Aggregate Functions¶
Overview¶
Aggregate function is used when you want to analyze data and extract some results. Aggregate function returns the grouped results and it returns only the columns which are grouped.
Below is the table which stores the sales amounts per month of each year.
CREATE TABLE sales_mon_tbl (
yyyy INT,
mm INT,
sales_sum INT
);
INSERT INTO sales_mon_tbl VALUES
(2000, 1, 1000), (2000, 2, 770), (2000, 3, 630), (2000, 4, 890),
(2000, 5, 500), (2000, 6, 900), (2000, 7, 1300), (2000, 8, 1800),
(2000, 9, 2100), (2000, 10, 1300), (2000, 11, 1500), (2000, 12, 1610),
(2001, 1, 1010), (2001, 2, 700), (2001, 3, 600), (2001, 4, 900),
(2001, 5, 1200), (2001, 6, 1400), (2001, 7, 1700), (2001, 8, 1110),
(2001, 9, 970), (2001, 10, 690), (2001, 11, 710), (2001, 12, 880),
(2002, 1, 980), (2002, 2, 750), (2002, 3, 730), (2002, 4, 980),
(2002, 5, 1110), (2002, 6, 570), (2002, 7, 1630), (2002, 8, 1890),
(2002, 9, 2120), (2002, 10, 970), (2002, 11, 420), (2002, 12, 1300);
You can get the result of the total sales amount per year by the below query.
SELECT yyyy, sum(sales_sum)
FROM sales_mon_tbl
GROUP BY yyyy;
yyyy sum(sales_sum)
=============================
2000 14300
2001 11870
2002 13450
Aggregate function returns one result based on the group of rows. When the GROUP BY clause is included, a one-row aggregate result per group is returned. When the GROUP BY clause is omitted, a one-row aggregate result for all rows is returned. The HAVING clause is used to add a condition to the query which contains the GROUP BY clause.
Most aggregate functions can use DISTINCT, UNIQUE constraints. For the GROUP BY ... HAVING clause, see GROUP BY ... HAVING Clause.
AVG¶
-
AVG( [ DISTINCT | DISTINCTROW | UNIQUE | ALL ] expression )¶ The AVG function calculates the arithmetic average of the value of an expression representing all rows. Only one expression is specified as a parameter. You can get the average without duplicates by using the DISTINCT or UNIQUE keyword in front of the expression or the average of all values by omitting the keyword or by using ALL.
Parameters: - expression -- Specifies an expression that returns a numeric value. An expression that returns a collection-type data is not allowed.
- ALL -- Calculates an average value for all data (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Calculates an average value without duplicates.
Return type: DOUBLE
The following example shows how to retrieve the average number of gold medals that Korea won in Olympics in the demodb database.
SELECT AVG(gold)
FROM participant
WHERE nation_code = 'KOR';
avg(gold)
==========================
9.600000000000000e+00
COUNT¶
-
COUNT(* | [ DISTINCT | DISTINCTROW | UNIQUE | ALL ] expression)¶ The COUNT function returns the number of rows returned by a query. If an asterisk (*) is specified, the number of all rows satisfying the condition (including the rows with the NULL value) is returned. If the DISTINCT or UNIQUE keyword is specified in front of the expression, only the number of rows that have a unique value (excluding the rows with the NULL value) is returned after duplicates have been removed. Therefore, the value returned is always an integer and NULL is never returned.
Parameters: - expression -- Specifies an expression.
- ALL -- Gets the number of rows given in the expression (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Gets the number of rows without duplicates.
Return type: INT
A column that has collection type and object domain (user-defined class) can also be specified in the expression.
The following example shows how to retrieve the number of Olympic Games that have a mascot in the demodb database.
SELECT COUNT(*)
FROM olympic
WHERE mascot IS NOT NULL;
count(*)
=============
9
GROUP_CONCAT¶
-
GROUP_CONCAT([DISTINCT] {col | expression} [ORDER BY {col | unsigned_int} [ASC | DESC]] [SEPARATOR str_val])¶ The GROUP_CONCAT function connects the values that are not NULL in the group and returns the character string in the VARCHAR type. If there are no rows of query result or there are only NULL values, NULL will be returned.
