관리하기¶
호스트 관리하기¶
호스트 연결¶
좌측 호스트 탐색 창 > 그룹 이름 펼침 > 호스트 이름 더블 클릭
CUBRID 매니저를 설치 후 처음 실행하게 되면 호스트 탐색 트리에 "localhost"라는 호스트가 기본으로 설정되어 있다. 현재 CUBRID 매니저 클라이언트가 실행되는 PC에 구동 중인 CUBRID 매니저 서버가 있다는 가정 아래 설정된 것이며, CUBRID 매니저 접속에 대한 기본 정보를 알려주기 위해 제공된다.
호스트 이름을 더블클릭하면 편집 창이 팝업되는데, 편집할 호스트 정보는 아래와 같다.
- 호스트 이름: 호스트 이름은 CUBRID 매니저 내에서 관리하고자 하는 호스트를 구분하는 구분자로, 유일한 이름을 부여한다. 내부적으로 관리하는 호스트 구분자는 "호스트 주소와 연결 포트"이다. 호스트 이름으로는 숫자와 알파벳만 입력할 수 있으며, 공백을 포함할 수 없다. 호스트 이름의 길이는 최소 4자리 최대 32자리이다.
- 호스트 주소: 호스트 주소는 공백이거나 공백을 포함할 수 없다.
- 연결 포트: 연결 포트는 1024와 65535 사이의 정수만 입력할 수 있다. 기본 포트 값은 8001이며, 접속이 안 될 경우 CUBRID/conf/cm.conf 파일의 cm_port 값을 확인한다.
- 사용자 이름: CUBRID 매니저의 관리자 권한을 가진 사용자는 admin이며, 설치 후 처음 사용할 때에는 반드시 admin 계정으로 접속해야 한다. 사용자 이름으로는 숫자와 알파벳만 입력할 수 있으며, 공백을 포함할 수 없다. 사용자 이름의 길이는 최소 4자리 최대 32자리이다.
- 비밀번호: CUBRID 매니저의 관리자 권한을 가진 admin 사용자의 최초 비밀번호는 "admin"이다. admin 사용자가 최초 연결할 때 비밀번호를 재설정하지 않으면 접속할 수 없다. 이때 재설정한 admin 사용자의 비밀번호는 분실하지 않도록 주의한다. 비밀번호는 "admin"으로 재설정할 수 없다. 비밀번호는 공백을 포함할 수 없으며, 비밀번호는 길이는 최소 4자리 최대 32자리이다.
- 비밀번호 저장: 비밀번호를 로컬에 저장한다. 선택하면 더블클릭해서 자동으로 이 호스트에 로그인할 수 있다. 선택하지 않으면 비밀번호를 입력하는 대화상자가 나타난다.
- 드라이버 버전: CUBRID 매니저에서 사용할 CUBRID JDBC 드라이버를 선택할 수 있다. 기본값은 "Auto Detect"로, 먼저 서버의 버전을 확인한 후 CUBRID 매니저에 등록된 JDBC 드라이버 중 동일한 버전이 있는가를 확인하여 자동으로 연결한다. 연결할 수 있는 JDBC 드라이버가 없으면 다음과 같이 JDBC를 선택하여 등록하라는 확인 메시지가 출력된다.
- 찾아보기: 클릭하면 다음과 같이 JDBC 드라이버 관리 대화상자가 나타난다.
호스트 추가¶
좌측 호스트 탐색 창 > 호스트 그룹에서 마우스 우버튼 클릭 > 호스트 추가
호스트를 추가하여, 여러 호스트에 존재하는 데이터베이스를 하나의 매니저에서 관리할 수 있다. 호스트를 추가하려면 다음 중 하나를 실행한다.
- 툴바에서 "호스트 추가"를 클릭한다.
- 메뉴에서 "파일 > 호스트 추가"를 선택한다.
- 호스트 탐색 트리에서 마우스 오른쪽 버튼을 클릭하고 "호스트 추가"를 선택한다.
호스트 이름, 호스트 주소, 연결 포트, 사용자 이름 그리고 비밀번호에 대한 자세한 내용은 기본 호스트 정보를 참조한다. 정보를 입력하고 "추가" 버튼을 클릭하면 호스트 탐색 트리에 추가만 하고 연결은 하지 않는다. 반면, "연결"을 클릭하면 탐색 트리에 추가하고 해당 호스트로 연결한다.
호스트 삭제¶
좌측 호스트 탐색 창 > 호스트 그룹 > 호스트 이름에서 마우스 우버튼 클릭 > 호스트 삭제
호스트 탐색 트리에 등록된 호스트 정보를 삭제한다. 호스트 삭제 시 하부 노드의 모든 정보가 같이 삭제된다. 단, CUBRID 매니저의 클라이언트 구성 정보만 삭제되는 것으로, CUBRID 매니저 서버에 구성된 정보까지 삭제되는 것은 아니다.
호스트 정보 내보내기/가져오기¶
상단 메뉴 > 파일 > 호스트 정보 가져오기/내보내기
다량의 데이터베이스 호스트를 관리하는 경우 관리하는 호스트 정보를 백업하거나 공유하는 용도로 호스트 정보 내보내기/가져오기 기능을 제공한다. 내보내기/가져오기를 할 경우 *.xml을 사용하며, 비밀번호는 포함하지 않는다.
- 호스트 정보 내보내기: 현재 관리중인 호스트 및 데이터베이스 정보를 xml 파일로 생성한다. 메뉴에서 "파일 > 호스트 정보 내보내기..."를 선택하면 나오는 호스트 정보 내보내기 대화창에서 내보낼 호스트 정보를 확인한 다음 내보낼 파일명을 찾아보기로 입력한 후 "OK"를 클릭하여 xml 파일로 생성한다.
- 호스트 정보 가져오기: "호스트 정보 내보내기..."를 이용하여 저장한 xml 파일을 가져와서 사용중인 CUBRID 매니저에 추가한다. 단, 동일한 이름의 호스트 정보는 가져올 수 없다.
워크스페이스 가져오기¶
상단 메뉴 > 파일 > 워크스페이스 가져오기
CUBRID 매니저는 워크스페이스 개념으로 호스트 정보, 설정 정보를 관리한다. 신 버전을 별도의 경로에 설치할 경우 다음 2가지 방법으로 기존 정보를 마이그레이션할 수 있다. 신 버전 CUBRID 매니저 설치후 워크스페이스 선택시 기존 버전이 설치된 폴더 내부에 있는 workspace를 선택하거나 복사한 후 선택한다 신 버전 CUBRID 매니저 설치후 워크스페이스 선택시 기본 값을 사용하고 "파일 > 워크스페이스 가져오기..."를 이용하여 가져온다. 만약, 오래된 버전의 CUBRID 매니저의 사용 환경을 이용하려면 "워크스페이스 가져오기"를 이용해야 한다.
