
Written by Hyung-Gyu, Ryoo on 07/16/2021
Foreword
Hello, I am Hyung-Gyu Ryoo, I am working in CUBRID as a research engineer in the R&D department. In this post, I would like to introduce the development process of the open source project CUBRID and the efforts we have made to improve the process.
It has been almost two and a half years since I joined CUBRID. During this period, as many great fellow developers have joined the CUBRID community, the R&D department of CUBRID has grown from one small team to three developments teams along with a QA team.
After I participated in the first major version release (CUBRID 11), I was able to look back to the release process and improve the development process with my fellow developers.
The Development Process of the Open Source Database Project, CUBRID
CUBRID foundation pursues the values of participation, openness, and sharing. In order to realize the core value of the CUBRID foundation, information sharing and process transparency are embedded in CUBRID’s development process and culture.
All developers contributing to CUBRID follow the open source project development process. This means that both internal developers of CUBRID and external contributors proceed in the same way. In addition, information created during the development process (function definition, design, source implementation) is naturally shared during the development process.
All CUBRID projects, feature additions, and bug fixes are completed through the following general open source project development process:

- Communication: Suggestions and discussions about projects, feature additions, and bug fixes.
- Triage: Just as it is impossible to solve all the problems in the world, it is impossible to develop all the functions required for CUBRID at once, or to find and solve all the bugs perfectly. The project maintainer (development leader) decides which tasks need to be addressed and which tasks to start first.
- Dev (Development): Design, code implementation, and code review are performed by a designated developer.
- QA: Functional and performance tests are conducted on the implementation results in the CUBRID QA system.
The CUBRID development process is based on JIRA and GitHub collaboration tools. JIRA is a collaboration tool that helps you manage software processes. Each task can be managed as a unit called a JIRA issue. GitHub is a service that provides a remote repository for open source projects, and developer can perform code reviews through a function called Pull Request on the web.
JIRA

Example: http://jira.cubrid.org/browse/CBRD-23629
All CUBRID projects, feature additions, and bug fixes start with the JIRA issue creation. In the development process, the issue will naturally record what kind of work to be done (function definition), how to do it (design), and how the work was completed (detail design/implementation) as shown in the figure above.
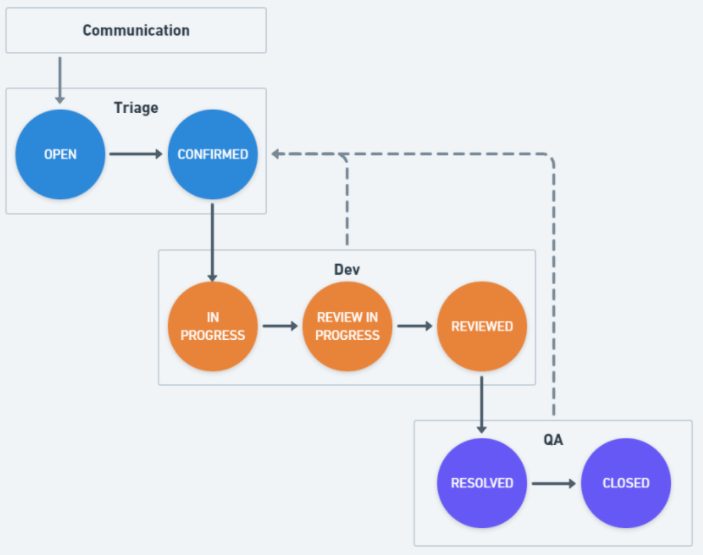
CUBRID Development Process and Jira Issue Status
The [Feature Suggestion/Discussion → Selection → Development → Test] process described above for each JIRA issue has the status of the issue as shown in the figure above: OPEN, CONFIRMED, IN PROGRESS, REVIEW IN PROGRESS, REVIEWED, RESOLVED, CLOSED. By looking at the state name, developers can easily understand which stage they are working on.
Github Code Review
Code review is a process in which other developers review and give feedback on the code written by the developer in charge of the issue before it is merged in CUBRID. On Github, code reviews are performed using the Pull Request function for the results developed in each issue. By referring to the shared content (feature specification, design) in JIRA, the developers of CUBRID discuss the implementation logic to find a safer and faster way.
Development Process Improvement
Why do we improve the development process?
