Written by SeHun Park on 11/09/2021
- HASH SCAN
Hash Scan is a scan method for hash join. Hash Scan is applied in view or hierarchical query. When a subquery such as view is joined as inner, index scan cannot be used. In this case, performance degradation occurs due to repeated inquiry of a lot of data. In this situation, Hash Scan is used.
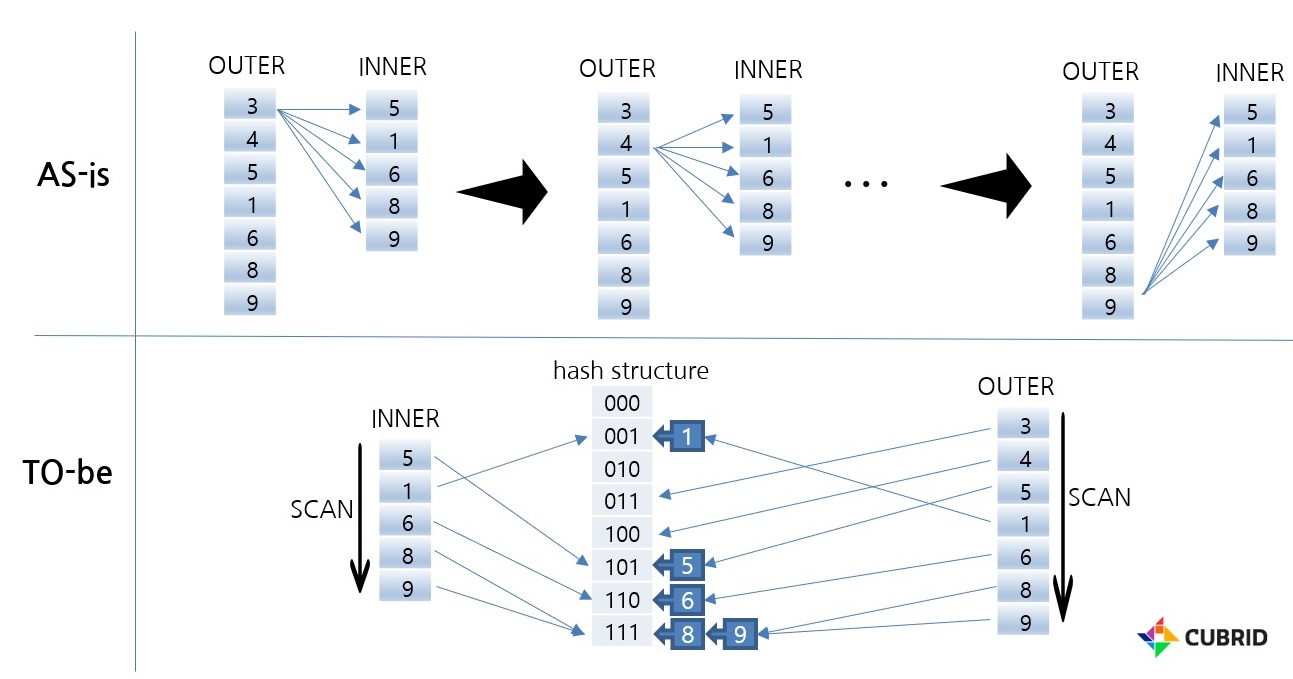
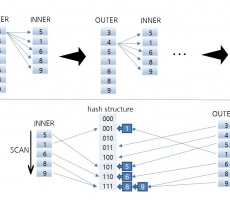
The picture above shows the difference between Nested Loop join and Hash Scan in the absence of an index. In the case of NL join, the entire data of INNER is scanned as many as the number of rows of OUTER. In contrast, Hash Scan scans INNER data once when building a hash data structure and scans OUTER once when searching. Therefore, you can search for the desired data relatively very quickly.
Here, the internal structure of Hash Scan is written as the flow of the program development process.
- IN-MEMORY HASH SCAN
CUBRID's Hash Scan uses in-memory, hybrid, and file hash data structures depending on the amount of data. First, let's look at the in-memory structure.
The advantage of the in-memory hash scan structure is there is no performance degradation during random access. However, the disadvantage of this structure is that the memory size is limited. It cannot be used in all cases due to its disadvantages, but it is the fastest method due to its advantages. Because of its advantage, it is suitable for chaining hash structures.