서비스 관리하기¶
CUBRID 매니저로 CUBRID 관련 서비스를 시작/정지할 수 있다. 이것은 CUBRID 데이터베이스 명령어인 cubrid 명령과 동일한 기능이다. 단, CUBRID 매니저 서버는 CUBRID 매니저 클라이언트를 통해서 구동/정지할 수 없다.
서비스 시작¶
좌측 호스트 탐색 창에서 호스트 이름 선택 > 상단 메뉴 > 도구 > 서비스 시작
좌측 탐색 창에서 특정 호스트 이름을 선택한 후 메뉴에서 "도구 > 서비스 시작"을 선택하면, "서비스 구동 설정"에서 선택한 서비스와 데이터베이스를 시작한다. "서비스 구동 설정" 메뉴를 선택하려면 아래의 경로를 따라가면 된다.
좌측 호스트 탐색 창 > 호스트 이름(마우스 우클릭) > 속성 > 매개 변수 구성 > 서비스 구동 설정
호스트 이름에 대고 마우스 우버튼을 클릭하고 "속성"을 선택하여 "서비스 구동 설정"에서 시작할 서비스와 데이터베이스를 선택한다. 시작할 서비스에는 server, broker, manager가 있는데, manager의 선택 여부는 비활성화 되어 있다. (CUBRID 매니저에서 관리 기능을 사용하려면 매니저 서버를 구동한 상태여야 하기 때문이다.)
"서비스 구동 설정"에서 "server"를 선택했을 경우에만 우측 하단의 "자동 시작 데이터베이스 설정" 창이 활성화된다.
데이터베이스 시작/정지¶
좌측 호스트 탐색 창 > 데이터베이스 이름(마우스 우클릭) > 데이터베이스 시작/정지
선택한 데이터베이스를 시작 및 정지하려면, 다음 중 한 가지를 실행한다.
- 툴바에서 "시작" 또는 "정지"를 클릭한다.
- 데이터베이스 이름에서 마우스 오른쪽 버튼을 클릭하고 "데이터베이스 시작" 또는 "데이터베이스 정지"를 선택한다.
- 메뉴의 "동작"에서 "데이터베이스 시작" 또는 "데이터베이스 정지"를 선택한다.
브로커 시작/정지¶
좌측 호스트 탐색 창 > 브로커 이름에서 마우스 우클릭 > 데이터베이스 시작/정지/재시작
좌측 호스트 탐색 창에서 대상 브로커를 먼저 선택한 후, 해당 브로커를 시작, 정지 또는 재시작하려면 다음 중 한 가지를 실행한다.
- 툴바에서 "시작" 또는 "정지"를 클릭한다.
- 브로커 이름에서 마우스 오른쪽 버튼을 클릭하고 "브로커 시작", "브로커 정지" 또는 "브로커 재시작"을 선택한다.
- 메뉴의 "동작"에서 "브로커 시작" 또는 "브로커 정지"를 선택한다.
데이터베이스 볼륨 관리하기¶
CUBRID 서버를 설치후 CUBRID 매니저로 접속을 하면 demodb가 기본으로 존재하는 것을 볼 수 있다. 이 장에서는 예를 통해 데이터베이스를 새로 생성하고 삭제하는 방법에 대해 알아본다.
데이터베이스 생성¶
우리가 생성하고자 하는 데이터베이스 사양은 아래와 같다.
- 데이터베이스 이름: testdb
- 페이지크기: 16384
- 콜레이션(문자집합): ko_KR.utf8
- 일반 볼륨, 로그 볼륨: 기본 크기(512MB)
- 데이터 볼륨: 500MB
- 인덱스 볼륨: 200MB
- 임시 볼륨: 300MB
- 비밀번호: testpw
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb 마우스 우클릭) > 데이터베이스 생성
좌측 호스트 탐색 창에 보이는 testdb를 마우스 우클릭하여 팝업된 메뉴에서, "데이터베이스 생성..."을 클릭한다.
생성 1단계¶
- 데이터베이스 이름에 testdb를 입력한다.
- 원하는 문자 집합을 선택한다. 여기서는 ko_KR.utf8을 선택한다.
- 나머지는 입력한 값을 따른다.
- "다음"을 클릭한다.
생성 2단계¶
추가 볼륨을 설정하는 것으로 일반 볼륨을 추가하는 것보다 데이터 볼륨, 인덱스 볼륨을 구분하여 추가하는 것을 권장한다.
기본적으로 512MB씩 추가가 되어 있는데 이를 모두 삭제하고 다시 추가하도록 하겠다.
- "추가 볼륨 리스트"에 등록된 볼륨을 모두 선택한 후 "볼륨 삭제"를 선택해서 모두 삭제한다.
- 데이터 볼륨을 추가하기 위해 볼륨 형식을 data로 선택하고, 볼륨 크기에 500을 입력한 후 "볼륨 추가"를 클릭한다.
- 인덱스 볼륨을 추가하기 위해 볼륨 형식을 index로 선택하고, 볼륨 크기에 200을 입력한 후 "볼륨 추가"를 클릭한다.
- 임시 볼륨을 추가하기 위해 볼륨 형식을 temp로 선택하고, 볼륨 크기에 300을 입력한 후 "볼륨 추가"를 클릭한다.
- "다음"을 클릭한다.
생성 3단계¶
데이터 볼륨과 인덱스 볼륨의 자동 추가를 설정한다.
- 볼륨 자동 추가 기능 사용: 추가된 데이터베이스 볼륨의 용량이 모두 사용되었을 경우 자동 확장할 수 있는 옵션으로 여유 공간 비율만큼 공간이 남으면 볼륨 크기만큼 확장하는 기능이다. 데이터와 인덱스 둘다 선택을 하고 기본값을 사용한다.
- 여유 공간 비율: 기본값(15%) 그대로 유지한다. "여유 공간 비율"에 지정한 값과 남은 볼륨이 같을 때, 자동으로 볼륨을 추가한다는 의미이다. 예를 들어, 여유 공간 비율이 5%이면, 기존 볼륨의 여유 공간이 5% 남았을 때, 자동으로 데이터 볼륨을 추가한다. 최소 값은 5%이고 최대 값은 30%이다.
