
Written by Youngjin Joo on 09/30/2021
CUBRID DBMS (hereinafter 'CUBRID') does not support PL/SQL.
If you want to continue your project by creating functions or subprograms with PL/SQL syntax in CUBRID, you need to convert them to Java Stored Function/Procedure (hereinafter 'Java SP').
Database developers, administrators, and engineers are often familiar with PL/SQL syntax but not with programming languages. In addition, application development depends very little on the DBMS used, but converting PL/SQL to Java SP seems difficult because it feels like you're developing a new system.
Therefore, while I am looking for an easy way to convert PL/SQL to Java SP, I found out about ANTLR.
ANTLR is a tool for generating parsers.
With the help of contributors around the world, ANTLR supports grammar files for parsing various programming languages.
The official website introduces ANTLR as follows.
"ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It's widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees. (https://www.antlr.org/ - What is ANTLR?)"
In this article, we will learn how to configure the ANTLR development environment and how to create parser classes from PL/SQL grammar files.
Now, let’s test the class that converts pre-developed PL/SQL to Java SP.
The ANTLR development environment can be configured using various IDE tools such as Intellij, NetBeans, Eclipse, Visual Studio Code, Visual Studio, and jEdit. In this article, we will use the Eclipse IDE tool.
1. Installing the 'ANTLR 4 IDE' in Eclipse
To use ANTLR in Eclipse, you need to install ANTLR 4 IDE from 'Help > Eclipse Marketplace...'.
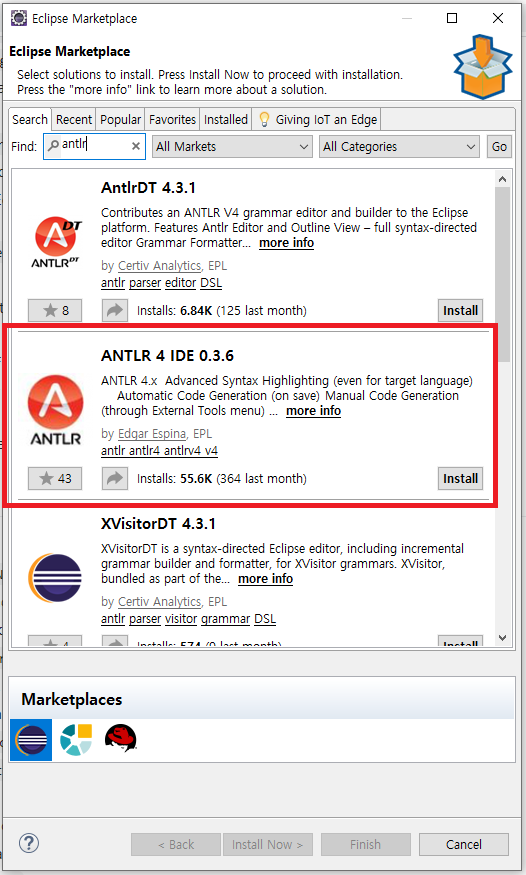
After installing the ANTLR 4 IDE, create a project with 'General > ANTLR 4 Project'
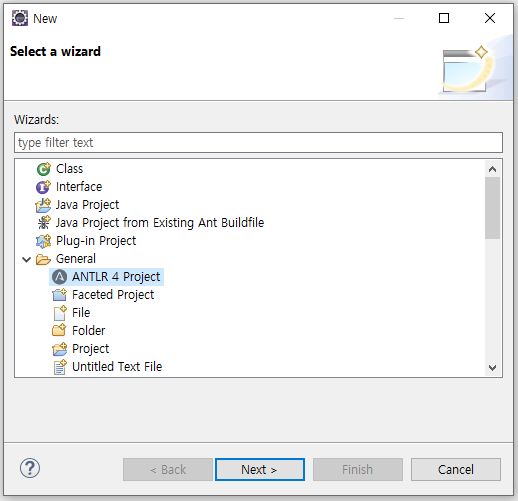
After creating the ANTLR project, select 'Project Facets > Java' in the project settings.
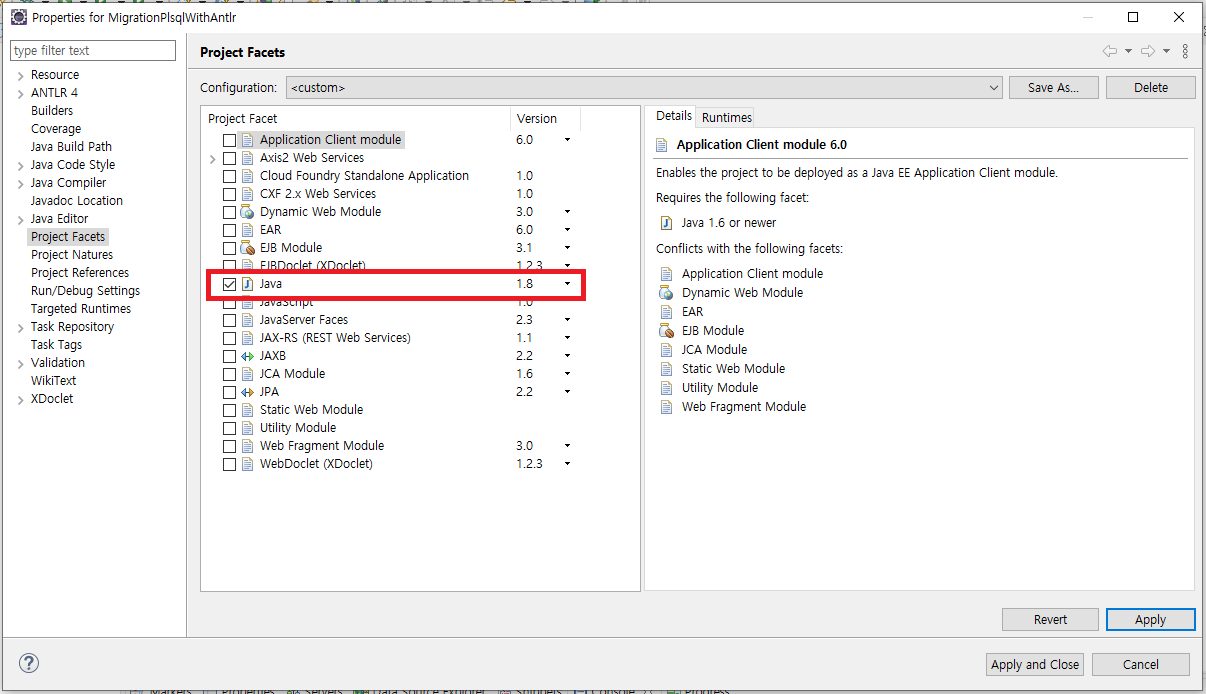
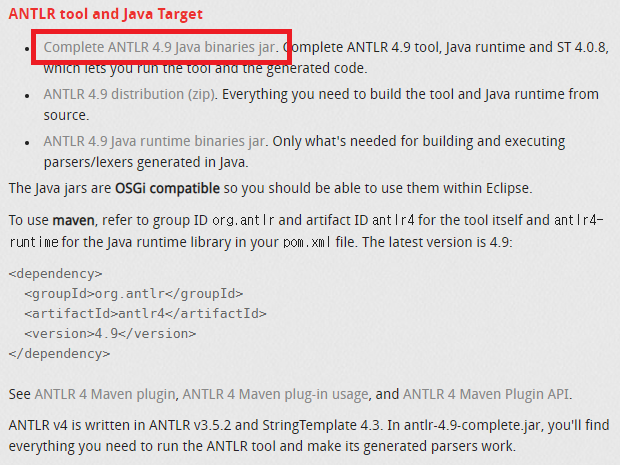
2. Adding antlr-4.9-complete.jar file to project 'Java Build Path > Libraries'
Even though the ANTLR 4 IDE is installed, we still need antlr-4.9-complete.jar file to use ANTLR.
This file can be download from ANTLR official website, and it must be added to 'Java Build Path > Libraries'.
- download : https://www.antlr.org/download.html