Parameters: - expression -- Column or expression returning numerical values or character strings
- str_val -- Character string to use as a separator
- DISTINCT -- Removes duplicate values from the result.
- ORDERBY -- Specifies the order of result values.
- SEPARATOR -- Specifies the separator to divide the result values. If it is omitted, the default character, comma (,) will be used as a separator.
Return type: STRING
The maximum size of the return value follows the configuration of the system parameter, group_concat_max_len. The default is 1024 bytes, the minimum value is 4 bytes and the maximum value is 33,554,432 bytes. If it exceeds the maximum value, NULL will be returned.
To remove the duplicate values, use the DISTINCT clause. The default separator for the group result values is comma (,). To represent the separator explicitly, add the character string to use as a separator in the SEPARATOR clause and after that. If you want to remove separators, enter empty strings after the SEPARATOR clause.
If the non-character string type is passed to the result character string, an error will be returned.
To use the GROUP_CONCAT function, you must meet the following conditions.
- Only one expression (or a column) is allowed for an input parameter.
- Sorting with ORDER BY is available only in the expression used as a parameter.
- The character string used as a separator allows not only character string type but also allows other types.
SELECT GROUP_CONCAT(s_name) FROM code;
group_concat(s_name)
======================
'X,W,M,B,S,G'
SELECT GROUP_CONCAT(s_name ORDER BY s_name SEPARATOR ':') FROM code;
group_concat(s_name order by s_name separator ':')
======================
'B:G:M:S:W:X'
CREATE TABLE t(i int);
INSERT INTO t VALUES (4),(2),(3),(6),(1),(5);
SELECT GROUP_CONCAT(i*2+1 ORDER BY 1 SEPARATOR '') FROM t;
group_concat(i*2+1 order by 1 separator '')
======================
'35791113'
MAX¶
-
MAX( [ DISTINCT | DISTINCTROW | UNIQUE | ALL ] expression )¶ The MAX function gets the greatest value of expressions of all rows. Only one expression is specified. For expressions that return character strings, the string that appears later in alphabetical order becomes the maximum value; for those that return numbers, the greatest value becomes the maximum value.
Parameters: - expression -- Specifies an expression that returns a numeric or string value. An expression that returns a collection-type data is not allowed.
- ALL -- Gets the maximum value for all data (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Gets the maximum value without duplicates.
Return type: same type as that the expression
The following example shows how to retrieve the maximum number of gold (gold) medals that Korea won in the Olympics in the demodb database.
SELECT MAX(gold) FROM participant WHERE nation_code = 'KOR';
max(gold)
=============
12
MIN¶
-
MIN( [ DISTINCT | DISTINCTROW | UNIQUE | ALL ] expression )¶ The MIN function gets the smallest value of expressions of all rows. Only one expression is specified. For expressions that return character strings, the string that appears earlier in alphabetical order becomes the minimum value; for those that return numbers, the smallest value becomes the minimum value.
Parameters: - expression -- Specifies an expression that returns a numeric or string value. A collection expression cannot be specified.
- ALL -- Gets the minimum value for all data (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Gets the maximum value without duplicates.
Return type: same type as that the expression
The following example shows how to retrieve the minimum number of gold (gold) medals that Korea won in the Olympics in the demodb database.
SELECT MIN(gold) FROM participant WHERE nation_code = 'KOR';
min(gold)
=============
7
STDDEV, STDDEV_POP¶
-
STDDEV( [ DISTINCT | DISTINCTROW | UNIQUE | ALL] expression )¶
-
STDDEV_POP( [ DISTINCT | DISTINCTROW | UNIQUE | ALL] expression )¶ The functions STDDEV and STDDEV_POP are used interchangeably and they return a standard variance of the values calculated for all rows. The STDDEV_POP function is a standard of the SQL:1999. Only one expression is specified as a parameter. If the DISTINCT or UNIQUE keyword is inserted before the expression, they calculate the sample standard variance after deleting duplicates; if keyword is omitted or ALL, they it calculate the sample standard variance for all values.