- 볼륨 크기: 기본값(512MB) 그대로 유지한다.
- "다음"을 클릭한다.
생성 4단계¶
- DBA 계정의 비밀번호를 testpw로 입력한다.
- "다음"을 클릭한다.
생성 5단계¶
지금까지 입력한 정보가 출력된다. 이대로 데이터베이스의 생성을 결정하려면 "완료"를 클릭하여 생성을 진행한다.
입력한 데이터베이스 볼륨의 크기에 따라 데이터베이스 생성에 소요되는 시간이 다름에 유의한다.
데이터베이스 생성이 완료되면 안내창이 뜨고 "확인"을 클릭하면 생성된 데이터베이스를 왼쪽 호스트의 데이터베이스 항목에서 볼 수 있다.
사용 공간 확인¶
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb) 더블 클릭
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb) > 저장 공간 더블 클릭
데이터베이스 이름을 더블 클릭했을 때와 "저장 공간" 메뉴를 더블 클릭했을 때 출력되는 형태가 다르다.
- 데이터베이스 이름을 더블 클릭하면 상세 볼륨 정보가 테이블 형태로 출력되며, 볼륨 정보 뿐 아니라 데이터베이스, 브로커, 트랜잭션 정보를 제공한다.
- 저장 공간 메뉴를 더블 클릭하면 볼륨 정보가 파이 그래프 형태로 출력된다.
백업¶
테스트를 위해 테이블 추가¶
우선 앞서 생성한 testdb에 테이블을 하나 추가하기로 하겠다.
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb) > 테이블(마우스 우클릭) > 테이블 추가
테이블 이름을 num_table로 입력한다.
다음으로 칼럼을 추가해야 하는데, 칼럼 이름에 num을 입력하고, 데이터 유형(타입)은 BIGINT로 선택한 후 "확인"을 클릭하면 테이블이 생성된다.
데이터베이스 정지¶
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb 마우스 우클릭) > 데이터베이스 정지
백업은 온라인/오프라인 백업을 모두 지원하고 있으나 튜터리얼에서는 오프라인 백업하는 방법으로 설명한다. 백업하기 전에 데이터베이스를 종료한다. testdb 데이터베이스를 선택후 "데이터베이스 정지"를 클릭한다.
데이터베이스 백업 Level0¶
좌측 호스트 탐색 창 > 데이터베이스 이름(testdb 마우스 우클릭) > 데이터베이스 관리 > 데이터베이스 백업
최초 백업이기 때문에 백업 수준은 Level0만 볼 수 있다. "확인"을 눌러 현재 상태로 백업을 한다. 백업 디렉토리가 없을 경우 백업 디렉토리 생성 대화창이 출력되는데 "확인"을 클릭하면 계속 진행할 수 있다.
참고로, 방금 실행한 Level0 백업은 전체 백업(full backup)에 속한다. 백업 옵션과 관련된 상세 정보는 CUBRID 메뉴얼을 참고한다.
앞서 팝업된 데이터베이스 백업 창 > 백업 정보 탭 또는 백업 수행 이력 탭
백업 정보 탭에서 백업 볼륨의 경로와 백업 경로를 확인할 수 있다.
백업 수행 이력 탭에서 백업 이력을 확인할 수 있다.
백업 자동화¶
좌측 탐색 창 > 데이터베이스 이름 펼침 > 하단에 작업 자동화 > 백업 자동화
CUBRID 매니저 서버를 통해서 주기적으로 백업을 수행하고자 하는 경우 백업 자동화 기능을 사용하며, "백업 자동화 추가" 메뉴에서 관련 정보를 설정한다.
백업 자동화 기능은 매니저 서버가 구동 중인 상태에서 dba 사용자가 설정할 수 있으며, 해당 데이터베이스의 구동/중지 상태와는 무관하다.
- 백업 ID: 백업 작업의 이름을 설정한다. 백업 계획이 여러 개일 수 있으므로, 하나의 데이터베이스 내에서는 유일해야 한다.
- 백업 수준: 0, 1, 2 중에서 선택할 수 있다. 0레벨은 전체 백업을 의미하고, 1레벨은 0레벨 백업 이후의 변경 내역만 백업하는 1차 증분 백업(incremental backup)을 의미하며, 2레벨은 1레벨 백업 이후의 변경 내역만 백업하는 2차 증분 백업을 의미한다. 즉, 0레벨 전체 백업본이 존재할 때에만 1 또는 2레벨 백업 작업이 자동 수행된다.
- 백업 경로: 백업 볼륨이 저장된 디렉터리를 설정한다.
- 백업 주기: 백업을 수행할 주기를 매월, 매주, 매일, 특정일 중에서 선택할 수 있다.
- 상세 주기: 선택한 백업 주기를 상세하게 설정할 수 있다.
- 백업 시간: 자동 백업을 수행할 시간을 입력한다. 시간과 분을 각각 입력한다.
- 옵션: 자동으로 수행할 백업 작업의 옵션을 지정할 수 있다. 자세한 정보는 CUBRID 온라인 매뉴얼의 "데이터베이스 백업"을 참고한다.
- 예전 백업 파일 보존: 현재 데이터베이스의 기존 백업 볼륨 파일을 database_directory/backupold 디렉터리에 저장하는 옵션이다.
- 보관 로그 볼륨 삭제: 백업 시, 보관 로그 볼륨들을 삭제한다. 해당 데이터베이스 서버가 복제 마스터 서버로 설정되어 있는 상태에서 보관 로그 볼륨 삭제를 수행하면, 자동으로 복제에 영향이 없는 부분까지만 삭제한다.
- 백업 후 데이터베이스 통계 정보 갱신: 백업 수행 후, 통계 정보를 갱신한다.
- 데이터베이스 일관성 검사: 백업 시, 데이터베이스의 일관성 검사를 수행한다.
- 압축 백업 사용: 백업 시, 압축을 사용한다.
- 병렬 백업(스레드 수): 백업 시, 몇 개의 스레드를 동시에 이용할 것인지를 설정할 수 있다. 최대값은 CPU 개수만큼 설정하는 것이 적절하며, 기본값은 0이다. 기본값으로 설정된 경우 시스템에 의해 자동으로 스레드 개수가 결정된다.
