Written by MinJong Kim on 12/09/2021
ABOUT QUERY CACHE
With the release of CUBRID 11.0, the CUBRID DBMS supports QUERY CACHE hint.
In this article, we will take some time to look at QUERY CACHE.
1. What is Query Cache?
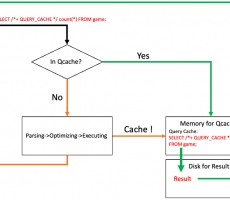
Query Cache is a DBMS feature that stores the statements together with the retrieved record set in memory using the SELECT query statement and returns the previously cached values when the identical query statement is requested.
The query cache can be useful in an environment where you have tables that do not change very often and for which the server receives many identical queries. Queries using the QUERY_CACHE hint are cached in a dedicated memory area, and the results are also cached in separate disk space.
- Query Cache Features
1. The QUERY_CACHE hint only applies to SELECT statements.
2. When a table change (INSERT, UPDATE, DELETE) occurs, the information in the Query Cache related to the table is initialized.
3. When the DB is unloaded, the Query Cache is initialized.
4. The cache size can be adjusted through the max_query_cache_entries and query_cache_size_in_pages setting (The default value is all 0).
max_query_cache_entries is the setting value for the maximum number of queries that can be cached. If it is set to 1 or more, as many queries as the set number are cached.
query_cache_size_in_pages is the setting value for the maximum cacheable result pages. If it is set to 1 or more, the results for the set page are cached.
-
Pros for Query Cache
When the hint is set and a new SELECT query is processed, the query cache is looked up if the query appears in the query cache. If the query is found from the cache, the data stored in the cache will be returned immediately without going through the previous 3 steps (Parsing->Optimizing->Executing). Therefore, the higher the cost of the query and the more repeatedly invoked, the greater the resource benefits.
2. How to use the Query Cache
-
How to use?
1. Set the values of max_query_cache_entries and query_cache_size_in_pages in the cubrid.conf file. (Example: if the number of sql statements to cache is 10, set the max_query_cache_entries value to 10, and set query_cache_size_in_pages to 640 when the result size is 10M.)
2. Add the /*+ QUERY_CACHE */ hint to the select statement.
-
Procedure
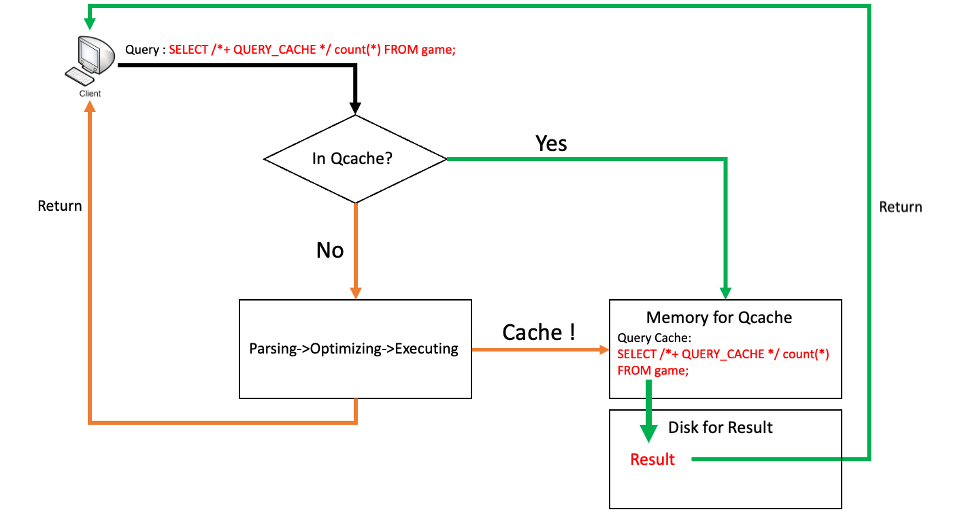
- When the hint is set and a new SELECT query is processed, the query cache is looked up if the query appears in the query cache.
- If the cached query is not found, the query will be processed and then cached newly with its result.
- Result Analysis
You can check whether a query is cached by entering the session command ;info qcache in CSQL.
example)
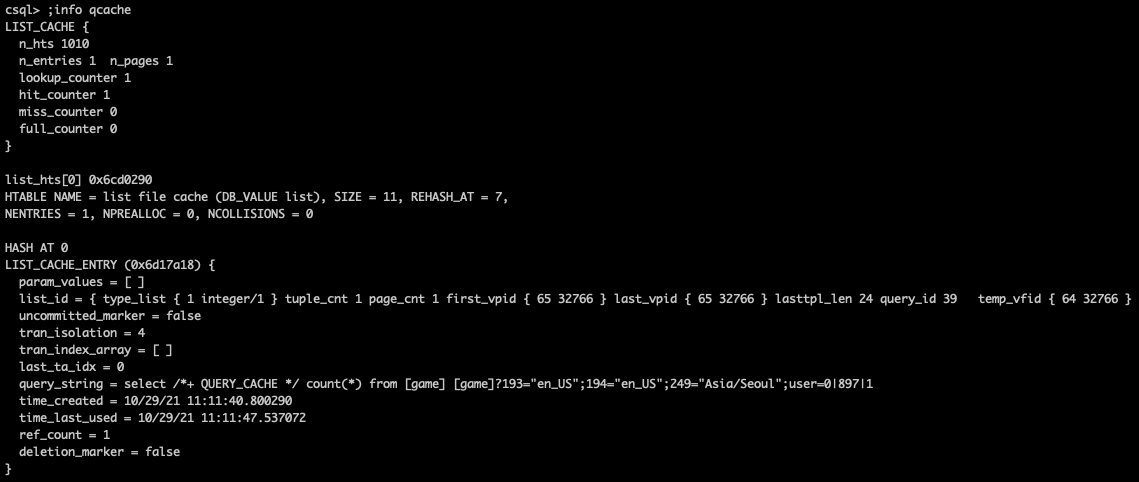
The cached query is shown as query_string in the middle of the result screen. Each of the n_entries and n_pages represents the number of cached queries and the number of pages in the cached results.
The n_entries is limited to the value of configuration parameter max_query_cache_entries and the n_pages is limited to the value of query_cache_size_in_pages.
If the n_entries is overflown or the n_pages is overflown, some of the cache entries are selected for deletion. The number of caches deleted is about 20% of max_query_cache_entries value and of the query_cache_size_in_pages value.
3. Cautions
The hint is applied to SELECT query only; However, for the following cases, the hint does not apply to the query and the hint is meaningless:
- a system time or date related attribute in the query as below
example) SELECT SYSDATE, ADDDATE (SYSDATE, INTERVAL -24 HOUR), ADDDATE (SYSDATE, -1); - a SERIAL related attribute is in the query
- a column-path related attribute is in the query
- a method is in the query
- a stored procedure or a stored function is in the query
- a system table like dual, _db_attribute, and so on, is in the query
- a system function like sys_guid() is in the query
-
Lock waiting situation may occur due to the table change
If there is any change (ex. INSERT, UPDATE, DELETE) to the target table, the existing cache is always removed. At this time, other transactions will now lock the data to prevent it from grabbing any more invalid data. Until this lock is released, transactions accessing the Query Cache wait in the lock state. Therefore, the more frequently the table is changed, the more SELECT queries that use the Query Cache, the more time is spent waiting for this lock.
4. Conclusion
Query Cache is useful for data that does not change frequently but needs to be accessed frequently, such as street name, address, organization information, department information, etc. In this case, Query Cache can help reduce system resource usage and improve performance.
 Monitoring CUBRID through Scouter
Monitoring CUBRID through Scouter