과 값 사이에는 공백 또는 등호 부호(=)로 구분한다.
cm.conf 에서 설정할 수 있는 매개 변수는 다음과 같다.
cm_port
CUBRID 매니저 서버와 클라이언트 사이의 통신 포트를 설정하는 매개 변수로, 기본값은 8001 로 설정된다. cm_port 는 cub_auto 가 사용하는 포트이며, cm_js 는 자동으로 cm_port 로 설정한 값보다 1만큼 큰 값을 사용한다. 예를 들어, cm_port 가 8001로 설정된 경우 cub_auto 는 8001 포트를 사용하고, cub_js 는 8002 포트를 사용한다. 따라서 방화벽이 설정된 환경에서 CUBRID 매니저를 구동하려면 반드시 실제로 사용되는 두 개의 포트를 열어야 한다.
monitor_interval
cub_auto 의 모니터링 주기를 초 단위로 설정하는 매개 변수로, 기본값은 5 이다.
allow_user_multi_connection
CUBRID 매니저 서버에 클라이언트가 중복 접속하는 것을 허용하기 위한 매개 변수로, 기본값은 YES 이다. 따라서 CUBRID 매니저 서버에는 두 개 이상의 CUBRID 매니저 클라이언트가 접속할 수 있으며, 같은 사용자 이름으로 접속할 수도 있다.
server_long_query_time
서버의 진단 항목 중 slow_query 항목을 설정할 경우 몇 초 이상을 늦은 질의로 판별할지 결정하는 매개 변수로, 기본 값은 10 이다. 서버에서 수행된 질의 수행 시간이 매개 변수 설정 값보다 큰 경우, slow_query 의 개수가 증가한다.
cm_target
브로커와 데이터베이스 서버가 분리된 구조에서 매니저의 메뉴를 해당 서비스에 맞게 출력할 목적으로 지원되는 매개 변수이다. 기본값은 브로커와 데이터베이스 서버가 같이 설치되어 있는 환경을 의미하며, 다음과 같이 설정할 수 있다.
- cm_target broker, server: 브로커와 데이터베이스 서버가 같이 있을 경우
- cm_target broker: 브로커만 있을 경우
- cm_target server: 데이터베이스 서버만 있을 경우
브로커만 설정하면 매니저에서 브로커 관련 메뉴만 출력되고, 데이터베이스 서버만 설정하면 서버 관련 메뉴만 출력된다.
탐색 트리에서 호스트를 마우스 오른쪽 버튼 클릭하고 [속성]을 선택하면, 설정된 정보를 [호스트 정보]에서 확인할 수 있다.
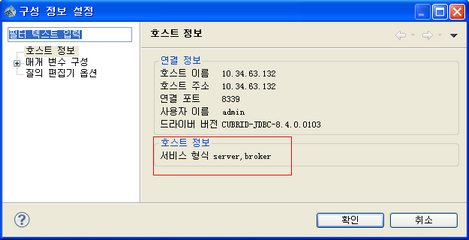
CUBRID 매니저 사용자 관리 콘솔¶
CUBRID 매니저 사용자의 계정과 비밀번호는 CUBRID 매니저 클라이언트 구동을 시작할 때 CUBRID 매니저 서버에 접속하기 위해 사용하는 것이며, 데이터베이스 사용자와는 다른 개념이다. CUBRID 매니저 관리자(cm_admin)는 사용자 정보를 관리하는 CLI 도구로, 콘솔 창에서 명령어를 실행하여 사용자를 관리한다. 이 유틸리티는 Linux OS만 지원한다.