One day at work, instead of taking a short nap after lunch, I had coffee time with my colleagues; and I realize that this short coffee break chat is the most creative time for our fellow developer. For example, while preparing the latest release of the CUBRID 11 version, we talked about the process and the difficulties we met.
However, during our conversation, I realize that even though all developers worked according to the development process described earlier, the details of each of them were slightly different. Now we have successfully released the stable version of CUBRID 11, however, I feel that something is missing.
Therefore, I started digging into the developing process of CUBRID with my fellow colleagues. We started to think about the reason behind each step and ask each other ‘why’: ‘Why do you have to do this? What does this information you put in each time mean? Is this procedure efficient?’. For these million questions, the answers are mostly ‘there is a lot of ambiguity, and it definitely needs improvement.’
The development process of CUBRID that I described earlier is a process created by someone in the past (many thanks!). However, I thought that if we do not fully understand why and the purpose of operating the development process, this will not be established as a development culture. Moreover, as time goes by, vague rules were quickly forgotten or were not clearly agreed upon, it seems like only a few members knew about it.
If each element of the development process was not established with a sufficient understanding from all members, it is natural that the details were understood slightly differently by each member. As time pass, this insufficient understanding might drive the valuable development culture apart from the members and become forgetful.
So, I thought about what values CUBRID should keep as a development culture. And the answer is the three values introduced in the first paragraph of this post: participation, openness, and sharing. When we interpreted from the perspective of CUBRID’s development culture, it can be interpreted as: ‘if we want everyone can easily and safely participate in the CUBRID project, the process must be transparently viewed by anyone, and information must be shared well enough’. I realized that keeping these values well associates with a higher level of development output.
These contents were shared within the company, and a consensus was formed that a well-established development process would maximize work efficiency beyond simply expressing the convenience of management and mature development culture, and of course, the development process was further improved. In the next chapter, we will look at some of the improvements we have done and how it relates to the value of ‘participation, openness, and sharing.
Reorganize the JIRA process
As explained earlier in the introduction of the CUBRID development process, all CUBRID projects, feature additions, and bug fixes start with the creation of JIRA issues. When creating and managing issues, it is necessary to fill in the items and contents that must be written at each stage of the development process, but users might feel that some of the parts are difficult to understand.
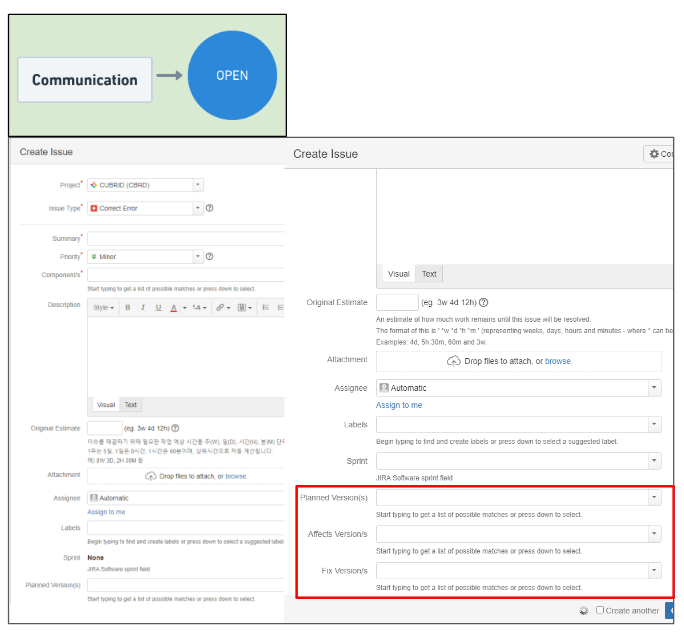
The above figure is the issue creation window before improving the JIRA process. When contributors create a JIRA project, the default screen is applied and had the following problem:
- When creating an issue, there are too many items to enter, so contributors don't know which one to fill out (☹)
- Contributors just simply don't know what to write (☹)
Due to these problems, the necessary content for each issue task was not consistently written, or as a contributor pondered whether or not to include the content whenever he or she started work, productivity was falling.
Problem 1: When creating an issue, there are too many items to enter, so contributors don't know which one to fill out
The most frequently asked question by fellow developers who are new to CUBRID when they create an issue for the first time is ‘Huh... Do I have to enter everything here??’ When creating an issue, the project maintainer only needed a few things to sort out the issue; however, all fields were displayed using the default setting of JIRA.