Parameters: - expression -- Specifies an expression that returns a numeric value.
- ALL -- Calculates the standard variance for all data (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Calculates the standard variance without duplicates.
Return type: DOUBLE
The return value is the same with the square root of its variance (the return value of VAR_POP() and it is a DOUBLE type. If there are no rows that can be used for calculating a result, NULL is returned.
The following is a formula that is applied to the function.
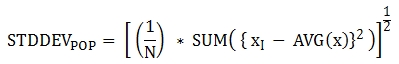
Note
In CUBRID 2008 R3.1 or earlier, the STDDEV function worked the same as the STDDEV_SAMP().
The following example shows how to output the population standard variance of all students for all subjects.
CREATE TABLE student (name VARCHAR(32), subjects_id INT, score DOUBLE);
INSERT INTO student VALUES
('Jane',1, 78), ('Jane',2, 50), ('Jane',3, 60),
('Bruce', 1, 63), ('Bruce', 2, 50), ('Bruce', 3, 80),
('Lee', 1, 85), ('Lee', 2, 88), ('Lee', 3, 93),
('Wane', 1, 32), ('Wane', 2, 42), ('Wane', 3, 99),
('Sara', 1, 17), ('Sara', 2, 55), ('Sara', 3, 43);
SELECT STDDEV_POP(score) FROM student;
stddev_pop(score)
==========================
2.329711474744362e+01
STDDEV_SAMP¶
-
STDDEV_SAMP( [ DISTINCT | DISTINCTROW | UNIQUE | ALL] expression )¶ The STDDEV_SAMP function is used as an aggregate function or an analytic function. It calculates the sample standard variance. Only one expression is specified as a parameter. If the DISTINCT or UNIQUE keyword is inserted before the expression, it calculates the sample standard variance after deleting duplicates; if a keyword is omitted or ALL, it calculates the sample standard variance for all values.
Parameters: - expression -- An expression that returns a numeric value
- ALL -- Used to calculate the standard variance for all values. It is the default value.
- DISTINCT,DISTINCTROW,UNIQUE -- Used to calculate the standard variance for the unique values without duplicates.
Return type: DOUBLE
The return value is the same as the square root of its sample variance (VAR_SAMP()) and it is a DOUBLE type. If there are no rows that can be used for calculating a result, NULL is returned.
The following are the formulas applied to the function.
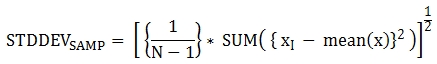
The following example shows how to output the sample standard variance of all students for all subjects.
CREATE TABLE student (name VARCHAR(32), subjects_id INT, score DOUBLE);
INSERT INTO student VALUES
('Jane',1, 78), ('Jane',2, 50), ('Jane',3, 60),
('Bruce', 1, 63), ('Bruce', 2, 50), ('Bruce', 3, 80),
('Lee', 1, 85), ('Lee', 2, 88), ('Lee', 3, 93),
('Wane', 1, 32), ('Wane', 2, 42), ('Wane', 3, 99),
('Sara', 1, 17), ('Sara', 2, 55), ('Sara', 3, 43);
SELECT STDDEV_SAMP(score) FROM student;
stddev_samp(score)
==========================
2.411480477888654e+01
SUM¶
-
SUM( [ DISTINCT | DISTINCTROW | UNIQUE | ALL ] expression )¶ The SUM function returns the sum of expressions of all rows. Only one expression is specified as a parameter. You can get the sum without duplicates by inserting the DISTINCT or UNIQUE keyword in front of the expression, or get the sum of all values by omitting the keyword or by using ALL.
Parameters: - expression -- Specifies an expression that returns a numeric value.
- ALL -- Gets the sum for all data (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Gets the sum of unique values without duplicates
Return type: same type as that the expression
The following is an example that outputs the top 10 countries and the total number of gold medals based on the sum of gold medals won in the Olympic Games in demodb.
