Written by TaeHwan Seo on 01/18/2022
CUBRID users can monitor items in CUBRID through the Scouter.
It was developed based on CUBRID 11.0 version. Full features are available from CUBRID 10.2.1 Version.
Scouter (Server, Client) is available from version 2.15.0, bug fixes and features will be added by participating in Scouter GitHub in the future.
The latest version of Scouter (as in 2022.01.18) is Scouter 2.15.0, Multi Agent support and bug fixes are currently in the PR stage.
1. What is Scouter?
Scouter is an Open Source Application Performance Management (APM), it provides monitoring function for applications and OS.
-
Scouter Basic Configuration
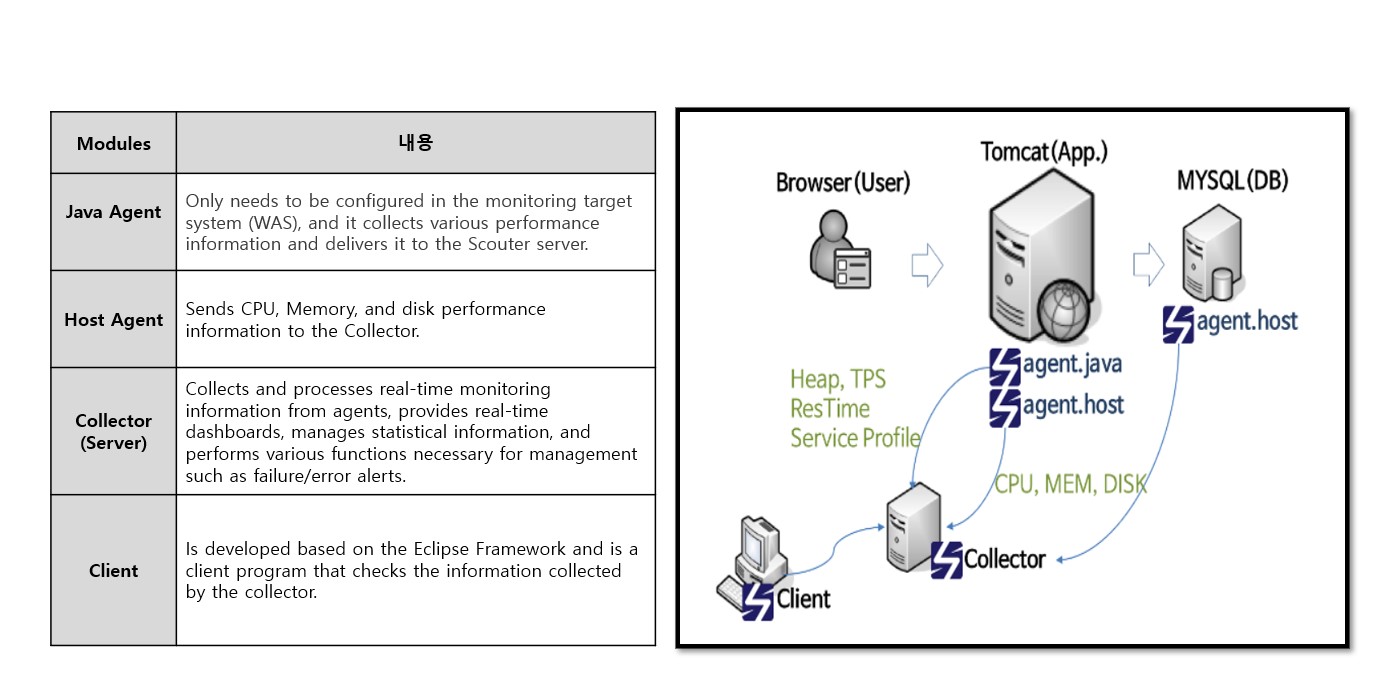
-
Scouter-provided Information
- WAS Basic Information
Response speed/profiling information for each request, number of server requests/number of responses, number of requests in process, average response speed, JVM memory usage / GC time, CPU usage.
- Profiling Information
Server-to-server request flow, execution time/statistics of each SQL query, API execution time, request header information, method invocation time.
-
Representative Agent List
- Tomcat Agent (Java Agent) : gathering profiles and performance metrics of JVM & Web application server
- Host Agent (OS Agent) : gathering performance metrics of Linux, Windows, and OSX
- MariaDB Plugin : A plugin for monitoring MariaDB (embedded in MariaDB)
- Telegraf Agent : Redis, nginX, apache httpd, haproxy, Kafka, MySQL, MongoDB, RabbitMQ, ElasticSearch, Kube, Mesos ...
2. CUBRID & Scouter
-
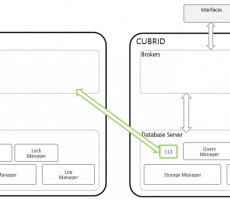
Composition

Information on CUBRID is transmitted to CUBRID Agent via CMS to HTTPS; items that are separated by item in CUBRID Agent are transmitted continuously through UDP and requested items are transmitted through TCP. To Scouter Server (Collector).
The Server (Collector) stores the data in its own database and the stored data is automatically deleted by the settings (capacity, period).
The Client requests the collected data from Server (Collector) by TCP and displays it on the screen using Eclipse RCP.
In the above figure, the green circle part is the part modified by the Scouter to monitor the CUBRID.
-
Available Monitoring Items
The table below is the list of monitoring items that are currently available on Scouter. We plan to add items that can be monitored through CMS (CUBRID Manager Server), Scouter Server, Client, and Agent extensions later.

-
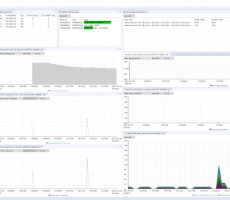
Client UI
The picture below is the initial screen in the Client. Installation and Client UI documentation can be found through the Readme document on Scouter Agent GitHub. (Reference URL 2&3).

3. Reference
- Scouter Agent GitHub - GitHub - scouter-contrib/scouter-agent-cubrid: scouter cubrid agent
- Quick Start Guide - https://github.com/scouter-contrib/scouter-agent-cubrid/blob/main/documents/quick_start_KR.md
- Client UI Guide - scouter-agent-cubrid/client_guide_KR.md at main · scouter-contrib/scouter-agent-cubrid · GitHub
- Scouter GitHub - GitHub - scouter-project/scouter: Scouter is an open source APM (Application Performance Management) tool.
 QUERY CACHE Hint
QUERY CACHE Hint
 CUBRID INTERNAL: CUBRID Double Write Buffer
CUBRID INTERNAL: CUBRID Double Write Buffer