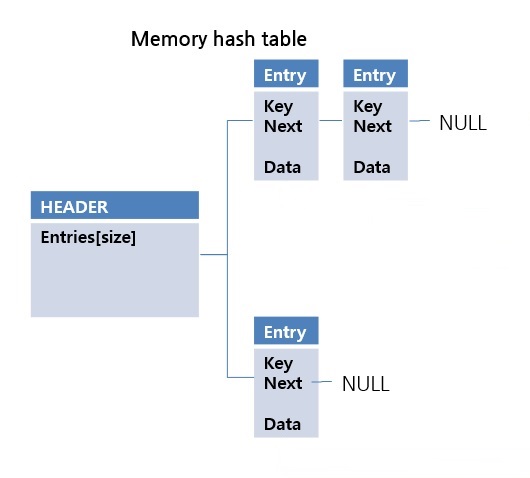
If there is a collision of hash key values, a new entry is put into the next pointer. It is a simple and fast structure. However, when implemented in file format, problems with random access or space utilization may occur. More details about this will be discussed in the following File Hash Structure section. CUBRID performs in-memory hash scan only within a limited size. You can change the limit size using the max_hash_list_scan_size system parameter.
At this stage, rather than implementing an in-memory hash data structure, it was necessary to analyze OPTIMIZER and EXECUTOR and think more about which part should be modified. You can refer to the following link for details about it. Moreover, you can check the design-related contents in JIRA and the results of code review in GIT.
JIRA: http://jira.cubrid.org/browse/CBRD-23665
GIT: https://github.com/CUBRID/cubrid/pull/2389
- HYBRID HASH SCAN
This is a method of storing the OID (Object Identifier) of the temp file, not DATA, in the value of the in-memory hash data structure.
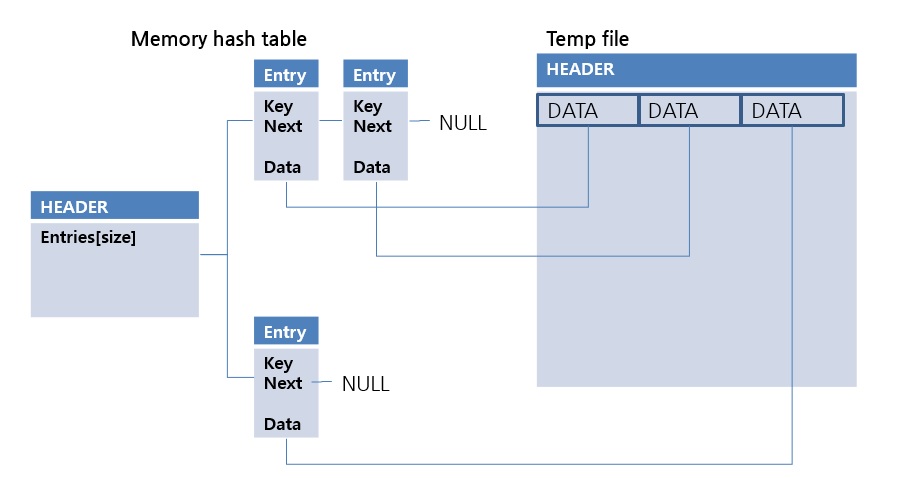
Because OIDs are smaller than DATA, in-memory hash data structures can be used in larger data sets. This method is relatively slower than the in-memory hash method because data from the temp file must be read at the time of lookup. This is the second scan method considered in the hash scan. Check out the link below for more details.
JIRA: http://jira.cubrid.org/browse/CBRD-23828
GIT: https://github.com/CUBRID/cubrid/pull/2537
- FILE HASH SCAN
A scan method that uses the file hash data structure. The extendible hash data structure is applied.
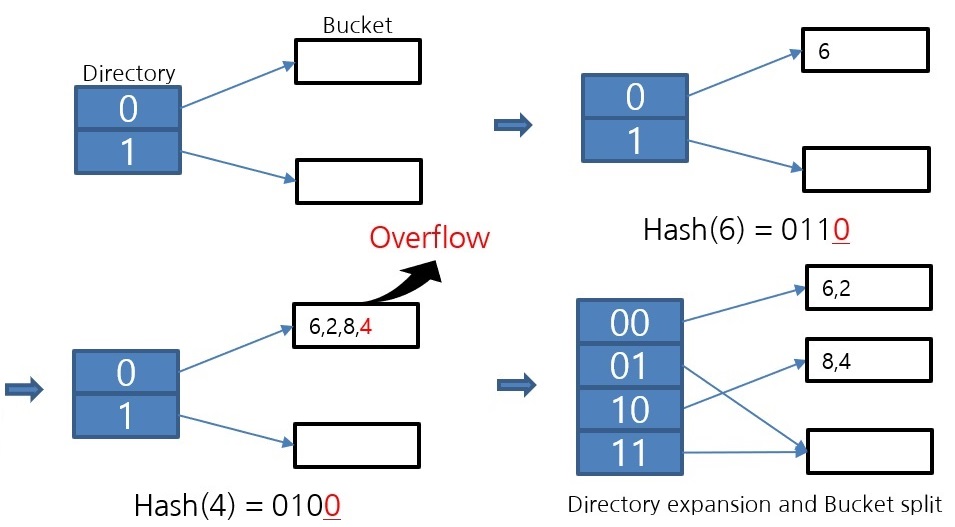
The diagram above shows the operation of the extendible hash algorithm. When overflow occurs, the bucket is divided. Because it operates in this way of partitioning, it is an algorithm that can maintain the bucket space utilization rate above 50%. Since one bucket is implemented as a page, which is the smallest unit of disk I/O, the higher the bucket space utilization, the lower the disk I/O. For this reason, file hash scans use an extendible hash algorithm.