- 온라인 백업: 데이터베이스가 구동 중인 상태에서만 자동 백업을 실행한다. 중지 상태에서는 데이터베이스를 백업하지 않고 에러 로그만 기록한다.
- 오프라인 백업: 데이터베이스가 중단 상태일 때만 자동 백업을 실행한다. 데이터베이스가 구동 중이면 데이터베이스를 강제 중단하고 자동 백업을 수행한 후, 다시 데이터베이스를 구동한다.
백업 자동화 수행 로그¶
"백업 자동화 수행 로그" 메뉴에서 자동으로 수행한 백업 작업에 대한 로그를 확인할 수 있다. 백업 대상 데이터베이스, 백업 ID, 백업 수행 시간 등의 정보가 기록된다
복구¶
이제 복구 과정을 살펴보기 위해, 먼저 테이블을 임의로 삭제한 후 앞에서 생성한 백업 파일로 testdb를 복구해보자.
테이블 삭제¶
좌측 탐색 창에서 num_table 선택 (마우스 우클릭) > 테이블 관리 > 테이블 삭제
다시 데이터베이스를 시작한 후 테스트를 위해 추가하였던 테이블을 선택한다. 그리고, 마우스 우클릭으로 나오는 메뉴에서 "테이블 관리 > 테이블 삭제"를 클릭하여 테이블을 삭제한다.
삭제 이후 현재 테이블이 없는 상태인데, 데이터베이스 복원을 통해 테이블을 복구하도록 하겠다.
데이터베이스 정지¶
좌측 탐색 창에서 testdb 선택(마우스 우클릭) > 데이터베이스 정지
데이터베이스 백업은 데이터베이스가 시작된 상태에서 가능하지만 복구는 데이터베이스가 종료된 상태에서만 가능하다. 현재 데이터베이스가 동작중이면 testdb 데이터베이스를 선택후 "데이터베이스 정지"를 클릭한다.
데이터베이스 복구¶
좌측 탐색 창에서 testdb 선택(마우스 우클릭) > 데이터베이스 관리 > 데이터베이스 복구
데이터베이스 복구를 위해 testdb 데이터베이스를 선택 후 "데이터베이스 복구"를 선택하여 데이터베이스 복구 대화창을 출력한다.
여기에서는 "복구 데이터"의 "복구 시점 선택"에는 "백업 시점으로 복구"를 선택하고, "가용한 백업 정보를 선택"에서는 최근 백업한 0 레벨 파일을 선택한 다음 "확인"을 클릭한다.
오류 없이 복구가 완료되었으면 데이터베이스를 시작하여 테이블이 복구되었는지 확인한다.
데이터베이스 삭제¶
이제 testdb를 삭제해보자. 데이터베이스가 정지되지 않았다면 정지한다.
좌측 탐색 창에서 testdb 선택(마우스 우클릭) > 데이터베이스 관리 > 데이터베이스 삭제
위에 기술한 순서대로 데이터베이스를 삭제한다.
데이터베이스 삭제 > 백업 볼륨도 같이 삭제함
데이터베이스 삭제 대화창에서 "백업 볼륨도 같이 삭제함"을 체크한 후 "확인"을 클릭한다.
스키마 관리하기¶
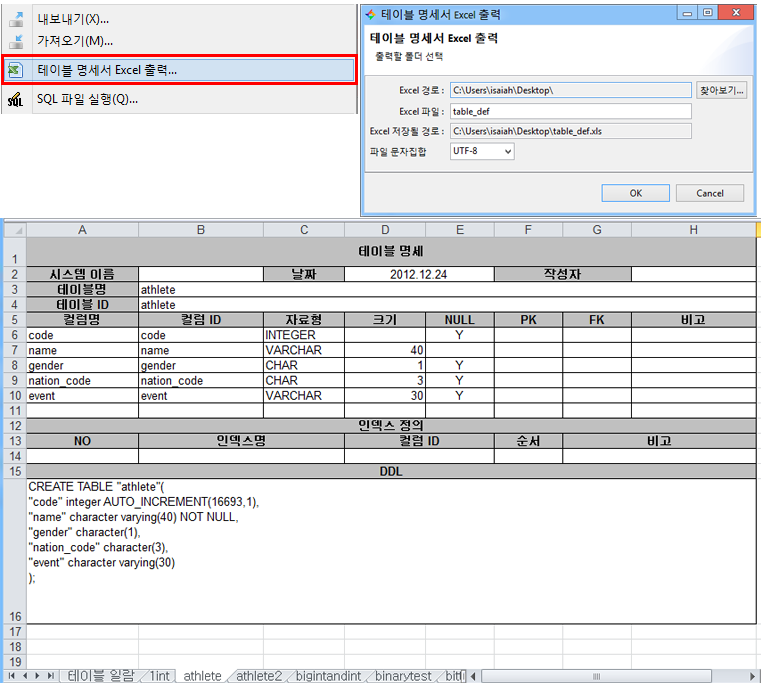
테이블 명세 엑셀 출력¶
좌측 탐색 창에서 데이터베이스 이름 선택(마우스 우클릭) > 테이블 명세서 Excel 출력
큐브리드 매니저는 데이터베이스의 모든 테이블 명세를 엑셀로 출력하는 기능을 제공한다. 테이블 목록과 각 테이블별 상세 스키마 정보를 표로 제공하며, 테이블 칼럼/설명 기능을 이미 사용하고 있다면 이미 입력된 설명과 함께 출력된다.
