Written by on 06/16/2017
Previous blog article covered Vert.x, a Java application framework which provides noticeable performance advantage over competing technologies and features multi programming language support. The previous article has explained us about the philosophy of Vert.x, performance comparison with Node.js, internal structure of Vert.x, and many more. Today, I would like to continue this conversation and talk more about Vert.x architecture.
Considerations Used to Develop Vert.x
Polyglot is the feature making Vert.x stand out from other server frameworks. In the past, server frameworks could not support multiple languages. Supporting several languages does more than expand the range of users. More important thing is that services using different languages in a distributed environment can intercommunicate with ease. Of course, supporting a variety of languages is not sufficient for supporting a distributed environment. Essential functions of greater priority for a distributed environment include address system or message bus. Vert.x framework provides these functions. As Vert.x provides these functions as well as Polyglot, the benefits of Vert.x should be considered for a distributed environment.
As Vert.x supports a universal server framework, a variety of workloads should be considered. We should consider unusal cases different from Nginx, which is typically used as a Web server, or Node.js. It is to build a universal server application that processes a variety of protocols except HTTP (i.e., not a Web server which executes simple operations, considering scalability in a 3-tier environment). In order to accomplish this, Vert.x provides an additional thread pool while using the Run Loop method.
We will discuss Vert.x architecture starting from the thread pool and consideration for a distributed environment.
Run Loop and Thread Pool
Vert.x and asynchronous server applications (or frameworks), include Ngin.x and Node.js, use the Run Loop method. Vert.x uses the term 'Event Loop' instead of 'Run Loop'. However, as Run Loop is the more popular term among some developers. I use this term, Run Loop, here. Run Loop, as you will guess from the name, is a method for checking whether there is a new event in the infinite loop, and calling an event handler when an event has been received. As such, the asynchronous server application and the event-based server application are different terms indicating an identical target, similar to ‘enharmonic' for music. To use the Run Loop method, all I/Os should be managed as events.
For example, imagine a general Web server application that creates a query for a database to respond to an HTTP request from a Web browser. The CPU of the Web server is used when one thread analyzes the HTTP request to execute proper business logic, and creates a query statement. However, the CPU is not used while the thread sends the query to the database and waits for a response. However, when the thread to be created equals the number of HTTP requests (Thread per Connection), another thread may be processing a task requiring the web server CPU, while one thread is waiting for response from the database. Finally, the web server CPU is used to process HTTP requests. As you know, the weakness of Thread per Connection is the cost for context switching at the kernel level since many threads must be created. This can be called waste.
The asynchronous event handling method can overcome this weakness (figuratively speaking, 'asynchronous event handling' is the 'purpose' and ‘Run Loop’ is the 'means'). If ‘HTTP request itself’ and ‘receiving a response from the database’ are created as an event, and the Run Loop calls the corresponding event handler whenever an event is received, the execution performance of the application can be enhanced by avoiding unnecessary context switching. In this fashion, to utilize a CPU efficiently, the number of Run Loops required equals the number of cores (i.e., thread should be created equaling the number of cores and each thread should run the Run Loop).
However, there is another problem creating threads equaling the number of cores, which is preventing as much context switching as possible. If a handler, using server resources, takes a long time to handle an event, other events received while the handler is being executed are not managed in a timely manner. A popular example is file searching on the server disk. In this case, it is better to create a separate thread for searching files.
Therefore, to build a universal server framework with asynchronous event handling, the framework should have a function for managing a thread pool. This is the aim of Vert.x. Thread pool management is the biggest difference between Vert.x and Node.js, except for polyglot. Vert.x creates Run Loops (Event Loops) equaling the number of cores and provides thread pool-related function to handle tasks using server resources requiring long periods for event handling.
Why is Hazelcast Used?
Vert.x uses Hazelcast, an In-Memory Data Grid (IMDG). Hazelcast API is not directly revealed to users but is used in Vert.x. When Vert.x is started, Hazelcast is started as an embedded element.
Hazelcast is a type of distributed storage. When storage is embedded and used in a server framework, we can obtain expected effects from a distributed environment.
The most popular case is session data processing. Vert.x calls it Shared Data. It allows multiple Vert.x instances to share the same data. Of course, additional RDBMS, instead of Hazelcast, will bring the same effect from the functional side. It is natural that embedded memory storage can consistently provide results faster than remote RDBMS. Therefore, users who need sessions for e-commerce or chatting servers can build a system with a simple configuration by using only Vert.x.
Hazelcast allows a message queue use without additional costs or investments (without server costs or monitoring of message queue instances). As mentioned before, Hazelcast is a distributed storage. It can duplicate a storage for reliability. By using this distributed storage as a queue, the server application implemented by using Vert.x becomes a message processing server application and a distributed queue.
These benefits make Vert.x a strong framework in a distributed environment.
Understanding Vert.x Components

Figure 1: Vert.x Architecture (Component) Diagram.
Figure 1 above shows a diagram of Vert.x components. As shown in the figure, in all Vert.x instances (these can be understood as a JVM), a Hazelcast is embedded and runs. The embedded Hazelcast is connected to Hazelcast in other Vert.x instances. Event Bus uses functions of Hazelcast. Hazelcast itself provides a certain level of reliability (because of WAL records and data duplication). So, events can be forwarded with a certain level of reliability.
HTTP Server and Net Server
HTTP Server and Net Server control network events and event handlers. A Net Server is for events and handlers private protocol, and an HTTP Server allows registering a handler to an HTTP event such as GET or POST. The reason for preparing an HTTP Server is eliminating the need to add event types, as well as the universality of HTTP itself. HTTP Server supports WebSocket as well as HTTP.
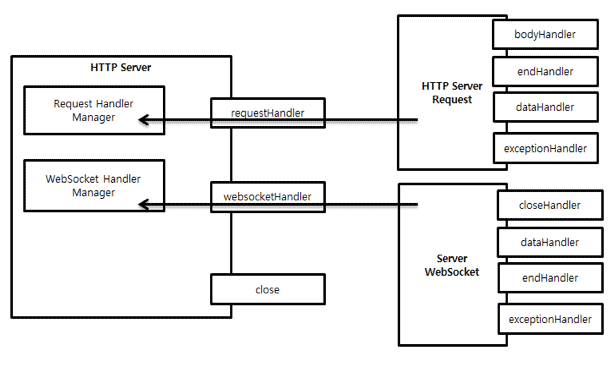
Figure 2: Event and Handler of HTTP Server.
Vert.x Thread Pool
Vert.x has three types of thread pools:
- Acceptor: A thread to accept a socket. One thread is created for one port.
- Event Loops: (same with Run Loop) equals the number of cores. When an event occurs, it executes a corresponding handler. When execution is performed, it repeats reading another event.
- Background: Used when Event Loop executes a handler and an additional thread is required. Users can specify the number of threads in vertx.backgroundPoolSize, an environmental variable. The default is 20. Using too many threads causes an increase in context switching costs, so be cautious.
Event Loops can be described as follows in a detailed way. Event Loops use Netty NioWorkder as it is. All handlers specified by verticles run on Event Loops. Each verticle instance has its specified NioWorker. As such, it is guaranteed that a verticle instance is always executed on an identical thread. Therefore, verticles can be written in a thread-safe manner.
Conclusion
So far, I have briefly described Vert.x architecture. Since Vert.x framework is not widely used, I believe it would be better to detail the concept of designing Vert.x than detail each Vert.x component. Even if you have no interest in network server frameworks, it is helpful to review new products and determine differences between new and existing products. Doing so helps in understanding the evolution and direction of software products that are flooding today's market.