
The scope of this tutorial is to introduce you to some of the CUBRID features regarding database triggers via some examples of creating and using triggers in CUBRID.
Overview
"A database trigger is procedural code that can be automatically executed in response to certain events on a particular table or view in a database." (http://en.wikipedia.org/wiki/Database_trigger).
- Database triggers can be very useful for:
- Controlling users' changes in the database
- Log/Auditing users' changes
- Implementing and enforcing business rules
- Performing various actions automatically
- Improving performance in client/server environment (triggers run on the server side before the results return to the client).
Nowadays, many database systems have supportted for triggers, usually using their own specific implementation of SQL-based dialects. CUBRID has an implementation which also uses SQL-based statements to define the triggers actions.
In CUBRID, we have 2 types of triggers:
- User triggers
- Table triggers
In this tutorial, we will target only on the table triggers; however, user triggers will be explained in another tutorial.
Triggers can be defined for combinations of:
- Events: INSERT, UPDATE, DELETE etc.
- Activation time: BEFORE, AFTER, DEFFERED
- Action type: REJECT, STATEMENT etc.
- Trigger target (tables)
Notes:
- CUBRID does not support VIEWs triggers.
- CUBRID supports only DML (Data Manipulation Language) triggers and not DDL triggers (a DDL trigger is a trigger that associates with events related to data definition, for example: creating a table, deleting a view, etc.)
You can find more details about triggers in the CUBRID manual: https://www.cubrid.org/manual/en/10.2/sql/trigger.html#trigger.
In this tutorial, we will assume that readers are already familiar with the basics of triggers in CUBRID and we will focus only on presenting some concrete examples of using this feature.
Setup tutorial data
Let's create the following 2 tables, to implement a very simple "virtual library":
- Authors
- Books
The relation between them is 1:0-n - for each book we can have multiple books (or no books at all) in the library.
Here are the SQL statements to execute:
CREATE TABLE "authors"(
"author_id" integer AUTO_INCREMENT,
"author_name" character varying(64) NOT NULL,
"born_date" date NOT NULL,
"books_count" SMALLINT DEFAULT 0,
"notes" character varying(1024),
CONSTRAINT pk_authors_author_id PRIMARY KEY("author_id")
);
CREATE TABLE "books"(
"author_id" integer NOT NULL,
"book_title" character varying(64) NOT NULL,
"published_date" date NOT NULL,
"version" smallint NOT NULL,
FOREIGN KEY ("author_id") REFERENCES "authors"("author_id") ON DELETE RESTRICT ON UPDATE RESTRICT
);
CREATE UNIQUE INDEX idx_books ON "books"("author_id","book_title","published_date","version");
And now, let's insert some startup data in these tables:
INSERT INTO "authors"("author_name", "born_date", "books_count") VALUES
('John Miller', TO_DATE('2/9/1960', 'DD/MM/YYYY'), 2),
('Mike Falkner', TO_DATE('5/8/1961', 'DD/MM/YYYY'), 1),
('Johnny Dex', TO_DATE('25/6/1970', 'DD/MM/YYYY'), 4),
('Joel Smith', TO_DATE('23/12/1965', 'DD/MM/YYYY'), 0),
('Eduardo Diaz', TO_DATE('15/12/1950', 'DD/MM/YYYY'), 1);
INSERT INTO "books"("author_id","book_title", "published_date", "version") VALUES
(1, 'La Luna', TO_DATE('2/9/1990', 'DD/MM/YYYY'), 1),
(1, 'La Luna', TO_DATE('5/8/1999', 'DD/MM/YYYY'), 2),
(2, 'The sun is down', TO_DATE('25/6/1990', 'DD/MM/YYYY'), 1),
(3, 'My little book', TO_DATE('23/12/1997', 'DD/MM/YYYY'), 1),
(3, 'Espana', TO_DATE('15/12/1998', 'DD/MM/YYYY'), 1),
(3, 'Delta force', TO_DATE('20/12/1999', 'DD/MM/YYYY'), 2),
(3, 'Remember me', TO_DATE('15/12/1999', 'DD/MM/YYYY'), 1),
(5, 'You and me', TO_DATE('15/12/2001', 'DD/MM/YYYY'), 1);
Before we proceed to the next sections, we remind you that it is very important, when defining triggers, to understand the relation between activation time and the new, old and obj qualifiers:
| BEFORE | AFTER | |
| INSERT | new | obj |
| UPDATE | obj new |
obj old |
| DELETE | obj |
Note: If you are unsure about how are these combinations should be used in the context of triggers, please read the CUBRID manual section dedicated to this topic, before you proceed further with the next parts of this tutorial!