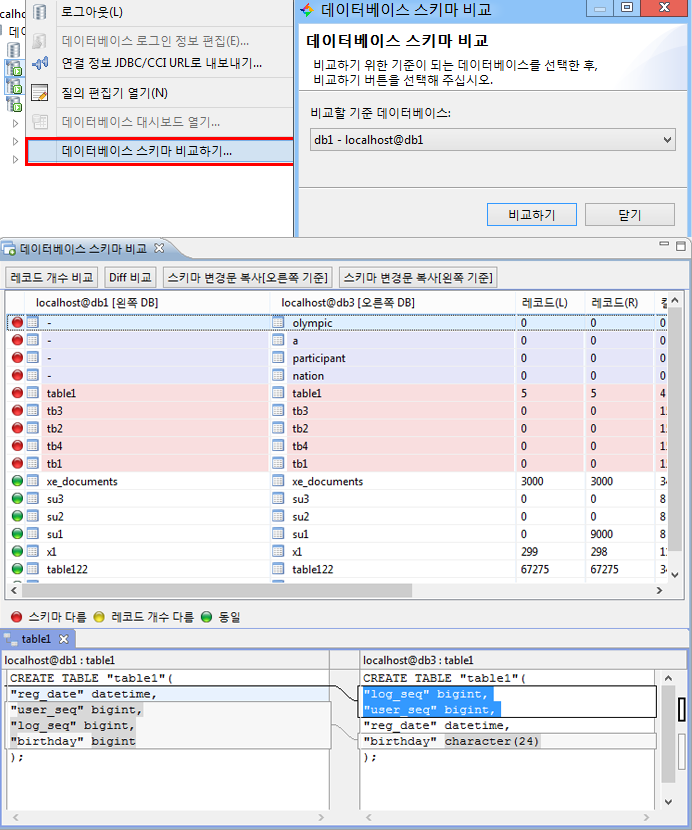
스키마 비교¶
좌측 탐색 창에서 데이터베이스 이름 선택(마우스 우클릭) > DB 스키마 비교 마법사
두 개 이상의 데이터베이스를 선택후 데이터베이스 스키마 비교 기능이 단순히 차이를 비교하는 기능을 넘어 각 테이블별 칼럼, PK, 인덱스 등 상세 분석과 레코드 개수까지 동시에 비교할 수 있다.
HA로 구성된 서버의 마스터와 슬레이브 노드를 비교하는 용도로도 사용될 수 있다.
CUBRID 매니저 사용자 관리하기¶
도구 메뉴 > CM 관리자 편집
하나의 데이터베이스에 여러 사용자를 등록하고 사용자 권한을 관리하듯이, 매니저 서버에도 여러 사용자를 등록하고 사용자 권한을 관리할 수 있다.
매니저 사용자 정보는 CUBRID 매니저 서버에서 저장되며, 해당 호스트에 접속하기 위해서는 반드시 사전에 CUBRID 매니저 사용 권한을 취득해야 한다.
CUBRID 매니저에는 관리자 계정인 admin과, admin이 등록한 일반 사용자만 접속할 수 있다. 그리고 CUBRID 매니저 사용자 관리 기능은 admin에게만 허용된다.
"CM 관리자 편집" 메뉴에서는 각 사용자에게 다음의 권한을 설정할 수 있다. (CM은 CUBRID Manager를 뜻한다.)
- DB 생성 권한
- admin: 새 데이터베이스를 생성할 수 있는 권한을 의미하며, 오직 관리자 계정인 admin 사용자한테만 부여된다.
- none: 권한이 없음을 의미한다.
- 브로커 권한
- admin: 브로커를 시작/정지할 수 있고 브로커를 추가, 편집, 삭제할 수 있는 관리 권한을 의미한다.
- monitor: 브로커의 상태 보기 기능을 통해 브로커의 진행 상황을 모니터링할 수 있는 권한을 의미한다.
- none: 권한이 없음을 의미한다.
- 상태 모니터 권한
- admin: 상태 모니터를 수행할 수 있고 추가, 편집, 삭제할 수 있는 관리 권한을 의미한다.
- monitor: 상태 모니터를 수행하여 모니터링할 수 있는 권한을 의미한다.
- none: 권한이 없음을 의미한다.
CUBRID 매니저 사용자 추가¶
도구 > CM 관리자 편집 > 추가 버튼
CM 관리자 편집 창에서 추가 버튼을 클릭하면 사용자 추가 창이 팝업되고, 이 창에서 CUBRID 매니저 사용자 계정 정보 및 권한 설정과 데이터베이스 접속 권한 설정을 할 수 있다.
CUBRID 매니저 사용 계정 이름 및 권한 설정¶
도구 > CM 관리자 편집 > 추가 버튼
CM 관리자 편집 창에서 추가 버튼을 클릭하면 사용자 추가 창이 팝업되고, 여기에서 사용자 이름, 비밀번호, 권한을 편집할 수 있다.
- 사용자 이름: 사용자 이름의 길이는 최소 4자리 최대 32자리이다. 사용자 이름으로는 숫자와 알파벳만 입력할 수 있으며, 공백을 포함할 수 없다. 사용자 이름으로 "admin"을 사용할 수 없으며, 사용자 이름은 해당 호스트 내에서 유일해야 한다.
- 비밀번호: 비밀번호의 길이는 최소 4바이트 최대 32바이트이며, 공백을 포함할 수 없다. 비밀번호로 "admin"을 사용할 수 없다.
CUBRID 매니저 사용자에게 데이터베이스 권한 설정¶
도구 > CM 관리자 편집 > 추가 버튼
CM 관리자 편집 창에서 추가 버튼을 클릭하면 사용자 추가 창이 팝업되고, 여기에서 사용자를 추가한 후 "Next > " 버튼을 누르면 다음에 나타나는 화면에서 연결 권한, DB 계정, 브로커 주소, 브로커 포트를 편집할 수 있다.
- 연결 권한: 추가 중인 CUBRID 매니저 사용자가 연결할 수 있는 데이터베이스를 선택한다. "Yes"를 선택한 데이터베이스만 호스트 탐색 트리에 출력된다.
- DB 계정: 추가 중인 CUBRID 매니저 사용자가 해당 데이터베이스에 접속할 때 사용하는 데이터베이스 계정 정보를 입력한다. "dba" 또는 "public"과 같은 값을 입력할 수 있다.
- 브로커 주소: 해당 데이터베이스에 접속하기 위해 사용할 브로커 주소를 입력한다. 기본값은 데이터베이스 서버의 주소와 동일하다. 브로커 서버가 분리되어 있다면 이 값을 변경하여 접속 정보를 부여할 수 있다.
- 브로커 포트: 추가 중인 CUBRID 매니저 사용자가 해당 데이터베이스에 접속할 때 사용할 브로커 포트를 정의한다. 브로커 포트는 현재 정의되어 있는 브로커 정보를 통해서 선택할 수 있다. 브로커 정보는 브로커 이름/포트/구동상태로 구성되어 있다.
CUBRID 매니저 사용자 편집¶
도구 > CM 관리자 편집 > 편집 버튼
편집할 CUBRID 매니저 사용자를 리스트에서 선택한 후, 사용자 추가와 동일한 방법으로 사용자를 편집할 수 있다. 단, admin 계정에 대한 편집은 비밀번호만 변경할 수 있으며, 나머지 권한은 admin 권한에서 다른 권한으로 변경할 수 없다.