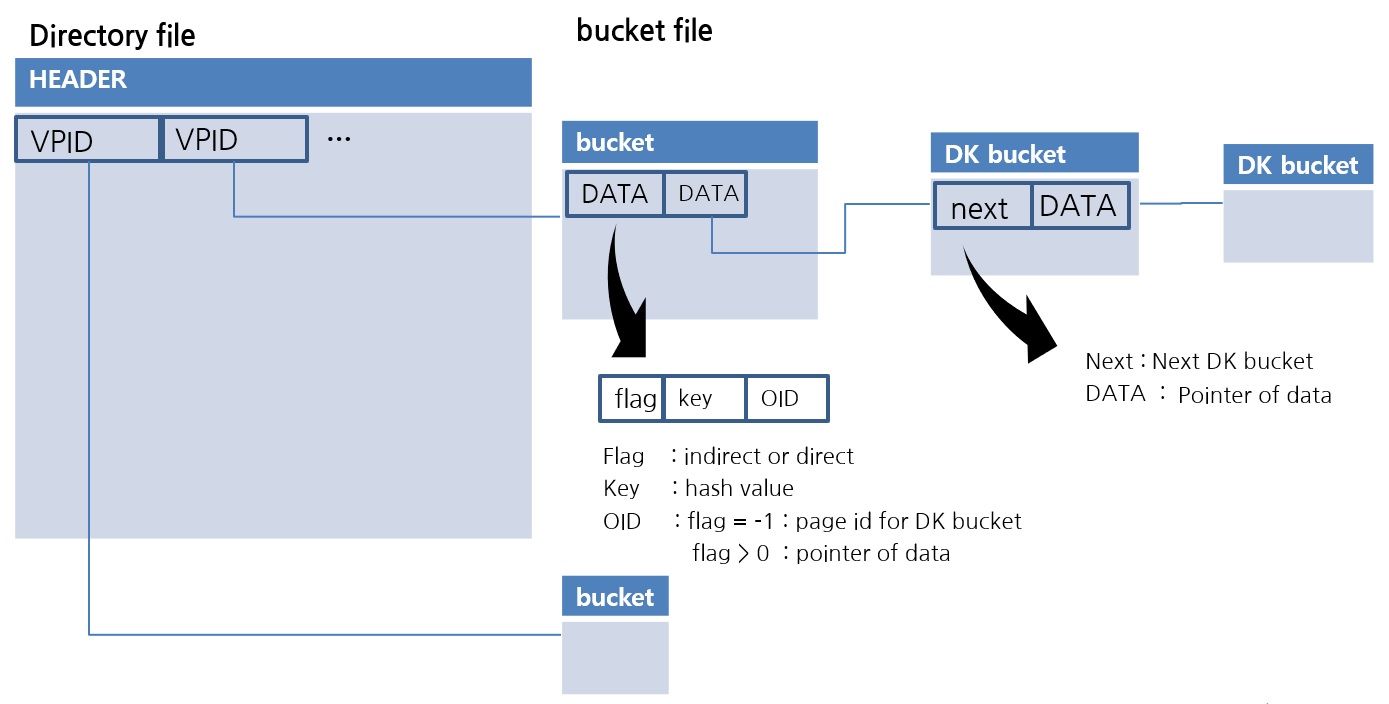
This is the implementation of the extendible hash data structure in CUBRID. The Directory file stores the VPID, which is the Page Identifier. One Bucket is implemented as one page. The data in the Bucket is sorted, so the lookup uses a binary search.