다음은 CUBRID 매니저(이하 CM) 관리자 유틸리티 구문 사용법이다. 아래 기능은 CUBRID 매니저 클라이언트에서 GUI를 통해 사용할 수도 있다.
cm_admin <utility_name>
<utility_name>:
adduser [<option>] <cmuser-name> <cmuser-password> --- CM 사용자 추가
deluser <cmuser-name> --- CM 사용자 삭제
viewuser [<cmuser-name>] --- CM 사용자 정보 출력
changeuserauth [<option>] <cmuser-name> --- CM 사용자 권한 변경
changeuserpwd [<option>] <cmuser-name> --- CM 사용자 비밀번호 변경
adddbinfo [<option>] <cmuser-name> <database-name> --- CM 사용자의 데이터베이스 정보 추가
deldbinfo <cmuser-name> <database-name> --- CM 사용자의 데이터베이스 정보 삭제
changedbinfo [<option>] <database-name> number-of-pages --- CM 사용자의 데이터베이스 정보 변경
CM 사용자
CM 사용자 정보는 다음과 같은 정보로 구성된다.
- CM 사용자 권한: 다음과 같은 권한 정보를 포함한다.
- 브로커 권한
- 데이터베이스 생성 권한. 현재는 admin 사용자만 이 권한을 가질 수 있다.
- 상태 모니터링 권한
- 데이터베이스 정보: CM 사용자가 사용할 수 있는 데이터베이스
- CM 사용자 비밀번호
CUBRID 매니저의 기본 사용자는 모든 관리 권한을 가진 admin 사용자이며 기본 비밀번호는 admin이다.
CM 사용자 추가
cm_admin adduser 유틸리티는 특정 권한과 데이터베이스 정보를 갖는 CM 사용자를 생성한다. 브로커 권한, 데이터베이스 생성 권한 및 상태 모니터링 권한 등을 CM 사용자에게 부여할 수 있다.
cm_admin adduser [options] cmuser-name cmuser-password
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- adduser: 새 CM 사용자를 생성하는 명령어
- cmuser-name: 생성할 CM 사용자의 고유한 이름을 지정한다. 사용 가능한 문자는 0~9, A~Z, a~z, _이며 최소 4자, 최대 32자이다. 지정한 cmuser-name이 기존 cmuser-name과 같으면 cm_admin은 CM 사용자 생성을 중지한다.
- cmuser-password: 생성할 CM 사용자의 비밀번호이다. 사용 가능한 문자는 0~9, A~Z, a~z, _이며 최소 4자, 최대 32자이다.
다음은 cm_admin adduser 에 대한 [options]이다.
-b,--brokerAUTHORITY¶생성할 CM 사용자의 브로커 권한을 지정한다. 사용할 수 있는 값은 admin, none, monitor 이며, 기본값은 none 이다.
다음은 이름이 testcm 이고 비밀번호가 testcmpwd 인 CM 사용자를 생성하고 브로커 권한을 monitor로 설정하는 예이다.
cm_admin adduser -b monitor testcm testcmpwd
-c,--dbcreateAUTHORITY¶생성할 CM 사용자의 데이터베이스 생성 권한을 지정한다. 사용할 수 있는 값은 none, admin 이며, 기본값은 none 이다.
다음은 이름이 testcm 이고 비밀번호가 testcmpwd 인 CM 사용자를 생성하고 데이터베이스 생성 권한을 admin으로 설정하는 예이다.
cm_admin adduser -c admin testcm testcmpwd
-m,monitorAUTHORITY¶생성할 CM 사용자의 모니터링 권한을 지정한다. 사용할 수 있는 값은 admin, none, monitor 이며, 기본값은 none 이다.
다음은 이름이 testcm 이고 비밀번호가 testcmpwd 인 CM 사용자를 생성하고 상태 모니터링 권한을 admin으로 설정하는 예이다.
cm_admin adduser -m admin testcm testcmpwd
-d,--dbinfoSTRING¶생성할 CM 사용자의 데이터베이스 정보를 지정한다. DBINFO는 "<dbname>;<uid>;<broker_ip>,<broker_port>"의 형식으로 지정해야 한다.
