
2.1 CONFIGURING THE DATABASE SERVER
2.1.1 Cubrid_port_id
2.1.2 Ha_mode
2.1.3 Ha_port_id
2.1.4 Ha_node_list
2.2 CREATING A NEW DATABASE TO RUN ON HA MODE
2.3 SETTING DATABASE HOST INFORMATION
2.4 DNS CONFIGURATION
3. HA SET-UP
3.1 CUBRID-HA UTILITY
3.2 START HA SYSTEM
3.3 EXECUTE A TEST QUERY ON MASTER NODE
3.4 HA PROCESSES
4. HA-NODE
4.1 HA-NODE STATUS
4.2 FAIL-OVER
4.3 FAIL-BACK
5.1 HA SERVER
1. CUBRID HA overview
Refer to the online document.
2. HA Configuration
2.1 Configuring the Database Server
2.1.1 Cubrid_port_id
This parameter configures the port to be used by the master process. The default value is 1,523. The master process creates a listening socket on this port. The “copylogdb” processes on other hosts will connect to this port to establish connections with some local HA Server. Then the transaction logs can be transferred by this port. So the “cubrid_port_id” value of all hosts in the same HA system should be the same.
2.1.2 Ha_mode
To use the HA feature, you should set the ha_mode parameter to “on” or “yes” in the [common] section of the “cubrid.conf” file. If the ha_mode parameter does not set, the default value is off. Then, it runs as a general server without the HA feature.
#Enable HA ha_mode=on
All databases that start after the ha_mode parameter are set to “on” are in HA mode. If you don’t want some database to be in HA mode, you can set “ha_mode=off” in section [@your_dbname]. For example:
[@demodb] ha_mode=off
Remember that if the “ha_mode” is “off” in [common] section, you can’t set “ha_mode” to “on” in [@your_dbname] section. When the server starts, there will be an error message to inform you. The configuration below is invalid:
[common] ... ha_mode=off ... [@demodb] #Invalid configuration ha_mode=on
2.1.3 Ha_port_id
HA node uses heartbeat(hb) to check the availability of other HA nodes, and provides failover, failback and monitoring functionalities. All HA nodes in the same HA system use the same UDP port to communicate with each other. The ha_port_id parameter in the [common] section of the “cubrid .conf” file indicates the UDP port. The default value is 59901. All the “ha_port_id” in the same HA system should be the same value.
#Heartbeat UDP port ha_port_id=59901
Ensure that different HA system in the same host uses different ha_port_id value.
2.1.4 Ha_node_list
The hostname of all the HA nodes should be listed in “ha_node_list” in the [common] section of the “cubrid.conf” file. There must be a user that available on all hosts, which allows cubrid access other hosts use the same ha group name which identifies CUBRID HA. The “ha_node_list” is just like this:
ha_node_list=ha_groupname@hostname1:hostname2: ...
- The default value of “ha_node_list” is empty (“”).
Note: The hostname in “ha_node_list” cannot be replaced by its corresponded IP value. When specifying the hostname list, the current hostname should be included in the list so that you can start CUBRID HA on the current node. In addition, hostname with its mapping IP address (DNS setting) should be registered first in /stc/hosts/.