CUBRID 매니저 사용자 삭제¶
도구 > DB 사용자 생성 > 사용자 권한 정보 탭
삭제할 CUBRID 매니저 사용자를 리스트에서 선택한 후 "삭제" 버튼을 클릭하면 사용자를 삭제할 수 있다. 단, admin 계정은 삭제할 수 없다.
데이터 이전하기¶
가져오기 마법사¶
CUBRID 매니저는 스키마, 데이터를 파일로부터 데이터베이스 서버로 가져오기(import)를 지원한다. 스키마는 SQL 파일만 지원하며, 데이터는 SQL, CSV, XLS, TXT를 지원한다.
좌측 탐색 창에서 데이터를 가져올 데이터베이스의 이름을 마우스 우클릭 > 가져오기
가져오기 마법사를 시작하기 위해서는 위의 절차에 따라 "가져오기" 메뉴를 클릭하면 된다. 단, 대상 데이터베이스에 먼저 로그인된 상태여야 "가져오기" 메뉴가 활성화된다.
가져오기 마법사를 시작하면 아래와 같은 화면을 볼 수 있다.
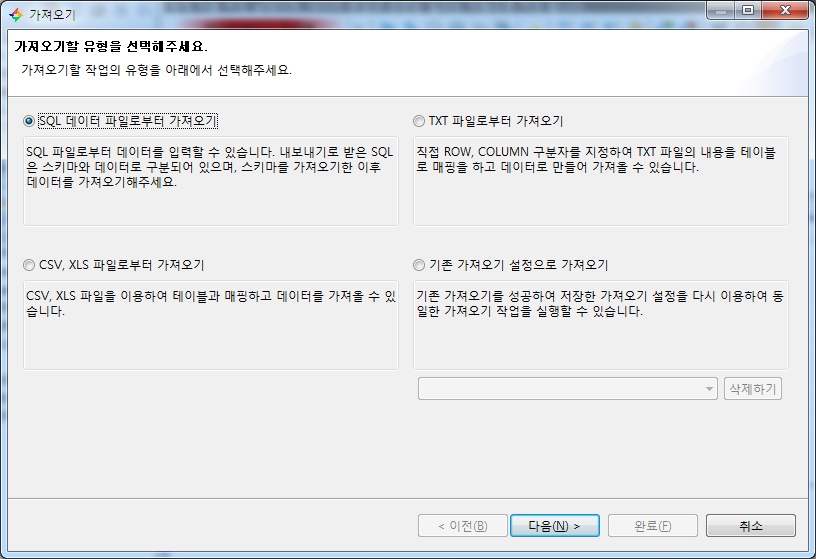
가져오기 마법사는 아래의 3단계로 구성되어 있다.
- 가져오기 유형 선택
- 가져오기할 데이터 소스 및 옵션 선택
- 가져오기 옵션 확인
가져오기 유형¶
SQL 데이터 파일로부터 가져오기¶
스키마 또는 데이터를 내보내기한 SQL 파일을 선택하여 가져오기를 할 수 있다. SQL 파일은 스키마와 데이터를 동시에 가져올 수 있으나 스키마를 가져온 후 데이터를 가져오지 않으면 스키마 없이 데이터가 입력되므로 실패할 수 있다.
CSV, XLS 파일로부터 가져오기¶
내보내기한 CSV, SQL 파일을 선택하여 데이터 가져오기를 할 수 있다. 파일을 추가하면 파일 이름과 동일한 스키마를 자동으로 맵핑한다. 만약, 데이터베이스에 없는 스키마라면, "원본 파일로부터 테이블 자동 생성"을 선택하여 스키마도 자동 생성할 수 있다.
Note
XLSX 파일은 엑셀 2007부터 추가된 파일 포맷이며 CUBRID 매니저는 XLSX 파일을 지원하지 않으므로, XLSX 파일을 원본으로 하여 데이터 가져오기 작업을 수행하는 경우 정상적인 데이터 입력을 보장할 수 없다. 따라서, XLSX 파일은 "다른 이름으로 저장" 메뉴를 통해 반드시 XLS 파일로 변환한 후에 사용하도록 한다.
TXT 파일로부터 가져오기¶
TXT로 된 데이터 파일을 행 구분자와 열 구분자를 이용하여 작성한 후 데이터베이스에 가져오기를 한다. 파일을 추가하면 파일이름과 동일한 스키마를 자동으로 맵핑한다.
데이터베이스에 없는 스키마라면, "원본 파일로부터 테이블 자동 생성"을 선택하여 스키마도 자동 생성할 수 있다.
tbl이라는 테이블이 이미 존재할 때 데이터 파일 이름은 tbl.TXT이 된다. 데이터 파일 이름이 테이블 이름과 동일하지 않으면 가져오기할 테이블 이름을 더블클릭한 후 해당 데이터 파일을 선택하면 된다.
기존 가져오기 설정으로 가져오기¶
가져오기를 완료한 후 결과 화면 하단의 "저장 및 닫기" 버튼을 클릭하면 가져오기 설정을 저장하며, 이후 "기존 가져오기 설정으로 가져오기" 옵션을 선택하면 동일한 조건으로 가져오기를 반복할 수 있다.
이 옵션을 선택할 때, 이 옵션 아래 있는 드롭다운 메뉴에서 설정 정보를 데이터베이스 이름에 맞게 주의해서 선택해야 한다.
가져오기 옵션¶
아래의 옵션은 모든 가져오기 유형에서 볼 수 있다.
- 동시 작업 수: 가져오기할 테이블이 여러개일 경우 동시작업 수를 1 이상으로 하면 좀 더 빠르게 가져올 수 있다. PC 성능에 따라 다르나 일반적인 환경에서는 1 ~ 3개가 적당하다.
- 커밋 단위: 대량의 데이터를 가져오기할 경우 데이터베이스에 트랜젝션이 길어지고 변경로그가 쌓이게되면, 데이터베이스 입력이 느려지기 때문에 주기적으로 커밋하는 것을 권한다. 보통 1000으로 사용하며, 환경에 따라 그 이상의 값을 설정할 수 있다.
내보내기 마법사¶
CUBRID 매니저는 스키마, 데이터를 데이터베이스 서버에서 파일로 내보내기(export)를 지원한다. 스키마는 SQL 파일만 지원하며, 데이터는 SQL, CSV, XLS, TXT를 지원한다.
내보내기 마법사를 시작하려면 아래의 순서대로 메뉴를 따라가면 된다.