A Data Update trigger
Let's start by creating a trigger which will automatically update the "notes" column for an author, when a new book is added in our library. We will need to "intercept" the INSERT operations in the "books" table and, AFTER the INSERT is done, UPDATE the "notes" column from the "authors" table.
This is the code of the trigger which performs this operation:
CREATE TRIGGER "t_update_notes"
AFTER INSERT ON "books"
EXECUTE
update authors set authors.notes= concat('A new book was released on ', obj.published_date) where authors.author_id=obj.author_id;
If you use the CUBRID Admin client to create the trigger, here is the definition of the trigger below:
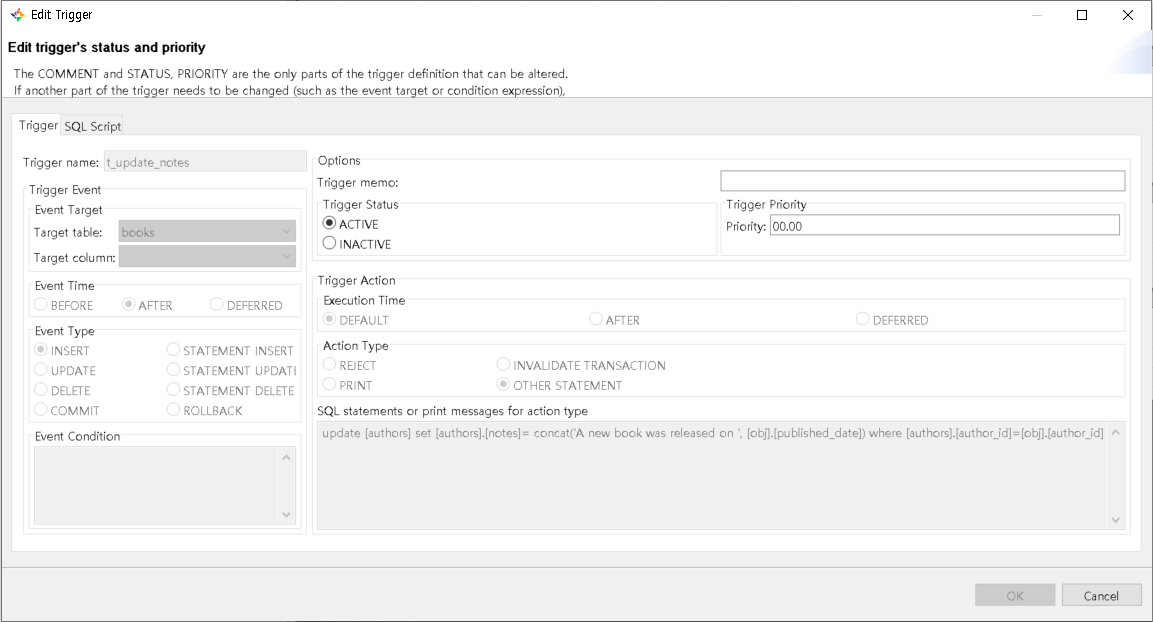
If everything goes ok, the user will be notified that the trigger was successfully created.