3. How to create parser classes from PL/SQL grammar files
Up to this point, the configuration of the ANTLR development environment has been completed.
To create PL/SQL parser classes with ANTLR, we need the PL/SQL grammar file.
The grammar file is supported by ANTLR and can be downloaded from GitHub (antlr/grammars-v4).
After creating the parser classes, we also need to download the necessary basic parser class files.
- download: https://github.com/antlr/grammars-v4/tree/master/sql/plsql
- download file:
* java/PlSqlLexerBase.java
* java/PlSqlParserBase.java
* PlSqlLexer.g4
* PlSqlParser.g4
When parsing a PL/SQL code, an error occurs if it is in lowercase letters. To resolve this issue, ANTLR asks you to capitalize the PL/SQL code before parsing.
You can bypass this problem by downloading the CaseChangingCharStream class and using it before parsing.
We are using the CaseChangingCharStream class before passing the PL/SQL code to the PlSqlLexerd class, which is shown in the main function.
- download: https://github.com/antlr/antlr4/tree/master/doc/resources
- download file:
* CaseChangingCharStream.java

4. How to create parser classes from PL/SQL grammar file
If you add the downloaded grammar files to the ANTLR project and run 'Run AS > Generate ANTLR Recognizer', parser classes for parsing PL/SQL are created.
If these class files are in the Default Package state, they cannot be used as an Import when developing separate parser classes.
When 'Run AS > Generate ANTLR Recognizer' is executed, if the package setting is added to the Generate ANTLR Recognizer option, *.java files are created.
Simply add '-package <package name>' to 'Run As > External Tools Configurations... > ANTLR > Arguments'.
The package setting must be done with both grammar files (PlSqlLexer.g4, PlSqlParser.g4).
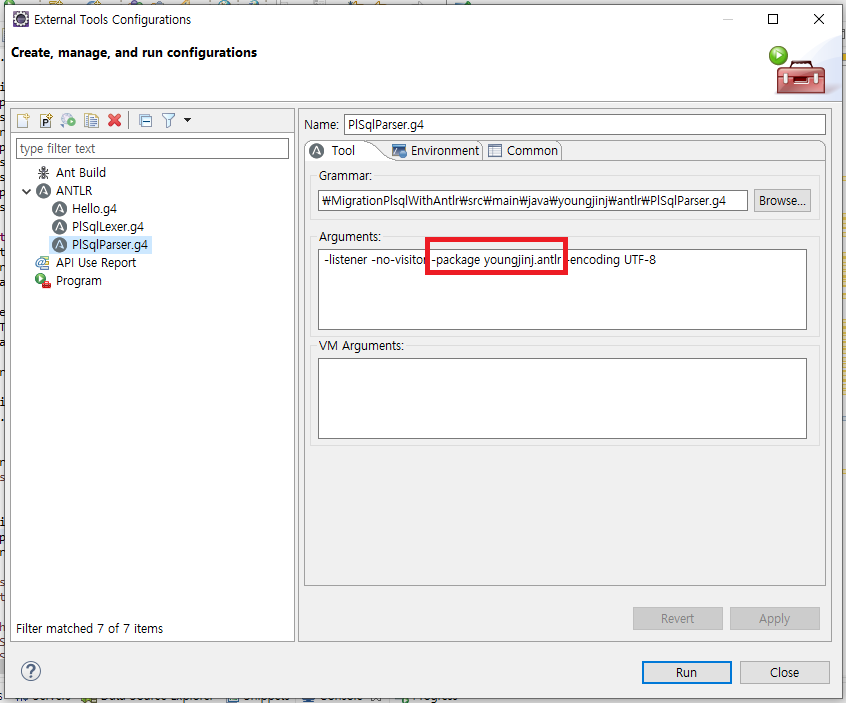
When you run 'Run AS > Generate ANTLR Recognizer', the parser classes are created in the 'target > generated-sources > antlr4' directory even if they are bundled into a package.
To make Eclipse aware of these files as sources, you must add the directory 'target > generated-source > antlr4' to 'Java Build Path > Source'.


