Written by DooHo Kang on 27/06/2022
What is CUBRID DBLink
When retrieving information from a database, it is often necessary to retrieve information from an external database. Therefore, it is necessary to be able to search for information on other databases. CUBRID DBLink allows users to use the information on other databases.
CUBRID DBLink provides a function to inquire about information in the databases of homogeneous CUBRID and heterogeneous Oracle and MySQL.
* It is possible to set up multiple external databases, but when searching for information, it is possible to inquire about information from only one other database.
CUBRID DBLink Configuration
CUBRID DBLink supports DBLink between homogeneous and heterogeneous DBLinks.
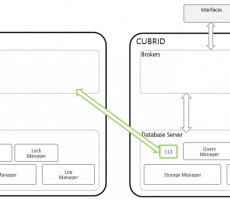
- Homogeneous DBLink diagram
If you look at the configuration diagram for inquiring about information of a homogeneous database, you can use CCI in Database Server to connect to homogeneous brokers and inquire about information from an external database.

- Heterogeneous DBLink diagram
If you look at the configuration diagram for inquiring about the information in heterogeneous databases, you can inquire about information in heterogeneous databases through GATEWAY.
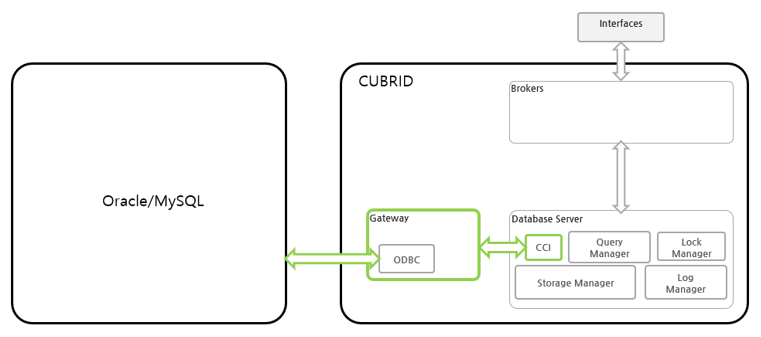
*GATWAY uses ODBC (Open DataBase Connectivity).
Please refer to CUBRID 11.2 manual for detailed information about GATWAY.
Setting Up CUBRID DBLink
- Homogeneous DBLink Setting
If you look at the Homogeneous configuration diagram above, you need to connect to the broker of the external database, so you need to set up the broker for the external database. This setting is the same as the general broker setting.
- Heterogeneous DBLink Setting
It is necessary to set the information to connect to a heterogeneous type (Oracle/MySQL), and the heterogeneous setting value must be written in GATEWAY.
GATEWAY can be configured through the parameters of cubrid_gateway.conf .
(For reference, since GATEWAY uses ODBC, unixODBC Driver Manager must be installed for Linux.)
This is an example of DBLink configuration in cubrid_gateway.conf.

How to Use CUBRID DBLink
In the case of setting up homogeneous brokers and heterogeneous gateways, let’s look at how to write Query statements to inquire about database information. There are two ways to write a DBLINK Query statement for data inquiry.
First, how to query information from other databases by writing DBLINK syntax in the FROM clause. The Query statement below is a Query statement that inquires about the remote_t table information of another database of IP 192.168.0.1.

As you can see in the above syntax, you can see the SELECT statement for retrieving connection information and other database information, It is divided into three parts: the virtual table and column name corresponding to the SELECT statement.
Secondly, DBLINK Query statement requires connection information to connect to other databases. If the connection information is the same and only the SELECT statement needs to be changed, the connection information is updated every time a Query statement is written. and there is a risk that user information (id, password) is exposed to the outside.
Therefore, if you use the CREATE SERVER statement for such trouble and information protection, it is simpler than the Query statement and helps to protect user information.

If you look at the above syntax, you can replace the Connection information with remote_srv1.
Retrieving Information from External Database using CUBRID DBLink
Now that we have completed the setup for using CUBRID DBLink, we can retrieve information from the CUBRID database and other databases.
The example below shows CUBRID information and MySQL information by retrieving MySQL information from CUBRID.
- CUBRID Table Information

- MySQL Table Information

- DBLink Query

- DBLink Query Execution Result

This is the result of searching CUBRID information and MySQL information at the same time.
 Become a Jave GC Expert Series 5 : The Principles of Java Ap...
Become a Jave GC Expert Series 5 : The Principles of Java Ap...
 CUBRID INSIDE: HASH SCAN Method
CUBRID INSIDE: HASH SCAN Method