Now, let's add a new book in the library:
INSERT INTO "books"("author_id","book_title", "published_date", "version") VALUES
(1, 'New added book', TO_DATE('1/1/1999', 'DD/MM/YYYY'), 1);
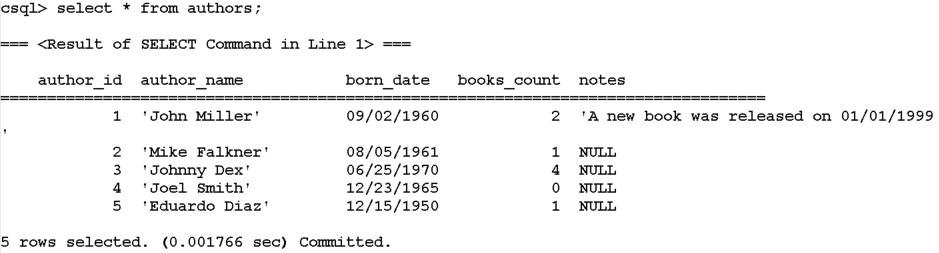
The trigger we created will intercept this action and will update the "books" table, as desired:
A Data Validation trigger
Now, we will create a trigger which will automatically verify that whenever we add a new book in our library, the "published_date" is a later date than the author "born_date". We will need to "intercept" the INSERT operations in the "books" table and, BEFORE the INSERT is done, compare the values of the date in the both tables. If the validation fails, the trigger should REJECT the INSERT.
This is the code of the trigger:
CREATE TRIGGER "t_verify_dates" BEFORE INSERT ON "books" IF new.published_date<=(select born_date from authors where author_id=new.author_id) EXECUTE REJECT;
In the CUBRID Admin client, the trigger can be created as shown below:
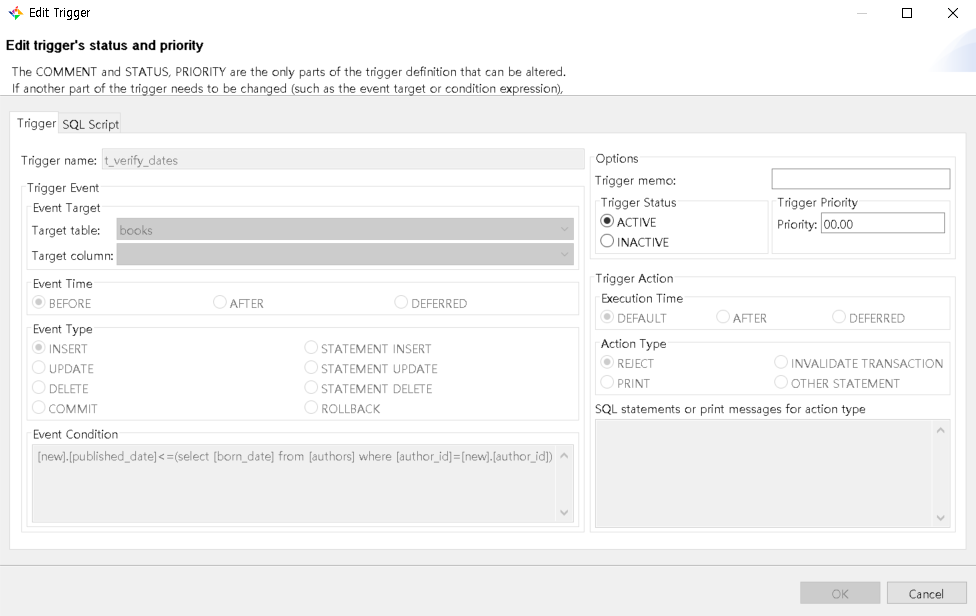
And now, let's see the trigger in action:
INSERT INTO "books"("author_id","book_title", "published_date", "version") VALUES
(1, 'New invalid book', TO_DATE('1/1/1949', 'DD/MM/YYYY'), 1);
The trigger we created has intercepted this invalid action and denied it:

The trigger canceled the INSERT, because the automatic validation we setup previously has failed.
Another Data Update trigger
Finally, we will create a trigger which will automatically update the number of books published by the author, after a book is removed (delete) from the library. We will need to "intercept" the DELETE operations in the "books" table and, AFTER the INSERT is done, UPDATE the "books_count" column in the "authors" table.