2.2 Creating a new database to run on HA mode
You can create a new database for HA configuration. The option of the “cubrid createdb” utility can be properly specified. For example:
[master]$ cd $CUBRID_DATABASES [master]$ mkdir demodb [master]$ cd demodb [master]$ mkdir log [master]$ cubrid createdb -L ./log demodb en_US.utf8 CUBRID 10.2 [master]$
2.3 Setting Database Host Information
You need to add the host information of both Active and the Standby servers in the HA configuration to the database location file (databases.txt). A colon (:) separates the Active and the Standby servers. More than one Standby server can be added with each host being separated by a colon (:). For example:
#db-name vol-path db-host log-path demodb /home/cubrid/DB/demodb master:slave /home1/cubrid1/DB/demodb/log
2.4 DNS configuration
The HA node use hostname to communicate with each other, so DNS service must be provided to give the corresponded IP value of hostname. As a simple solution, you can configure this information in /etc/hosts. For example:
127.0.0.1 localhost.localdomain localhost 192.168.51.1 cubrid1 192.168.51.2 cubrid2
3. HA Set-up
3.1 Cubrid-HA Utility
The usage of this utility is just like this:
usage: cubrid heartbeat <command> [args] Available command: start [database-name] stop [-h <host-name>] [-i] [database-name] copylogdb <start|stop> [-h <host-name>] database-name node- name applylogdb <start|stop> [-h <host-name>] database-name node-name replication <start|stop> node-name status [-v] [-h <host-name>] reload
3.2 Start HA system
If you have completed all configurations on active and standby servers, you can use cubrid hb to start HA system on each HA-Node and the node you execute ‘cubrid hb start’ firstly will be a master node:
<master node>
[master]$ cubrid hb start @ cubrid heartbeat start @ cubrid master start ++ cubrid master start: success @ HA processes start @ cubrid server start: demodb This may take a long time depending on the amount of recovery works to do. CUBRID 10.2 ++ cubrid server start: success @ copylogdb start ++ copylogdb start: success @ applylogdb start ++ applylogdb start: success ++ HA processes start: success ++ cubrid heartbeat start: success
<slave node>
[slave]$ cubrid hb start @ cubrid heartbeat start @ cubrid master start ++ cubrid master start: success @ HA processes start @ cubrid server start: demodb This may take a long time depending on the amount of recovery works to do. CUBRID 10.2 ++ cubrid server start: success @ copylogdb start ++ copylogdb start: success @ applylogdb start ++ applylogdb start: success ++ HA processes start: success ++ cubrid heartbeat start: success
After HA system starts successfully, you can run “cubrid hb status” to check the status of HA-Node and HA-Process. The “cubrid hb status” use “cubrid heartbeat list” to get the status, so you can also use the “cubrid heartbeat list” instead. For example:
[master]$ cubrid hb status @ cubrid heartbeat status HA-Node Info (current cubrid1, state master) Node cubrid2 (priority 2, state slave) Node cubrid1 (priority 1, state master) HA-Process Info (master 28365, state master) Applylogdb demodb@localhost:/home/cubrid/CUBRID/databases/demodb_cubrid2 (pid 28660, state registered) Copylogdb demodb@cubrid2:/home/cubrid/CUBRID/databases/demodb_cubrid2 (pid 28658, state registered) Server demodb (pid 28374, state registered_and_active) [ OK ] [master]$
Note: The CUBRID between 64bit host and 32bit host can’t communicate correctly.
You can run “cubrid changemode” utility to check the current HA mode on each server node. For example:
<master node>
[master]$ cubrid changemode demodb@localhost The server `demodb@localhost''s current HA running mode is active.
<slave node>
[slave]$ cubrid changemode demodb@localhost The server `demodb@localhost''s current HA running mode is standby.
Remember that “active” doesn’t actually mean that the HA Server’s status is “active”. It only shows that it tries to change the server mode to “active”. And the server’s status may be “to-be-active”.
3.3 Execute a test query on master node
You can finally test if changes in the master database are reflected to the slave correctly. Remember that CUBRID HA replication is based on using a primary key therefore a primary key should be defined in your tables.
<master node>
[master]$ csql -u dba demodb@localhost -c "create table abc(a int, b int, c int, primary key(a));" [master]$ csql -u dba demodb@localhost -c "insert into abc values (1,1,1);" [master]$
<slave node>
[slave]$ csql -u dba demodb@localhost -l -c "select * from abc;"
=== <Result of SELECT Command in Line 1> ===
<00001> a: 1
b: 1
c: 1
[slave]$
3.4 HA Processes
If the HA system has been set-up successfully, the structure of the system will be:

On each node, processes “cub_server”, “applylogdb”, “copylogdb” are registered in cub_master. The “copylogdb” process copy and establishes a connection with “cub_server” on other nodes; and it also copies transaction logs to local directory. The “applylogdb” process applies transaction logs to local database by commit requests to “cub_server”.
