Written by MyungGyu Kim on 03/08/2022
INTRODUCTION
Data in the database is allocated from disk to memory, some data is read and then modified, and some data is newly created and allocated to memory. Such data should eventually be stored on disk to ensure that it is permanently stored. In this article, we will introduce one of the methods of storing data on disk in CUBRID to help you understand the CUBRID database.
The current version at the time of writing is CUBRID 11.2.
DOUBLE WRITE BUFFER
First of all, I would like to give a general description of the definition, purpose, and mechanism of Double Write Buffer.
What is Double Write Buffer?
By default, CUBRID stores data on disk through Double Write Buffer. Double Write Buffer is a buffer area composed of both memory and disk. By default, the size is set to 2M, and the size can be adjusted up to 32M in the cubrid.conf file.
*Note: In CUBRID, the user can store the DB page directly to disk or using Double Write Buffer. In this article, we will only focus on the method of storing DB page using Double Write Buffer.
The Purpose
When storing data on a disk, the Double Write Buffer generated in this way may prevent the corrupted DB page from being stored. The DB page-level corruption occurs for the following reasons:

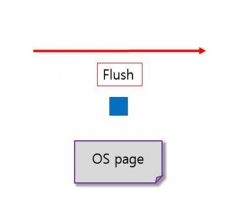
In this document, it is assumed that 1 DB page existing in memory consists of 4 OS pages of Linux or Windows. When such a DB page is stored on disk, it is stored through a mechanism called flush.
When the DB page is stored to the disk through the flush mechanism, the DB page is divided and stored in units of OS pages. As shown in the figure above, if the system is shut down abruptly when the DB page is not stored on the disk, the DB page is broken. (Note: This disk write is called Partial Write.)
The Process
The DB page of CUBRID is stored on disk as follows through the Double Write Buffer.
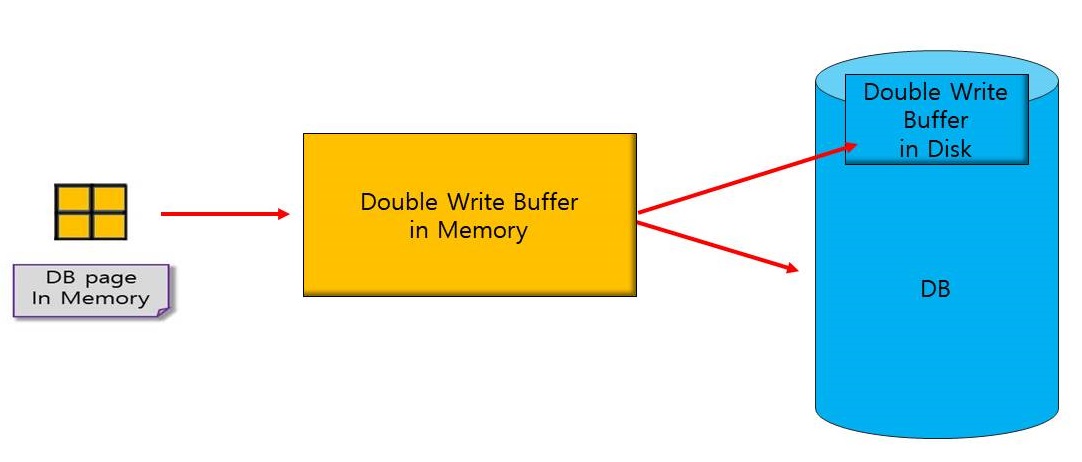
As above, one DB page composed of 4 OS pages is stored in the Double Write Buffer in memory. After that, it is stored once in the DB internal Double Write Buffer and twice in the DB file.
The process of storing in Double Write Buffer in memory can be described in detail as follows:
- DB pages are stored in one slot in the Double Write Buffer of memory, and these slots are combined to form a block. (The green square in the figure below is one block).
- These contiguous blocks are called Double Write Buffer in memory.
- When one block is full of slots, it is stored to the disk through a mechanism called flush, which proceeds in blocks.
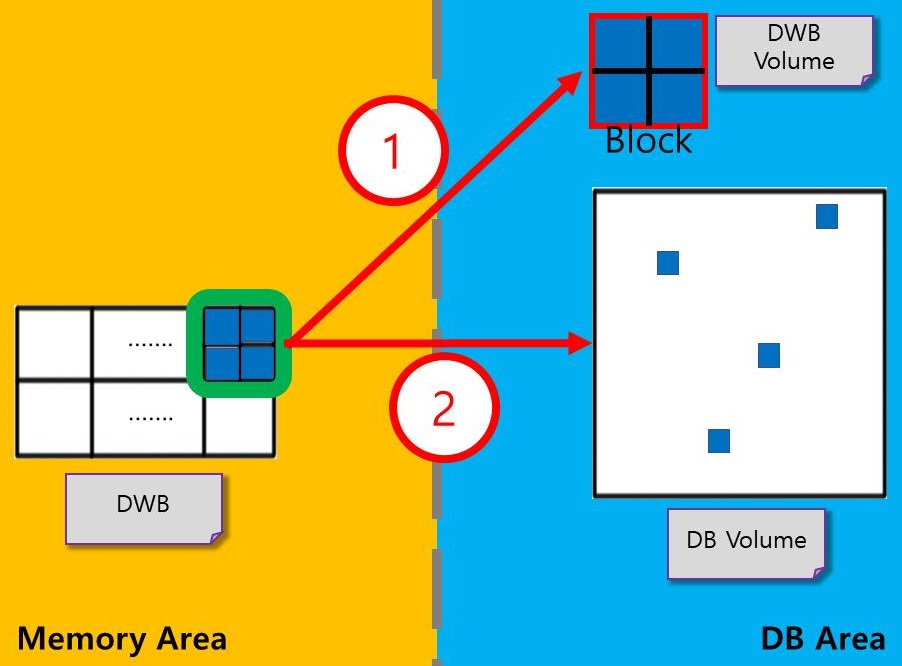
The process of storing DB page from the Double Write Buffer in memory to the DB on disk executes the following two processes in order:
- A single block full of slots is stored in the DB internal Double Write Buffer.
- Store the page to disk located in the same location as the stored page in a single block.
When data storage in the DB internal Double Write Buffer fails
In this case, in order to prevent the broken data from being stored on disk, the CUBRID server is stopped during the process of the server restart or creating a new Double Write Buffer, so that data not yet written to the disk is written.
When data storage in the disk internal DB fails
After allocating the Double Write Buffer stored in the DB to the memory, the page inside the block is compared with the page stored inside the DB. It prevents the DB page from being saved to the disk in a broken state by re-flushing only the broken DB page in the DB area.
When the DB page is stored in the DB
The Double Write Buffer inside the DB remains the same, and the next block is overwritten when the DB page is stored on the disk through the flush. That is, the Double Write Buffer is continuously maintained.
CONCLUSION
Through the above process, the DB page using the Double Write Buffer can be stored and the broken DB page can be prevented from being stored.
REFERENCE
- CUBRID Manual - https://www.cubrid.org/manual/en/11.0/
- CUBRID Source Code - https://github.com/CUBRID/cubrid
 CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Sub...
CUBRID INSIDE: Subquery and Query Rewriter (View Merging, Sub...