Here is the code of this trigger:
CREATE TRIGGER "t_update_books_count" AFTER DELETE ON "books" EXECUTE update authors set books_count=(select count(*) from books where books.author_id=authors.author_id);
The trigger definition in the CUBRID Admin client is:
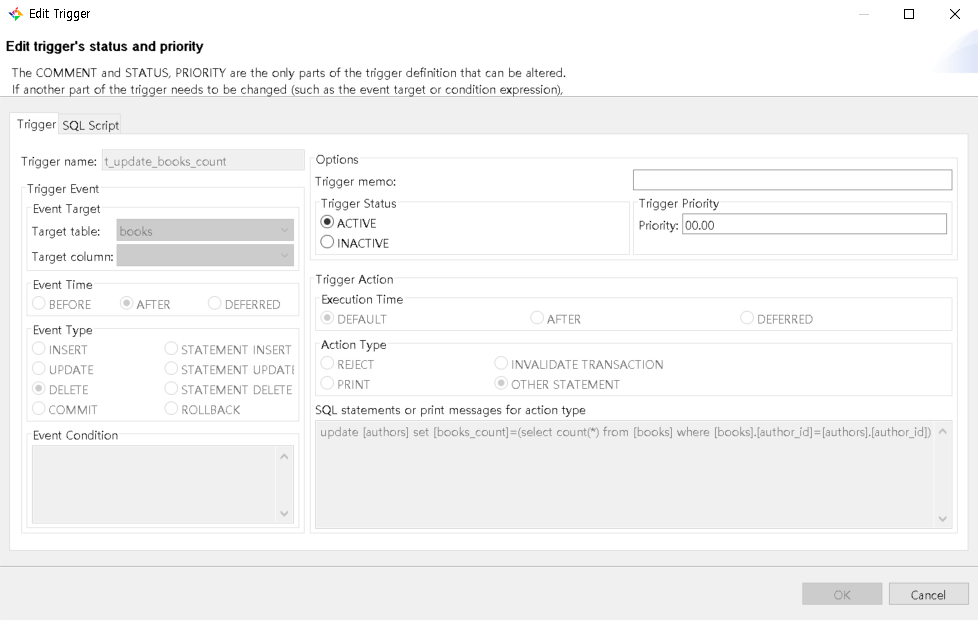
Let's test what happen when we delete a book. Let's first add a new author, with one book in the library:
INSERT INTO "authors"("author_id", "author_name", "born_date") VALUES
(10, 'John Taker', TO_DATE('2/2/1960', 'DD/MM/YYYY'));
INSERT INTO "books"("author_id","book_title", "published_date", "version") VALUES
(10, 'My book', TO_DATE('1/1/1999', 'DD/MM/YYYY'), 1);
UPDATE "authors" SET "books_count"=1 WHERE "author_id"=10;
Now, we will delete the book:
DELETE FROM "books" WHERE "author_id"=10;
The trigger we created will intercept the "books" DELETE and will update the "authors" table (will set "books_count" value to 0):
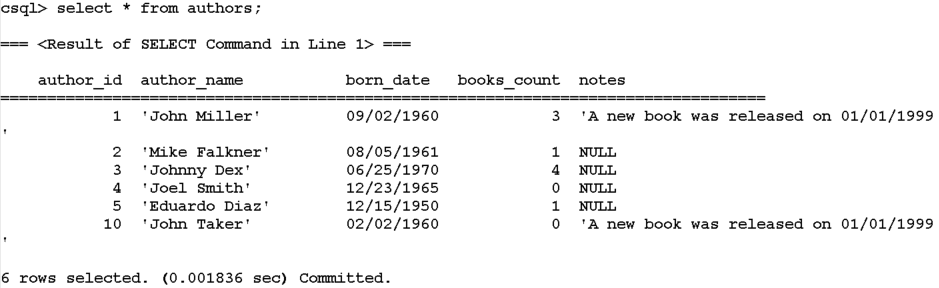
Summarizing, as you can see from the examples above, using triggers in CUBRID is not difficult at all…!
Actually, all you have to do is to know SQL, understand the triggers concept and learn how to use the CUBRID Manager interface, which will significantly simplify the management of the triggers..
