
BLOG
-
Read More
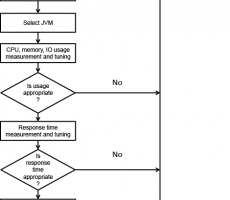
Become a Jave GC Expert Series 5 : The Principles of Java Application Performance Tuning
Written by Se Hoon Park on 06/30/2017 This is the fifth article in the series of "Become a Java GC Expert". In the first issue Understanding Java Garbage Collection we have learned about the processes for different GC algorithms, about how GC works, what Young and Old Generation is, what you should know about the 5 types of GC in the new JDK 7, and what the performance implications are for each of these GC types. In the second article How to Monitor Java Garbage Collection we have explained how JVM actually runs the Garbage Collection in the real time, how we can monitor GC, and which tools we can use to make this process faster and more effective. In the third article How to Tune Java Garbage Collection we have shown some of the best options based on real cases as our examples that you can... -
Read More
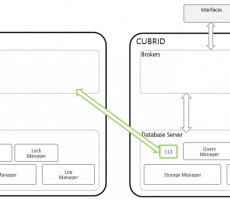
CUBRID DBLink
Written by DooHo Kang on 27/06/2022 What is CUBRID DBLink When retrieving information from a database, it is often necessary to retrieve information from an external database. Therefore, it is necessary to be able to search for information on other databases. CUBRID DBLink allows users to use the information on other databases. CUBRID DBLink provides a function to inquire about information in the databases of homogeneous CUBRID and heterogeneous Oracle and MySQL. * It is possible to set up multiple external databases, but when searching for information, it is possible to inquire about information from only one other database. CUBRID DBLink Configuration CUBRID DBLink supports DBLink between homogeneous and heterogeneous DBLinks. Homogeneous DBLink diagram If you look at the conf... -
Read More
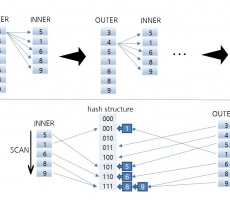
CUBRID INSIDE: HASH SCAN Method
Written by SeHun Park on 11/09/2021 - HASH SCAN Hash Scan is a scan method for hash join. Hash Scan is applied in view or hierarchical query. When a subquery such as view is joined as inner, index scan cannot be used. In this case, performance degradation occurs due to repeated inquiry of a lot of data. In this situation, Hash Scan is used. The picture above shows the difference between Nested Loop join and Hash Scan in the absence of an index. In the case of NL join, the entire data of INNER is scanned as many as the number of rows of OUTER. In contrast, Hash Scan scans INNER data once when building a hash data structure and scans OUTER once when searching. Therefore, you can search for the desired data relatively very quickly. Here, the internal structure of Hash Scan is written as the fl... -
Read More

CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Subquery Unnest)
Written by SeHun Park on 08/07/2021 What is Subquery A subquery is a query that appears inside another query statement. Subquery enables us to extract the desired data with a single query. For example, if you need to extract information about employees who have salary that is higher than last year’s average salary, you can use the following subquery: It is possible to write a single query as above without writing another query statement to find out the average salary. Subquery like this has various special properties, and their properties vary depending on where they are written. scalar subquery: A subquery in a SELECT clause. Only one piece of data can be viewed. inline view: A subquery in the FROM clause. Multiple data inquiry is possible. subquery: A subquery in the WHERE clause. I... -
Read More
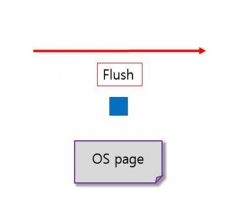
CUBRID INTERNAL: CUBRID Double Write Buffer
Written by MyungGyu Kim on 03/08/2022 INTRODUCTION Data in the database is allocated from disk to memory, some data is read and then modified, and some data is newly created and allocated to memory. Such data should eventually be stored on disk to ensure that it is permanently stored. In this article, we will introduce one of the methods of storing data on disk in CUBRID to help you understand the CUBRID database. The current version at the time of writing is CUBRID 11.2. DOUBLE WRITE BUFFER First of all, I would like to give a general description of the definition, purpose, and mechanism of Double Write Buffer. What is Double Write Buffer? By default, CUBRID stores data on disk through Double Write Buffer. Double Write Buffer is a buffer area composed of both memory and disk. By default, t...
Join the CUBRID Project on