This situation also raises the threshold for external contributors to participate in CUBRID. If too many fields are displayed at once when an external contributor clicks the ‘Create Issue’ button, he/she might give up contributing after looking around because of the fear of making a mistake.
Therefore, we have organized the necessary contents in each issue’s state and set it to input only the contents that are required when changing to that status.
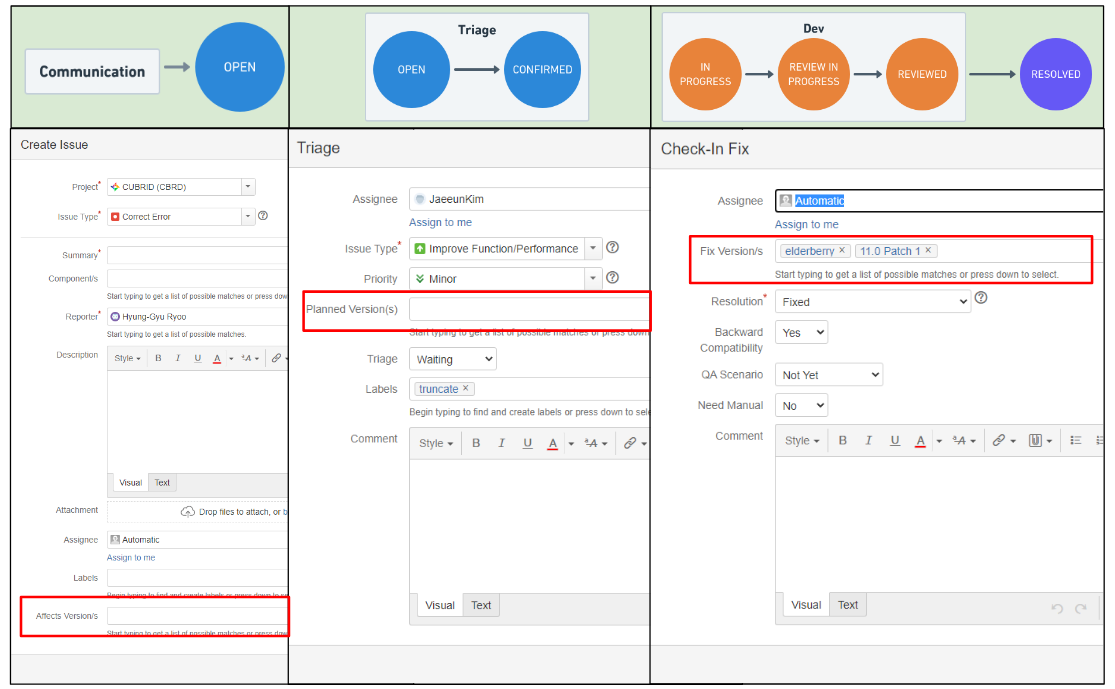
It is difficult to explain all the improvements, however, here is an example. the field related to version was one of the parts that members were most confused about when creating and managing issues. As shown in red in the figure above, the following three version fields are displayed together during the creation of an issue, so there are cases where a value is entered in only one of them or simply contributors just omit one of the fields because it is not clear where to enter it.
- Affected Version: Version in which the issue creator found a bug or problem during analysis (bug fix type only).
- Planned Version: Version in which the issue is planned to proceed.
- Fixed Version: Version with issue results merged.
For each version field, we give a clear meaning and define the different issue status where this value should be entered:
- Affected Version must be entered when creating an issue (OPEN status),
- Planned Version when the project maintainer selects an issue (CONFIRMED),
- Fixed Version when resolving an issue (RESOLVED)
So, as shown in the following figure, whenever the status of an issue changes, only the necessary items and the version that must be entered are shown at each stage, so contributors can naturally follow the development process without omitting content.
Problem 2: Contributors just simply don't know what to write
When creating an issue in CUBRID, issue types are assigned according to the task to be performed.
- Correct Error: Issue that fixes bugs or errors.
- Improve Function/Performance: Issue that improves existing features or performance.
- Development Subject: Issue that adds new features.
- Refactoring: Issue that changes unnecessary code clean-up, code structure, and repository separation.