Note: In fact, before you start “cub_server”, or before you use “applylogdb” or “copylogdb”, you must start “cub_master” first. Otherwise, error message will be printed out.
You can use netstat utility to check the connection status:
tcp 0 0 0.0.0.0:1523 0.0.0.0:* LISTEN 28365/cub_master tcp 0 0 0.0.0.0:8001 0.0.0.0:* LISTEN 28688/cub_manager tcp 0 0 0.0.0.0:33000 0.0.0.0:* LISTEN 28672/cub_broker tcp 0 0 172.31.201.15:54034 172.31.202.15:1523 ESTABLISHED 28658/cub_admin tcp 0 0 172.31.201.15:1523 172.31.202.15:49532 ESTABLISHED 28374/cub_server
4. HA-Node
4.1 HA-Node Status
There are three statuses about HA-Node: master, slave, and unknown. The HA Server status on master node is active while is standby on slave node.
The HA-Node that starts first will be the master node. The factor in determining which is the master node does not include the host order in “ha_node_list”. When a HA-Node starts, its initial status is slave. If it is the only existing node, it will turn the status to master by itself. The HA Serve status on this node will turn from standby to to-be-active or active.
4.2 Fail-Over
Fail-Over allows a standby server to perform the failover automatically and continue to provide services when the failure of an active server or the failure of the system which runs the active server is detected. If master node fails or stops, the first slave status node in the db-host section of “databases.txt” will be the new master node.
4.3 Fail-Back
Fail-Back allows the restored active server to resume services after the failover when it is restored to the original state.
5. Server Status
5.1 HA Server
HA Server statuses are showed blew:
| Status | Explannation |
| Idle | HA Server does not start. |
| Active | A state that provides a service for common read and write requests and creates transaction log. HA Server on master node is in this status. |
| Standby | A state that provides a service for read requests only, but denies write requests. HA Server on slave node is in this status. |
| To-be-active | When the state of the server changes from standby to active, it goes through the to-be-active stage before it becomes active. In a to-be-active state, all write requests will be denied, and the server changes to an active state after reflecting the unapplied transaction log. |
| To-be-standby | When the state of the server changes to standby, it goes through the to-be-standby stage before it becomes standby. |
| Dead | HA server crashes. |
HA Server status transition diagram is shown blew.
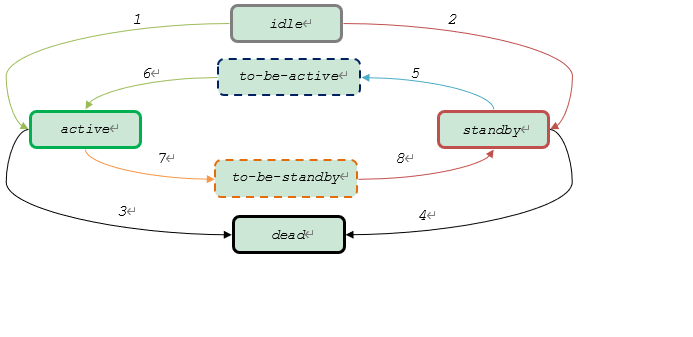
When HA Server starts, its default status is standby (2). Then cub_master may change the HA Server status by judging whether the local host is master or not.
If it is master, cub_master will try to change the HA Server’s status to active (5->6). But the transitions will success, only if:
- ha_node_list is empty, or only has one node;
- applylogdb applies transaction log to HA server successfully.
Otherwise, the transition (5->6) will fail, and HA Server will stay to-be-active forever.
If the node is slave, HA Server status will stay standby.
The transition (7->8) occurs under fail-back. Because the fail-back feature is not implemented, this transition does not occur.
 Analyzing JDBC Logs with LOG4JDBC
Analyzing JDBC Logs with LOG4JDBC
 CUBRID Log Files
CUBRID Log Files