
Written by SeHun Park on 08/07/2021
What is Subquery
A subquery is a query that appears inside another query statement. Subquery enables us to extract the desired data with a single query. For example, if you need to extract information about employees who have salary that is higher than last year’s average salary, you can use the following subquery:

It is possible to write a single query as above without writing another query statement to find out the average salary. Subquery like this has various special properties, and their properties vary depending on where they are written.

- scalar subquery: A subquery in a SELECT clause. Only one piece of data can be viewed.
- inline view: A subquery in the FROM clause. Multiple data inquiry is possible.
- subquery: A subquery in the WHERE clause. It depends on the operator and the properties of the scalar subquery or inline view.
The use of subqueries makes queries more versatile but it can adversely affect query performance.
The Sequence of Subquery Execution and Causes of Performance Degradation
A subquery is always executed before the main query to store temporary results. And as the main query is executed, the temporarily stored data of the subquery is retrieved to obtain the desired result.
For example, the subquery is executed first, the result is stored in the temporary storage, and the final result is extracted by checking the condition 'a.pk = 3'.
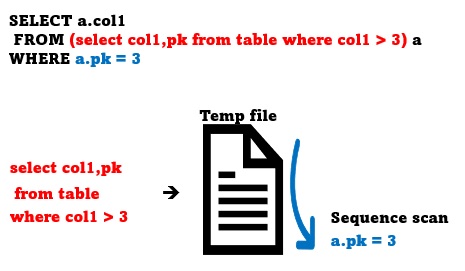
As the number of subquery results increases, useless data will be stored during the process. And also, the index cannot be used because it is searched from the temporary data stored in the middle.
This kind of query process is very inefficient. Does DBMS execute the above query as we describe? No.
View Merging
Removing the in-line view and merging it into the main query is called view merging.
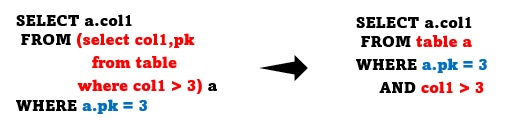
With view merging, there is no need to store temporary data, and index scans for pk are now possible. No matter how the user writes the subquery, if it is possible to merge with the main query, the DBMS proceeds with the merger. The merging of these views serves to remove the constraint of the execution order before going to the OPTIMIZER phase; which is, putting all the tables on the same level and finding the most optimal execution plan.
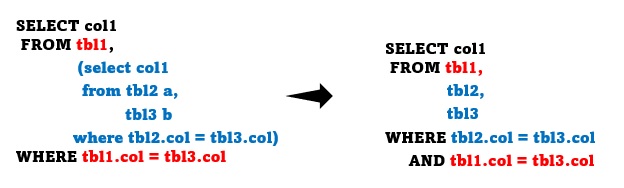
In the case of the above query, the join of tbl2 and tbl3 in the subquery always proceeds together before the view is merged. For example, a join order such as tbl3->tbl1->tbl2 is not possible. The merging of views is ultimately aimed at removing the constraint of the execution order and allowing OPTIMIZER to find the optimal execution plan.
CUBRID supports view merging including in-line views from CUBRID 11.2. In the previous version, view merging was performed only for view objects, but this function has been expanded from CUBRID 11.2.
Subquery UNNSET
This is a rewriting technique applied to the subquery of the WHERE clause. Typically, it targets IN and EXISTS operators.

How is the above query executed?
In CUBRID, the IN operator extracts the data of the main query as the result of the subquery. If you think of it as table join order, tbl2 ==> tbl1 order.
Then what about other operators?

The case for EXISTS operator is the opposite. If we express it in join order, the order will be tbl1 ==> tbl2. Depending on how the query is written, there are restrictions on the order of performance. Depending on the amount of data in the subquery and main query, IN operator may be advantageous or vice versa.
Overcoming this situation is the SUBQUERY UNNEST technique.

If it is converted to a join as above, OPTIMIZER can choose which table to look up first. Rewriting the subquery of the WHERE clause as a join is called SUBQUERY UNNEST.
One peculiarity is that the IN and EXISTS operators must not affect the result of the main query even if there is duplicate data in the result of the subquery.
For that reason, a Semi Join is performed instead of a normal join. A Semi Join stops the search when the first data is found and proceeds to the next search. Semi Join is a join method used to achieve the same result as an operator such as IN.
(However, CUBRID has not supported SUBQUERY UNNEST yet. It is recommended to use IN and EXISTS operators according to the situation.)
By rewriting the query, the DBMS removes the constraint on the execution order implied in the query. Converting an OUTER JOIN to an INNER JOIN, or deleting an unnecessary table or query entry, serves the same purpose.
OPTIMIZER will be able to create an optimal execution plan in a situation where there is no restriction on the execution order as much as possible. And it will eventually increase query performance and allow DBMS users to get the data they want quickly.
Sometimes, when users check the execution plan of a query, it appears completely different from the query and users are confused. Understanding the query rewrite technique will be a great help. Currently, the CUBRID development team is working on rewriting these queries and improving OPTIMIZER. In the next blog, we will talk about what does OPTIMIZER do to find the optimal execution plan.