좌측 탐색 창에서 데이터를 내보낼 데이터베이스의 이름을 마우스 우클릭 > 내보내기
내보내기 마법사를 시작하면 아래와 같은 화면을 볼 수 있다.
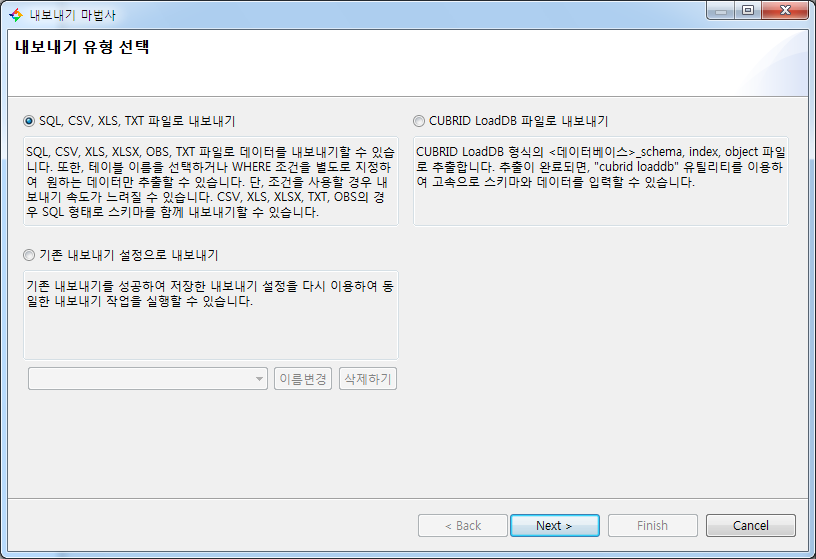
내보내기 마법사는 아래의 3단계로 구성되어 있다.
- 내보내기 유형 선택
- 내보내기할 테이블 및 옵션 선택
- 내보내기 옵션 확인
내보내기 유형¶
SQL, CSV, XLS, TXT 파일로 내보내기¶
SQL, CSV, XLS, XLSX, TXT, OBS 등 다양한 형태의 데이터 파일로 내보내기를 할 수 있다.
내보내기 대상으로 스키마를 선택하면 스키마 정보, 인덱스, 시리얼, 뷰 등도 별도의 SQL 파일로 출력할 폴더의 ddl이라는 폴더로 출력된다. 원본 테이블을 선택하여 원하는 테이블만 내보낼 수 있으며, 조건(WHERE) 항목에 SQL의 WHERE 조건을 입력하여 특정 데이터만 내보내기도 가능하다.
CUBRID LoadDB 파일로 내보내기¶
"cubrid loaddb" 명령에서 데이터를 로드하기 위해 입력하는 데이터 파일의 형식으로 내보내기를 할 수 있다. 원본 테이블을 선택하여 원하는 테이블만 내보낼 수 있으며, 조건(WHERE) 항목에 SQL의 WHERE 조건을 입력하여 특정 데이터만 내보내기도 가능하다.
저장한 내보내기 설정으로 내보내기¶
내보내기를 완료한 후 결과 화면 하단의 "저장 및 닫기" 버튼을 클릭하면 내보내기 설정을 저장하며, 이후 "저장한 내보내기 설정으로 내보내기" 옵션을 선택하면 동일한 조건으로 내보내기를 반복할 수 있다.
이 옵션을 선택할 때, 이 옵션 아래 있는 드롭다운 메뉴에서 설정 정보를 데이터베이스 이름에 맞게 주의해서 선택해야 한다.
내보내기 옵션¶
아래의 옵션은 모든 내보내기 유형에서 볼 수 있다.
- 동시작업 수: 내보내기할 테이블이 여러개일 경우 동시작업 수를 1 이상으로 하면 좀 더 빠르게 내보내기를 할 수 있다. PC 성능에 따라 다르나 일반적인 환경에서는 1 ~ 3개가 적당하다.
브로커 관리하기¶
좌측 탐색 창 > 그룹 이름 > 호스트 이름 > 브로커
브로커는 다양한 인터페이스(ODBC, OLEDB, JDBC, PHP 등)가 데이터베이스에 접속할 수 있도록 연결해 주는 연결자로서 다양한 기능을 가진다.
"브로커" 항목 하단에는 사용자가 설정한 브로커 이름이 있고, 각 브로커 이름의 하단에는 "SQL 로그" 항목이 있다.
CUBRID를 설치한 이후 브로커 설정을 변경하지 않은 상태에서는 broker1과 query_editor라는 이름의 브로커가 존재한다.
개별 브로커 기능¶
브로커는 다수의 개별 브로커로 구성될 수 있으며, 개별 브로커에는 유일한 브로커 이름, 포트, 공유 메모리 ID 등을 설정해야 한다. 각 브로커의 상태 보기와 속성 편집이 가능하며, 해당 브로커를 시작/정지할 수 있다.
SQL 로그¶
해당 브로커의 SQL_LOG 매개 변수 값이 ON이면 해당 브로커를 통해서 수행된 모든 질의는 로그 파일에 기록된다. 사용자는 이 로그 파일을 CUBRID 매니저에서 보고 분석하거나 재실행해 볼 수 있다.
로그 보기¶
좌측 탐색 창 > 호스트 이름 > 브로커 > 브로커 이름> SQL 로그 > 특정 로그 파일(마우스 우클릭) > 로그 보기
선택한 SQL 로그 파일에 기록된 SQL 로그를 100 줄씩 읽어 와서 볼 수 있는 기능으로, 로그 정보 중 특정 범위를 선택하여 복사할 수 있는 기능을 제공한다.
로그 분석¶
좌측 탐색 창 > 호스트 이름 > 브로커 > 브로커 이름> SQL 로그(마우스 우클릭) > 로그 분석
위와 같이 하면 여러 개의 로그 파일 중에서 몇 개를 선택할 수 있다.
좌측 탐색 창 > 호스트 이름 > 브로커 > 브로커 이름> SQL 로그 > 특정 로그 파일(마우스 우클릭) > 로그 분석
위와 같이 하면 특정 로그 파일을 선택한다.
"로그 분석"을 선택하면, 어떤 브로커 SQL 로그를 분석할 것인지 선택할 수 있는 "분석 파일 선택" 대화 상자가 나타난다. "트랜잭션 기반 분석"을 선택하면 트랜잭션 단위로 로그 분석을 수행하고, 체크하지 않으면 각 질의마다 로그 분석을 수행한다.