다음은 이름이 testcm 인 CM 사용자에게 "testdb;dba;localhost,30000"이라는 데이터베이스 정보를 추가하는 예이다.
cm_admin adduser -d "testdb;dba;localhost,30000" testcm testcmpwd
CM 사용자 삭제
cm_admin deluser 유틸리티는 지정한 CM 사용자 이름을 기준으로 CM 사용자를 삭제한다.
cm_admin deluser cmuser-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- deluser: 기존 CM 사용자를 삭제하는 명령어
- cmuser-name: 삭제할 CM 사용자 이름
다음은 이름이 testcm 인 CM 사용자를 삭제하는 예이다.
cm_admin deluser testcm
CM 사용자 정보 출력
cm_admin viewuser 유틸리티는 지정한 CM 사용자 이름을 기준으로 CM 사용자를 삭제한다.
cm_admin viewuser cmuser-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- viewuser: CM 사용자의 권한 및 데이터베이스 정보를 출력하는 명령어
- cmuser-name: CM 사용자 이름. 이 값을 입력하면 해당 사용자의 정보만 출력하고, 생략하면 모든 기존 CM 사용자 정보를 표시한다.
다음은 이름이 testcm 인 CM 사용자의 정보를 출력하는 예이다.
cm_admin viewuser testcm다음과 같이 정보가 출력된다.
CM USER: testcm Auth info: broker: none dbcreate: none statusmonitorauth: none DB info: ========================================================================================== DBNAME UID BROKER INFO ========================================================================================== testdb dba localhost,30000
CM 사용자 권한 변경
cm_admin changeuserauth 유틸리티는 CM 사용자의 권한을 변경한다.
cm_admin changeuserauth [options] cmuser-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- changeuserauth: CM 사용자의 권한 정보를 변경하는 명령어
- cmuser-name: 권한을 변경할 CM 사용자의 이름
cm_admin changeuserauth 에서 사용하는 [options]는 다음과 같다.
-b,--broker¶CM 사용자의 브로커 권한을 지정한다. 사용할 수 있는 값은 admin, none, monitor 이다.
다음은 이름이 testcm 인 CM 사용자의 브로커 권한을 monitor 로 변경하는 예이다.
cm_admin changeuserauth -b monitor testcm
-c,--dbcreate¶CM 사용자의 데이터베이스 생성 권한을 지정한다. 사용할 수 있는 값은 none, admin 이다.
다음은 이름이 testcm 인 CM 사용자의 데이터베이스 생성 권한을 admin 으로 변경하는 예이다.
cm_admin changeuserauth -c admin testcm
-m,--monitor¶CM 사용자의 모니터링 권한을 지정한다. 사용할 수 있는 값은 admin, none, monitor 이다.
다음은 이름이 testcm 인 CM 사용자의 상태 모니터링 권한을 admin 으로 변경하는 예이다.
cm_admin changeuserauth -m admin testcm
CM 사용자 비밀번호 변경
cm_admin changeuserpwd 유틸리티는 CM 사용자의 비밀번호를 변경한다.
cm_admin changeuserpwd [options] cmuser-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- changeuserpwd: CM 사용자의 비밀번호를 변경하는 명령어
- cmuser-name: 비밀번호를 변경할 CM 사용자의 이름
cm_admin changeuserpwd 에서 사용하는 [options]는 다음과 같다.
-o,--oldpassPASSWORD¶CM 사용자의 이전 비밀번호를 지정한다.
다음은 이름이 testcm 인 CM 사용자의 비밀번호를 변경하는 예이다.
cm_admin changeuserpwd -o old_password -n new_password testcm
--adminpassPASSWORD¶사용자의 이전 비밀번호를 모를 때 admin 의 비밀번호를 대신 지정할 수 있다.
다음은 admin 비밀번호를 사용하여 이름이 testcm 인 CM 사용자의 비밀번호를 변경하는 예이다.
cm_admin changeuserauth --adminpass admin_password -n new_password testcm
-n,--newpassPASSWORD¶CM 사용자의 새 비밀번호를 지정한다.