One drawback of extendible hash data structures is that there are no exceptions for duplicate data values. For example, if overflow occurs because the same value is all stored in one bucket, it is an algorithm that can no longer be stored. For this, a new Duplicate Key Bucket is created and added in the form of chaining. If more than a certain amount of data is duplicated, the data is moved to the DK bucket. Through this, a file hash scan with excellent space utilization while being able to flexibly store duplicate values is completed. Visit the following links for a detailed explanation.
JIRA: http://jira.cubrid.org/browse/CBRD-23816
GIT: https://github.com/CUBRID/cubrid/pull/2781
- HASH SCAN for Hierarchical Queries
A hierarchical query has a special limitation in that it is necessary to perform a lookup between the hierarchies after the join. Because of this, index scans cannot be used for hierarchical queries with joins. What you need in this situation is a hash scan, right? It has been modified so that hash scan can be used for hierarchical queries as well. Check the link below for more details.
JIRA: http://jira.cubrid.org/browse/CBRD-23749
GIT: https://github.com/CUBRID/cubrid/pull/2520
- HASH JOIN
The in-memory hash scan is applied in the CUBRID11 version, and the file hash scan is applied in the CUBRID11.2 version which will be released soon. The hash join function is currently under development. The development of the hash join function is to add a new join method to OPTIMIZER. Currently, there are Nested Loop join and Sort Merge Join in CUBRID. The CUBRID development team is planning to improve the overall OPTIMIZER. OPTIMIZER will be able to generate a more optimal execution plan. And with that work, a hash join method will be added. Before the hash join is added, the execution plan cannot check whether a hash scan is used. Instead, you can check whether Hash Scan is used in the trace information.

- HASH SCAN Performance
In situations where a hash scan is required, the query performance has become incomparably faster than before.
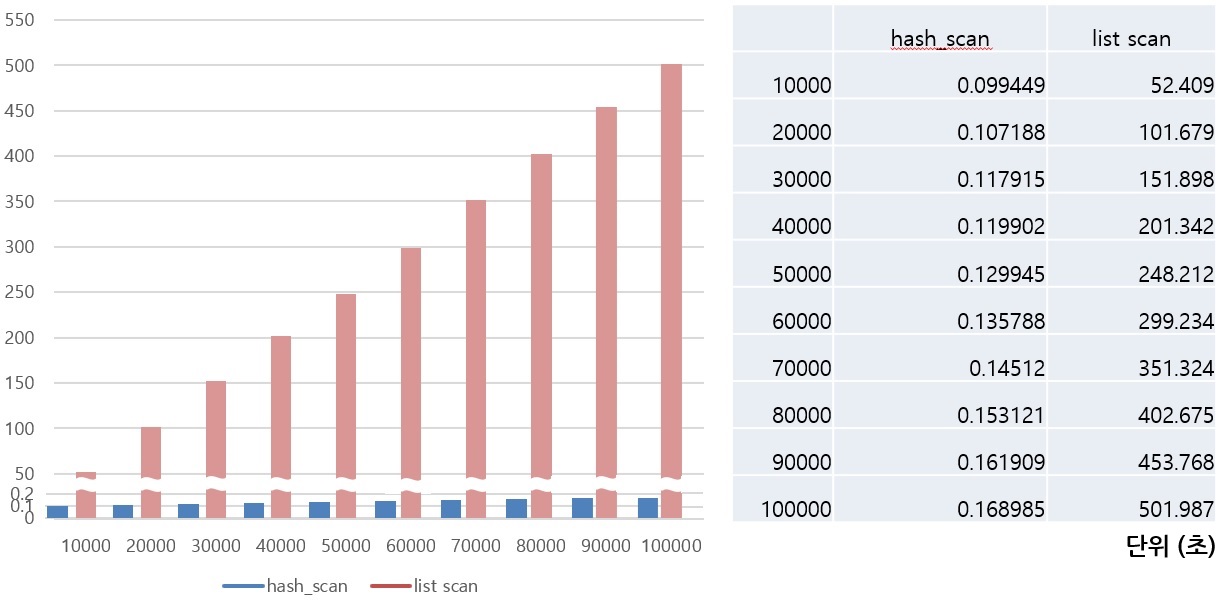
The performance is greatly improved compared to the previous case in cases where subqueries are joined as inner or hierarchical queries with joins. CUBRID analyzes the causes of several other cases and reflects improvements to improve query performance. Among these improvements, there are REWRITER improvements such as View Merging and Subquery unnest, and improvements related to View Merging are currently in progress. Next, we will learn how to transform a query in DBMS and why rewrite techniques such as View Merging and Subquery unnest are necessary.
 CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Sub...
CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Sub...