SELECT nation_code, SUM(gold)
FROM participant
GROUP BY nation_code
ORDER BY SUM(gold) DESC
LIMIT 10;
nation_code sum(gold)
===================================
'USA' 190
'CHN' 97
'RUS' 85
'GER' 79
'URS' 55
'FRA' 53
'AUS' 52
'ITA' 48
'KOR' 48
'EUN' 45
VARIANCE, VAR_POP¶
-
VAR_POP( [ DISTINCT | UNIQUE | ALL] expression )¶
-
VARIANCE( [ DISTINCT | UNIQUE | ALL] expression )¶ The functions VARPOP and VARIANCE are used interchangeably and they return a variance of expression values for all rows. Only one expression is specified as a parameter. If the DISTINCT or UNIQUE keyword is inserted before the expression, they calculate the population variance after deleting duplicates; if the keyword is omitted or ALL, they calculate the sample population variance for all values.
Parameters: - expression -- Specifies an expression that returns a numeric value.
- ALL -- Gets the variance for all values (default).
- DISTINCT,DISTINCTROW,UNIQUE -- Gets the variance of unique values without duplicates.
Return type: DOUBLE
The return value is a DOUBLE type. If there are no rows that can be used for calculating a result, NULL will be returned.
The following is a formula that is applied to the function.
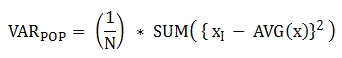
Note
In CUBRID 2008 R3.1 or earlier, the VARIANCE function worked the same as the VAR_SAMP().
The following example shows how to output the population variance of all students for all subjects
CREATE TABLE student (name VARCHAR(32), subjects_id INT, score DOUBLE);
INSERT INTO student VALUES
('Jane',1, 78), ('Jane',2, 50), ('Jane',3, 60),
('Bruce', 1, 63), ('Bruce', 2, 50), ('Bruce', 3, 80),
('Lee', 1, 85), ('Lee', 2, 88), ('Lee', 3, 93),
('Wane', 1, 32), ('Wane', 2, 42), ('Wane', 3, 99),
('Sara', 1, 17), ('Sara', 2, 55), ('Sara', 3, 43);
SELECT VAR_POP(score) FROM student;
var_pop(score)
==========================
5.427555555555550e+02
VAR_SAMP¶
-
VAR_SAMP( [ DISTINCT | UNIQUE | ALL] expression )¶ The VAR_SAMP function returns the sample variance. The denominator is the number of all rows - 1. Only one expression is specified as a parameter. If the DISTINCT or UNIQUE keyword is inserted before the expression, it calculates the sample variance after deleting duplicates and if the keyword is omitted or ALL, it calculates the sample variance for all values.
Parameters: - expression -- Specifies one expression to return the numeric.
- ALL -- Is used to calculate the sample variance of unique values without duplicates. It is the default value.
- DISTINCT,DISTINCTROW,UNIQUE -- Is used to calculate the sample variance for the unique values without duplicates.
Return type: DOUBLE
The return value is a DOUBLE type. If there are no rows that can be used for calculating a result, NULL is returned.
The following are the formulas applied to the function.
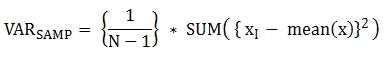
The following example shows how to output the sample variance of all students for all subjects.
CREATE TABLE student (name VARCHAR(32), subjects_id INT, score DOUBLE);
INSERT INTO student VALUES
('Jane',1, 78), ('Jane',2, 50), ('Jane',3, 60),
('Bruce', 1, 63), ('Bruce', 2, 50), ('Bruce', 3, 80),
('Lee', 1, 85), ('Lee', 2, 88), ('Lee', 3, 93),
('Wane', 1, 32), ('Wane', 2, 42), ('Wane', 3, 99),
('Sara', 1, 17), ('Sara', 2, 55), ('Sara', 3, 43);
SELECT VAR_SAMP(score) FROM student;
var_samp(score)
==========================
5.815238095238092e+02