CM 사용자의 데이터베이스 정보 추가
cm_admin adddbinfo 유틸리티는 데이터베이스 정보(데이터베이스 이름, UID, 브로커 IP 및 브로커 포트)를 CM 사용자에게 추가한다.
cm_admin adddbinfo [options] cmuser-name database-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- adddbinfo: CM 사용자에게 데이터베이스 정보를 추가하는 명령어
- cmuser-name: CM 사용자 이름
- databse-name: 추가할 데이터베이스 이름
다음은 이름이 testcm 인 CM 사용자에게 이름이 testdb 이고 기본값을 사용하는 데이터베이스를 추가하는 예이다.
cm_admin adddbinfo testcm testdb다음은 cm_admin adddbinfo 에서 사용하는 [options]이다.
-u,--uidID¶추가할 데이터베이스의 사용자 ID를 지정한다. 기본값은 dba 이다.
다음은 이름이 testcm 인 CM 사용자에게 이름이 testdb 이고 사용자 ID가 cubriduser 인 데이터베이스를 추가하는 예이다.
cm_admin adddbinfo -u cubriduser testcm testdb
-h,--hostIP¶클라이언트가 데이터베이스에 접속할 때 사용하는 브로커의 호스트 IP를 지정한다. 기본값은 localhost 이다.
다음은 이름이 testcm 인 CM 사용자에게 이름이 testdb 이고 호스트 IP가 127.0.0.1 인 데이터베이스를 추가하는 예이다.
cm_admin adddbinfo -h 127.0.0.1 testcm testdb
-p,--portNUMBER¶클라이언트가 데이터베이스에 접속할 때 사용하는 브로커의 포트 번호를 지정한다. 기본값은 30000 이다.
CM 사용자의 데이터베이스 정보 삭제
cm_admin deldbinfo 유틸리티는 지정한 CM 사용자의 데이터베이스 정보를 삭제한다.
cm_admin deldbinfo cmuser-name database-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- deldbinfo: CM 사용자의 데이터베이스 정보를 삭제하는 명령어
- cmuser-name: CM 사용자 이름
- databse-name: 삭제할 데이터베이스 이름
다음은 이름이 testcm 인 CM 사용자에게서 이름이 testdb 인 데이터베이스 정보를 삭제하는 예이다.
cm_admin deldbinfo testcm testdb
CM 사용자의 데이터베이스 정보 변경
cm_admin changedbinfo 유틸리티는 지정한 CM 사용자의 데이터베이스 정보를 변경한다.
cm_admin changedbinfo [options] cmuser-name database-name
- cm_admin: CUBRID 매니저를 관리하는 통합 유틸리티
- changedbinfo: CM 사용자의 데이터베이스 정보를 변경하는 명령어
- <cmuser-name>: CM 사용자 이름
- <databse-name>: 변경할 데이터베이스 이름
다음은 cm_admin changedbinfo 에서 사용하는 [options]이다.
-u,--uidID¶데이터베이스의 사용자 ID를 지정한다.
다음은 이름이 testcm 인 CM 사용자의 testdb 데이터베이스에서 사용자 ID 정보를 uid 로 업데이트하는 예이다.
cm_admin changedbinfo -u uid testcm testdb
-h,--hostIP¶클라이언트가 데이터베이스에 접속할 때 사용하는 브로커의 호스트를 지정한다.
다음은 이름이 testcm 인 CM 사용자의 testdb 데이터베이스에서 호스트 IP 정보를 10.34.63.132 로 업데이트하는 예이다.
cm_admin changedbinfo -h 10.34.63.132 testcm testdb
-p,--portNUMBER¶클라이언트가 데이터베이스에 접속할 때 사용하는 브로커의 포트 번호를 지정한다.
다음은 이름이 testcm 인 CM 사용자의 testdb 데이터베이스에서 브로커 포트 정보를 33000 로 업데이트하는 예이다.
cm_admin changedbinfo -p 33000 testcm testdb