5. Parsing PL/SQL with the created parser classes
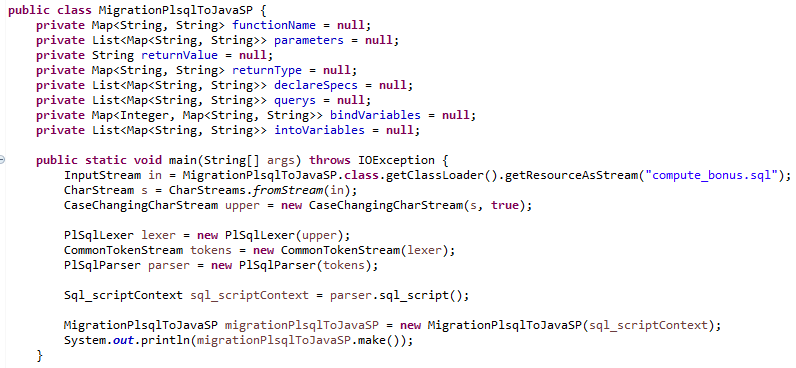
The MigrationPlsqlToJavaSP class reads the PL/SQL code in the compute_bonus.sql file and converts it to Java SP.
The PlSqlLexer and PlSqlParser classes are parser class files created by ANTLR using PL/SQL grammar files.
PL/SQL parsing starts with the code 'parser.sql_script();'.
By following the child class of the Sql_scriptContext class returned as a result of parsing, you can extract and process the data needed to create Java SP.
Lastly, the make() method, which is called by the MigrationPlsqlToJavaSP class, uses StringTemplate to create Java SP class file.
6. Testing the class that converts pre-developed PL/SQL to Java SP
The following figure is the result of running PL/SQL in the compute_bonus.sql on Oracle.
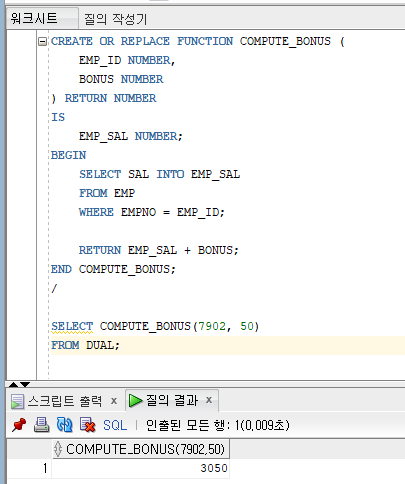
By following the result of parsing the compute_bonus.sql file, we extract and process the data needed to create a Java SP.

StringTempate, which provides template syntax, is used to make data to be parsed and extracted into Java SP.
The official website introduces StringTemplate as follows.
"StringTemplate is a java template engine (with ports for C#, Objective-C, JavaScript, Scala) for generating source code, web pages, emails, or any other formatted text output. (https://www.stringtemplate.org/ - What is StringTemplate?)"

Below is the Java code converted to Java SP.

The example table in Oracle was transferred to CUBRID for testing.

It outputs the same result as when running PL/SQL in Oracle.
Last but not least...
So far, we can only convert the SELECT queries that are executed in the PL/SQL function.
The query can be executed from PL/SQL code or returning result value with just simple operations.
ANTLR grammar allows us to parse all these parts. However, there are parts that are difficult to convert to Java code, so we haven't been able to proceed yet.
In the future, I would like to make a tool that converts PL/SQL to Java SP easily by refining the part that converts PL/SQL to Java SP and adding parts that can only be parsed but cannot be converted.
Since ANLTR supports the grammar of various programming languages besides PL/SQL, I think it is a good tool.
Reference
1. ANTLR
- homepage: https://www.antlr.org/
-document: https://github.com/antlr/antlr4/blob/master/doc/index.md
- grammar files:
* https://github.com/antlr/grammars-v4
* https://github.com/antlr/grammars-v4/wiki
- ANTLR IDE
* https://www.antlr.org/tools.html
* https://github.com/jknack/antlr4ide
2. StringTemplate
- homepage: https://www.stringtemplate.org/
The source can be found below.
https://github.com/youngjinj/migration-plsql-to-cubrid-with-antlr.git