- Internal Management: Issue for internal management.
- Task: The issue type is applied if there is no category corresponding to the above issue type but is not recommended. (Example of use: release)
Depending on the type of issue, the content to be written will vary. For example, in the case of bug fixes, you should write down what kind of bug occurred, how to reproduce the bug, and how it should behave once the bug is fixed. In addition, in case of functional improvement or new function, a detailed description of which function will be added and how to add it (functional specification and design) is required. If you write and share this content well enough, it will be easier for people involved in the project to understand what is merged in the project. And this well-organized and shared functional specification or design also has the advantage of improving the quality of development work results.
we have organized a content template to write down the must-have content for each issue type:
| Correct Error |
Improve Function/Performance Development Subject Refactoring |
Internal Management Task |
|---|---|---|
Example) CBRD-23903 |
Example) CBRD-23894 |
Description: The purpose and description of the work. |
These contents will greatly help to improve the code review process, which will be discussed in the next chapter. This is because it is difficult to grasp all the contexts with only code changes as CUBRID is a system in which several functions and modules are intricately intertwined.
Improve Github code review/ code merge
One of the most important goals in the development process is how to conduct good code reviews. Here are some of the benefits of code review: [3]
- Better code quality: improve internal code quality and maintainability (readability, uniformity, understandability, etc.)
- Finding defects: improve quality regarding external aspects, especially correctness, but also find performance problems, security vulnerabilities, injected malware, ...
- Learning/Knowledge transfer: help in transferring knowledge about the codebase, solution approaches, expectations regarding quality, etc.; both to the reviewers as well as to the author
- Increase sense of mutual responsibility: increase a sense of collective code ownership and solidarity
- Finding better solutions: generate ideas for new and better solutions and ideas that transcend the specific code at hand.
All the members know these advantages, but to what extent should the reviewer review the code? Also, does the author really need this level of review? It can become a bit of an obligatory review while thinking about it.
So, in order to induce a more effective/efficient code review, it was necessary to think about how to do a good code review and improve it. Reading code is a task that requires a high level of concentration. Therefore, reviewers should be able to give high-level thought and feedback in a short period of time.
Now let’s take a look at the content that has been introduced for better code review in CUBRID.
Automation Tool (CI)
Automation tools are introduced to avoid wasting reviewers' mental efforts in areas that are boring, and where computers can do better. For example, a code style, license fixes, or a frequent mistake (such as not initializing a variable, or leaving unnecessary code, etc.).
In order to speed up the efficiency of code review, CUBRID introduces the following automation tools:
- Build: build each environment (CentOS, Ubuntu, Windows) for the code you want to merge and show the result (success or failure).
- SQL test automation: Build the source and actually run several SQL syntaxes to ensure that the functionality of the database works correctly.
Reference: https://app.circleci.com/pipelines/github/CUBRID
These automation tools helped make the code more stable. However, it is not enough to help reviewers focus on the logic of the code to merge or how well the code meets the design. This is because reviewers are likely to be buried during review time due to easy and visible problems such as simple mistakes and code formatting.

Therefore, in Pull Request, these low-level reviews were improved using automated tools so that reviewers can focus on high-level reviews only.
- - license: Make sure you have the correct form of the license header comments.
- - Pull Request Style: There is a rule that all PRs must be associated with each JIRA issue, and this issue number must be specified at the beginning of the PR title. pr-style will check this and fail if the rule is not followed.
- - code-style: Make sure you follow the defined code style to keep your code consistent. Code style is defined using code formatting tools, and code-style uses these tools to check and correct whether the rules are properly followed. If it is different from the rule, it will fail and report it through PR suggestion.
- - cppcheck: cppcheck is a static analysis tool for the C++ language. Static analysis can reveal many problems that developers can cause, such as unused variables and NULL references. These errors are easy to make, but they are obvious, so you can only find them by looking at the code without context. Therefore, it is inefficient for reviewers to find and comment on each one. cppcheck catches these problems. If there is an error, it will fail and report using a comment to the PR.