"분석 대상 파일 선택" 대화 상자에서 분석하고자 하는 SQL 로그 파일을 선택하고 "확인"을 클릭하면, 선택한 로그 파일을 분석한 결과를 보여주는 "SQL 로그 분석" 대화 상자가 나타난다.
- 로그 파일: 분석 대상이 되는 브로커 SQL 로그 파일의 이름 및 디렉터리 경로를 표시한다.
- 분석 결과: 로그 분석 결과를 보여준다. "트랜잭션 기반 분석"을 선택했다면 각 트랜잭션의 수행 시간이 표시되고, 선택하지 않았다면 각 질의별 분석 정보(전체 수행 횟수, 에러 횟수, 최고 수행 시간, 최저 수행 시간, 평균 수행 시간)가 표시된다. 결과 분석 목록의 칼럼을 클릭하면, 선택된 칼럼 값을 기준으로 분석 결과가 정렬된다.
- SQL 로그: 분석 결과에 관한 로그 내용을 보여준다.
- 실행 결과: 로그 실행 결과를 보여준다.
- 로그 실행: 로그 내용에 있는 SQL 로그를 재실행한다. 로그 질의를 변경하고 재실행하면서 질의를 튜닝하고 오류를 수정할 수 있다.
- SQL 로그 저장: 로그 내용을 파일로 저장한다.
로그 재실행¶
좌측 탐색 창 > 호스트 이름 > 브로커 > 브로커 이름> SQL 로그 > 특정 로그 파일(마우스 우클릭) > 로그 재실행
"로그 재실행" 메뉴를 선택하면, 다음과 같이 로그 재실행을 위한 환경을 설정할 수 있는 "재실행 정보" 대화 상자가 나타난다.
- 데이터베이스: 로그를 재실행할 데이터베이스를 선택한다.
- 브로커 이름: 로그를 재실행할 브로커를 선택한다.
- 사용자 ID/비밀번호: 로그를 재실행할 데이터베이스의 사용자 ID와 비밀번호를 입력한다.
- 동시 실행 개수: 동시에 실행할 로그 질의를 개수를 지정한다. 로그가 재실행될 때, 이 개수만큼의 스레드가 생성되어 같은 질의가 동시에 실행된다. 다중 사용자 환경에서 질의가 어떻게 실행되는지 확인할 때 유용한 기능이다.
- 반복 횟수: 질의의 반복 실행 횟수를 지정한다.
- 질의 실행 결과 보기: 질의 실행 결과를 확인할 수 있다.
- 질의 실행 계획 보기: 이 옵션은 "질의 실행 결과 보기"를 선택한 경우에만 유효하다.
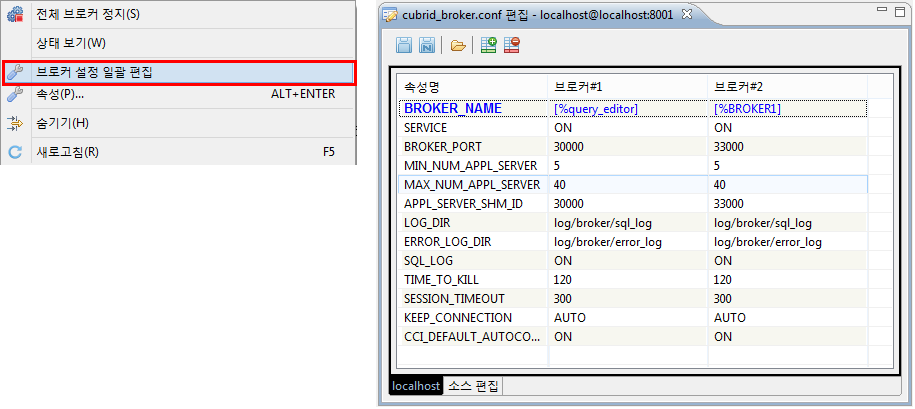
브로커 설정 일괄 편집¶
좌측 탐색 창 > 호스트 이름 > 브로커(마우스 우클릭) > 브로커 설정 일괄 편집
서비스가 복잡해지고 데이터베이스 입출력이 많아지면 브로커 또한 목적에 맞게 분리하여 사용하게 된다. 이렇게 브로커가 여러 개로 분리되는 경우 여러 브로커의 설정을 하나씩 설정하기가 어려우므로, CUBRID 매니저는 특정 서버에 있는 모든 브로커 설정을 한 화면에서 비교하면서 편집하는 기능을 제공한다.
로그¶
로그는 브로커 로그, 매니저 로그, 데이터베이스 로그로 구성되어 있다. 로그 정보를 구성하는 것은 접근 로그, 오류 로그 그리고 관리 로그로 분류해 볼 수 있다. 각 로그는 다음과 같이 구성된다.
브로커 로그¶
좌측 탐색 창 > 그룹 이름 > 호스트 이름 > 로그 > 브로커
접근 로그¶
접근 로그(access log) 파일은 응용 클라이언트 접속에 관한 정보를 기록하며, "broker_name.access"의 이름으로 저장된 것을 분석하여 출력한다. 또한, 브로커 환경 설정 파일에서 LOG_BACKUP 매개 변수가 "ON"으로 설정된 경우, 브로커의 구동이 정상적으로 종료되면 접속 로그 파일에 종료된 날짜와 시간 정보가 추가되어 로그 파일이 저장된다.
오류 로그¶
오류 로그(error log) 파일은 응용 클라이언트의 요청을 처리하는 도중에 발생된 오류에 관한 정보를 기록하며, "broker_name_app_server_num.err"의 이름으로 저장된다.
다음은 오류 로그의 예와 설명이다.
Time: 02/04/09 13:45:17.687 - SYNTAX ERROR *** ERROR CODE = -493, Tran = 1, EID = 38
Syntax: Unknown class "unknown_tbl". select * from unknown_tbl
- Time: 02/04/09 13:45:17.687 : 오류 발생 시각
- SYNTAX ERROR: 오류의 종류(SYNTAX ERROR, ERROR 등)
- *** ERROR CODE = -493: 에러 코드
- Tran = 1: 트랜잭션 ID. -1은 트랜잭션 ID를 할당받지 못한 경우.
- EID = 38: 오류 ID. SQL 문 처리 중 오류가 발생한 경우, 서버와 클라이언트 오류 로그가 관련이 있는 SQL 로그를 찾을 때 사용함.
관리 로그¶
서비스 구동 및 정지에 관한 이력을 관리한다.