Other things to know about CUBRID triggers
Enable/Disable triggers
A trigger can always be enabled or disabled. You can achieve this by using the ALTER TRIGGER statement:
ALTER TRIGGER t_update_books_count STATUS ACTIVE;
Or
ALTER TRIGGER t_update_books_count STATUS INACTIVE;
Trigger(s) priority
Triggers in CUBRID have a "special" attribute, called PRIORITY. This attribute is used whenever there are multiple triggers that will be executed for the same event, to determine the execution order. PRIORITY can have any non-negative float value, with 0 being the highest priority. If all the triggers have the same priority, the execution order is random.
You can always use the ALTER TRGGER statement to change a trigger priority:
ALTER TRIGGER t_update_books_count PRIORITY 0.9;
Note: STATUS and PRIORITY are the only trigger attributes that can be changed after the trigger was created! If you need to change other attributes of the trigger, you will need to drop the trigger and re-create it.
Trigger execution log
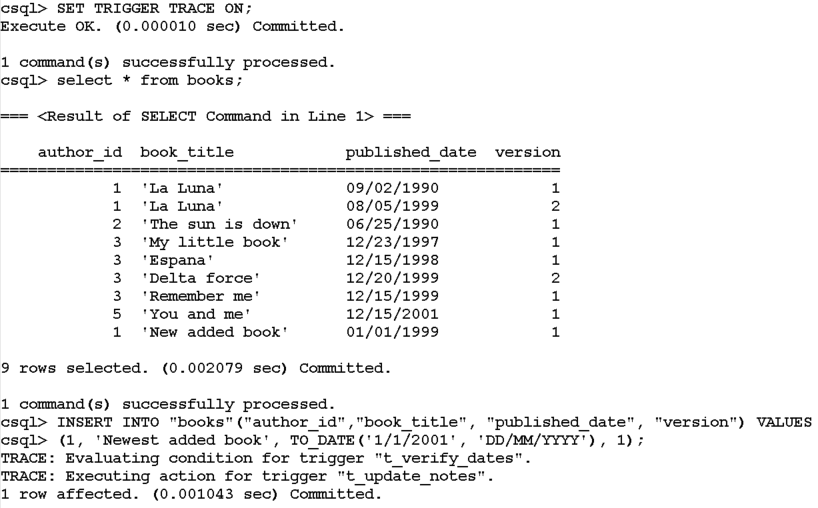
You can view the execution log of a trigger by using the SET TRIGGER TRACE statement:
SET TRIGGER TRACE ON;
Let's try this with the trigger t_update_notes:
User rights & Triggers
In CUBRID, there is no dedicated GRANT statement for triggers (like in MySQL or ORACLE. In particular, in MySQL it is the TRIGGER privilege which enables trigger operations. You must have this privilege for a table to create, drop, or execute triggers for that table).
In CUBRID the following rules apply:
- A table trigger is visible to all users who have the SELECT privilege on the trigger target table.
- To create a table trigger, the user must have an ALTER authorization on the table.
Triggers potential (down) side effects
Defining (and using) triggers, beside the many useful things they can achieve, can have possible downside effects as well, and the user should know about this, before taking any decisions regarding triggers usage.
Such potential downside effects can be:
- Database performance slow-down. Imagine that you have a trigger which runs a slow SQL statement, and the trigger is executed for each UPDATE on a heavy-traffic table/column. Such a trigger will have a significant impact on the database performance.
- Watch out for recursive triggers! Such triggers might even cause the current session close! Be very careful when defining triggers that modify the same table for which the trigger has been triggered!
- Triggers should not be used to "hide" database design flaws! Do not use triggers to replace CASCADE constraints, or FOREIGN KEY references, for example.
- Triggers are usually hard to migrate between different databases.
Summarizing, triggers are a good tool, but only when it is used properly!
Links & Resources
| CUBRID Online Manual | https://www.cubrid.org/manual/en/10.2/sql/trigger.html#trigger |
| CUBRID Presentation | http://www.slideshare.net/GrupAgora/arniacubrid-programatica2010 |
| General informaton about triggers | http://database-programmer.blogspot.com/2008/05/database-triggers-encapsulation-and.html |
This concludes the first CUBRID Triggers tutorial.
Thank you!
 Common Uses of CUBRID Node.js API with Examples
Common Uses of CUBRID Node.js API with Examples
 CUBRID Log Files
CUBRID Log Files