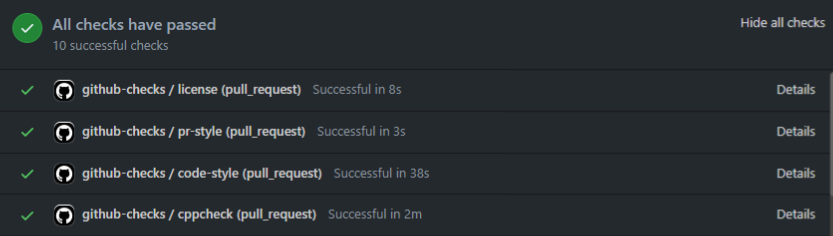
The newly introduced automation tool used GitHub Actions (https://docs.github.com/en/actions), a CI tool directly provided by GitHub. The introduction of this tool makes it easier for contributors to CUBRID to understand and engage with CUBRID's code conventions and the quality of the code they are trying to reach. If the code doesn't pass the automation tool, the code won’t be merged; therefore, you don't have to worry about making a mistake.
Divining a large amount of code review
Because CUBRID is a database system with a complexity of features and modules, the amount of code requested for review is often huge. One Pull Request with too many code changes makes it impossible for reviewers to review effectively.
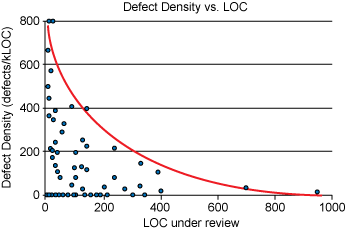
As the number of lines of code (LOC) exceeds 400 lines, the code defect detection density decreases. [4]
In CUBRID, we try to conduct code reviews in small, meaningful units of features by creating feature branches to avoid Pull Requests with too many changes. For a detailed description of feature branches, refer to [5].
The Development Process Document: CUBRID Contribution Guide
To make it a little easier to participate in the development of CUBRID, we needed a way to explain how the development process goes as a whole and share the essentials at each stage. So, we wrote an explanatory guideline document that can be used as a reference for developers who are interested in and want to contribute, as well as the new developers who are joining CUBRID.
https://dev.cubrid.org/dev-guide/v/en/

Some of the things we considered while writing this guideline document are:
- Do not write something that is difficult to read! The development process is a step-by-step process, so let’s make it possible for readers to find the information for each step easily.
- Everyone can read the latest version.
- There is no perfectly thorough development process or guide documentation, the documentation should be easy and understandable.
I have thought about several tools and services, such as Word, Jira Wiki, Google Docs, creating a new webpage, Gitbook pages, etc. After several considerations, I decided to go with the Gitbook service (Thank you for Gitbook Team!)
- By displaying the document structure in tab format, readers can easily view each paragraph.
- It is distributed as a web page and if we modified and merged in real-time, readers can see the modifications in real-time.
- Of course, support Open Source Community Plan for open source projects!
If you want to write a contribution guide document for another open source project, you are always welcome to refer to it when you are thinking about how to distribute the document and tools!
Last but not least... the CUBRID development culture
Many developers, of course, want to work in a good development culture. However, I don't think there is any development organization in the world with a perfect development culture. The development process described above is a means to create a 'development culture', and the more verification processes are added to the development process, the lower the productivity of course. Also, as time passes and circumstances change, the improved process may not work properly.
CUBRID continues to search for a balance between better quality results and higher productivity. In CUBRID, Members gather to share and discuss the best way to conduct code reviews, such as the following, so that all members can become more natural in the development culture of CUBRID.

Based on CUBRID’s organizational culture that values horizontal and free communication and knowledge sharing, many people are able to actively join and help to improve the development process.
(Special Thanks to CTO, Jaeeun, Kim and Jooho,Kim the research engineers!!).
I hope that this article will be an opportunity to introduce the way CUBRID's development organization works and to understand the CUBRID development culture.
Thank you. :-)
Reference
[1] Open source Guide, https://opensource.guide/
[2] Software Policy & Research Institute, https://spri.kr/posts/view/19821?page=2&code=column
[3] Code Review, Wikipedia, https://en.wikipedia.org/wiki/Code_review
[4] Best Practices for Code Review, https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
[5] Feature branch workflow, https://www.atlassian.com/git/tutorials/comparing-workflows/feature-branch-workflow
 TDE (Transparent Data Encryption) in CUBRID 11
TDE (Transparent Data Encryption) in CUBRID 11
 CUBRID Internal: Storage Management (Disk Manager, File Manager)
CUBRID Internal: Storage Management (Disk Manager, File Manager)